

" " Процедура в игровых задачах
В минимаксной процедуре процесс перебора отделён от оценок позиций. Оценки производятся только после построения дерева решений. Можно добиться существенного снижения объёма перебора, если оценки вести одновременно с построением дерева решений.
После того, как найден выигрышный ход для второго игрока, процесс перебора в И-вершине можно не продолжать. Можно не продолжать раскрытие и тех И-вершин, для которых текущие оценки меньше уже полученных до этого И-вершин.
Для ИЛИ-вершин статическая оценочная функция не может увеличиваться. Не раскрываются дальше те вершины, для которых оценочная функция больше, чем уже полученная раннее оценочная функция соседней ИЛИ-вершины.
Предварительные оценочные функции для И-вершин называются a -величинами. Для вершин ИЛИ - b -величинами. Прекращение перебора в связи с нарушением неравенства называются, соответственно, a или b отсечениями. Весь процесс- a b -процедурой. Называется обратным усечением дерева решений.
Правила a b -процедуры:
1)Перебор можно прекратить ниже любой ИЛИ-вершины, для которой оценочная величина не больше, чем оценочная величина предшествующей И-вершины.
2) Можно прервать перебор ниже любой И-вершины, оценочная функция которой не меньше, чем оценочная функция предшествующей ИЛИ-вершины.
Минимаксную процедуру можно улучшить, если к обращённым величинам для И-вершин добавить фиксированное значение и эту же фиксированную величину вычесть из обращённых величин ИЛИ-вершин. При этом увеличивают оценки только тех И-вершин, в которых есть несколько хороших вершин, а уменьшают оценки тех ИЛИ-вершин, для которых есть несколько плохих порождённых вершин.
a b -процедура не приводит к потере лучших ходов, т.е. она даёт тот же результат, что и минимаксная процедура.
При построении a b -процедур, обычно используют перебор в глубину. При этом в первую очередь раскрывают лучшую вершину на каждом этапе перебора. Такая a b -процедура называется процедурой с фиксированным упорядочиванием.
Обычно в играх двух игроков применяют две формы обучения: накопление и обобщение.
Накопление заключается в хранении в памяти машины большого числа конфигураций игры вместе со статическими оценочными функциями. Если в процессе сопоставления устанавливается соответствие между положением на доске и хранимым положением, то не нужно строить дерево, оценка выполняется сразу. Для выделения наиболее встречающихся комбинаций, ведётся подсчёт обращений к ним и их список перестраивается таким образом, чтобы в начале шли наиболее встречающиеся комбинации. Если с момента последнего обращения прошло много шагов, то комбинация удаляется из списка.
Обобщение позволяет в процессе игры учитывать статическую оценочную функцию. Сложная статическая функция обычно оценивается аддитивным критерием:
S=k1a1+k2a2+…+knan
Где а1,…,аn - значения критериев; k1,…,kn - весовые коэффициенты.
В методе обобщения весовые коэффициенты ki медленно изменяются в направлении улучшения качества игры. ki обычно увеличиваются для тех критериев, значения которых больше при последних обращениях
Оценка эффективности ab -отсечения.
Эффективность a b -процедуры оценивается числом отсечённых вершин.
Пусть дерево перебора имеет глубину D, и у каждой вершины есть В порождённых вершин. Тогда дерево будет иметь BD концевых вершин. Предположим, что в a b -процедуре истинных оценок, для ИЛИ-вершин максимальное количество, а в И-вершинах - минимальное. Такой порядок максимизирует число отсечений. Тогда лучший перебор определяется числом порожденных вершин.
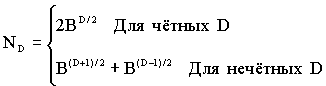
Эффективность a b - отсечений оценивается параметром n:
![]()
где N - общее число раскрытых вершин для одного хода.