

Метод Неймана
Рассмотрим случайную величину , определенную на интервале [а, в] с плотностью распределения f(х). Причем плотность распределения ограничена сверху f(х) < С . Эта плотность распределения изображена на рис. 1.5.
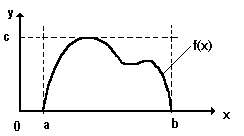
Рис. 1.5.
Теорема 3. Пусть 1 и 2 независимые, равномерно распределенные на интервале [0, 1] случайные числа. Случайная величина , определенная соотношениями = / < f ( ), где =а + 1(в-а), = С2 , имеет заданную плотность распределения f(х).
Доказательство. Пусть двумерная точка с координатами ( , ) имеет равномерное распределение в прямоугольнике, т.е. ее плотность = [c(b-a)]-1
Имеем
![]()
![]()
![]()
Рассмотрим числитель, который представляет собой вероятность одновременного выполнения двух условий: точка ( , ) окажется под кривой плотности распределения и в то же время < z :
![]()
Отсюда
![]()
Эффективность
метода Неймана равна
![]() .
.
Выбор равномерно распределенных точек в сложных областях
Пусть В - ограниченная область на плоскости х, y , “сложная” с точки зрения вычислительной практики: например, границы на отдельных участках трудно задать в явном виде. Предположим, что существует достаточно простой алгоритм, позволяющий определить, принадлежит ли области В любая заданная точка {х, y} или нет.
Выберем прямоугольник П = {а1 < х < в1, а2 < y < в2}, содержащий область В. Он изображен на рис. 1.6.
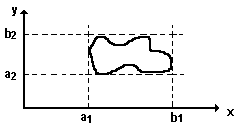
Рис. 1.6.
Координаты случайной точки Q = { , }, равномерно распределенной в прямоугольнике П, легко вычислить:
![]()
Для нахождения точек Q, равномерно распределенных в В, можно формировать точки Q , равномерно распределенные в прямоугольнике П и отбирать среди них те, которые принадлежат области В.
Эффективность
такого метода равна отношению площадей
области G и прямоугольника П
![]() .
.
1.5. Методы генерирования наиболее часто встречающихся на практике распределений.
1.5.1. Моделирование распределения Эрланга
Это распределение очень часто встречается на практике, поскольку позволяет аппроксимировать широкий класс статистических рядов, за счет того, что при изменении порядка распределения удается описать как асимметричные распределения, так и симметричные, например, нормальное.
Пусть случайная величина n описывается распределением Эрланга n-го порядка, имеющим плотность следующего вида:
![]() ,
,![]() ,
,
![]()
Распределение
Эрланга представляет собой распределение
суммы
независимых слагаемых, каждое из которых
имеет экспоненциальное распределение
с параметром
![]() .
Его моделирование сводится к получению
реализаций случайной величины, имеющей
экспоненциальное распределение с
параметром
,
и их суммированию.
.
Его моделирование сводится к получению
реализаций случайной величины, имеющей
экспоненциальное распределение с
параметром
,
и их суммированию.
Поток Эрланга может быть получен путем просеивания простейшего потока через n-1 событие поступления его требования.
1.5.2. Приближенное моделирование нормально распределенных случайных величин
Основано на использовании центральной предельной теоремы теории вероятности, утверждающей, что сумма большого числа независимых, одинаково распределенных случайных величин с конечным математическим ожиданием и дисперсией, асимптотически распределена нормально.
Будем считать, что в качестве исходных используются равномерно распределенные на интервале [0, 1] независимые случайные числа 1, 2 , . . . n. Математическое ожидание и дисперсия случайных чисел равны
![]()
Введем в рассмотрение случайную величину i , выполнив операции центрирования и нормирования:
![]() .
.
Определим случайную величину n следующим образом:
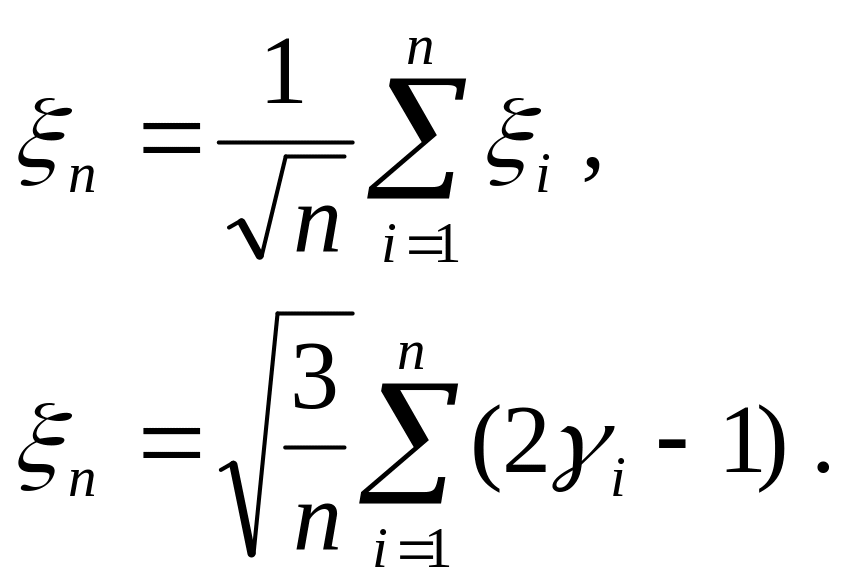
Закон распределения
случайной величины n при
![]() будет асимптотически нормальным с
параметрами m
= 0,
= 1.
будет асимптотически нормальным с
параметрами m
= 0,
= 1.
Варьируя числом слагаемых n в формуле (3.13) осуществляется приближенное моделирование нормально распределенных случайных величин.
В частном случае
при n =12 имеем
![]() .
.
Поскольку при моделировании на ЭВМ используются псевдослучайные числа, то возможны ситуации ухудшения качества формирумой последовательности случайных величин. Поэтому выбор числа слагаемых n представляет собой отдельную задачу построения качественного датчика нормально распределенных случайных величин.
Для того, чтобы получить нормально распределенные случайные величины с заданными параметрами { m , }, поступают следующим образом:
![]()
Следует отметить, что задача моделирования нормально распределенных случайных величин часто встречается на практике, поэтому при построении датчика целесообразно проанализировать все методы и выбирать тот, который обеспечивает наиболее качественную последовательность случайных чисел.