

Void main ()
{
cout<<"main"<<endl;
func ();
}
Func.h
#include <iostream>
using namespace std;
void func ();
Заголовочные файлы – файл вставляемый в компилятор в исходный текс, в том месте где располагается директива include . Он служит для описания объявлений функций класса структуры.
Препроцессоры
Препроцессоры – программа, которая производит манипуляции с первоначальным текстом программы перед тем, как он подвергается компиляции. Команды препроцессоры называются директивами начинаются с символа #. Первая директива #include включает в исходный текст содержимое других файлов.
#define определяет символические константы и макросы
Синтаксис
#define имя заменяющая строка
#define PI=3.1415
Void main ()
{
int a=2+10+3=PI;
cout<<a;
}
Пример макрос
#define SQR (x) (x+x)
Void main ()
{
cout<<SQR(x)<<endl;
cout<<SQR("abc")<<endl;
}
#undef – отменяет предыдущее отправление файла
Директивы условной компиляции
#if условие
#dif условие
#andif условие
Условные директивы позволяют в зависимости от условия включать или исключать из компиляции части кода.
Директивы ifdef и ifndef другой способ условной компиляции (определено или не определено)
Двусвязный список
Двусвязный список – список в каждом элементе, которого хранится указатель на предыдущий и следующий элемент.
Последний элемент списка называется хвост(tail)
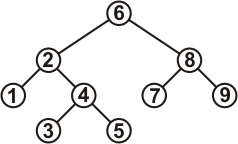
Дерево
Дерево – структурированная совокупность элементов наз. Узлами. Узлы дерева содержат данные два или более указателя связи. Первый элемент дерева называется корень. Каждый узел может ссылаться на другие узлы – называется потомками или дочерними узлами. Узлы не имеющие потомков называются листом.
Самые простые из деревьев называются бинарными деревьями. Каждый узел такого дерева может быть связан не более чем с двумя такими потомками. Бинарные деревья используются в первую очередь для поиска. Для эффективного поиска все элементы должны быть организованы особым образом.
В бинарном дерево поиска каждому элементу соответствует некоторое ключевое значение. Ключи располагаются так что для каждого элемента все ключи в левом поддереве будут меньше, а в правом поддереве больше ключи данного элемента.
Каждый элемент хранит в себе указатель на родителя данный ключ, указатель на левый и правый элемент.
Parent
Value
Kev
Left right
Parent Parent
Value Value
Kev Kev
Left right Left right
NULL NULL NULL NULL
При реализации дерева каждый его элемент, по мимо ключа и данных хранит еще 3 указателя на родителя левого и правого потока если родителя или потомка нет то указатель хранит на любое значение.
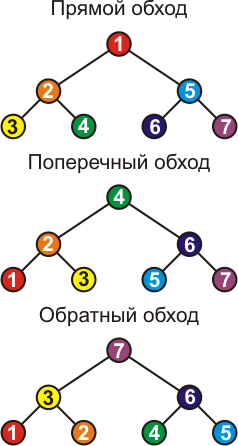
Способы обхода бинарного дерева поиска(БДП).
1)Прямой(preorder): сначала обходится данная вершина, затем левая поддеревом данная вершины, затем правая поддерево дана вершина.
2)Поперечный(inorder): сначала обходится левая поддерева данной вершины, затем данная вершина, а затем правая поддерева данной вершины. При этом вершины будут следовать порядку возрастания значений.
3)Обратный(postorder): сначала обходится левое поддерево, затем правое поддерево, а затем сама вершина
Поиск вершины с минимальным и максимальным значением вершины.
Вершины с минимальным и максимальным значением ключа можно найти пройдясь по левым или правым указателям соответственно от корня пока не достигнем значения 0.
template<typename T>
TreeNode<T>* Tree<T> :: GetMin(TreeNode<T> *node)
{
if(node != 0)
{
while(node->left != 0)
{
node = node->left;
}
}
return node;
}
Нахождение следующей и предыдущей вершины
Для нахождения предыдущей или следующей вершины необходимо учитывать 2 случая.
Рассмотрим на примере функции GetNext
Если правое поддерево не пусто, то следующим элементом будет являться минимальная вершина из правого поддерева.
Если правое поддерево пусто, тогда мы идем вверх пока не найдем вершину являющейся левым потомком своего родителя. Этот родитель и будет следующей вершиной.
template<typename T>
TreeNode<T>* Tree<T> :: GetNext(TreeNode<T> *node)
{
TreeNode<T> *nextNode = 0;
if(node != 0)
{
if(node->right != 0)//если есть правое поддерево
return GetMin(node->right);
//если правого поддерева нет
nextNode = node->parent;
while(nextNode != 0 && node == nextNode->right)
{
node = nextNode;
nextNode = nextNode->parent;
}
}
return nextNode;
}
Алгоритм добавления узла
После добавления узла в бинарное дерево поиска должно сохранять свойства упорядоченности то есть добавлять, куда попало нельзя, поэтому прежде чем добавлять узел. Для того чтобы подобрать необходимое место мы передвигаемся от корня в низ пока не добрались до листьев дерева. Если ключ вставляемой вершины меньше ключа текущей вершины, то мы передвигаемся в левое поддерево, а иначе в правое. Если в дереве нету вершин то нужно перенаправить указатели root.
template<typename T>
void Tree<T> :: Insert(const T& data, uint key)
{
TreeNode<T> *newNode = new TreeNode<T>;
newNode->data = data;
newNode->key = key;
newNode->parent = 0;
newNode->left = 0;
newNode->right = 0;
TreeNode<T> *node = root;
TreeNode<T> *parent = 0;
while(node != 0)
{
parent = node;
if(key < node->key)
node = node->left;
else
node = node->right;
}
newNode->parent = parent;
if(parent == 0)
root = newNode;
else if(key < parent->key)
parent->left = newNode;
else
parent->right = newNode;
count++;
}
Удаления узла
При удалении возможно 3 случая:
Если в удаляемой вершине нет потомка, то вершину можно просто удалить.
Если потомок один, то удаляемой вершину можно «вырезать», указав ее родителю в качестве потомка, единственный потомок удаляемой вершины
Если потомков 2, то можно сделать дополнительное действие. Необходимо найти следующую вершину за удаляемой, скопировать ее содержимое в удаляемую вершину(она теперь физически никуда не удаляется, хотя исчезает логически), и удалить физически найденную вершину.