

1.4. Методы генерирования случайных событий, дискретных и непрерывных случайных величин, многомерных случайных величин, усеченных случайных величин.
1.4.1. Моделирование дискретных случайных величин
Будем считать, что задана дискретная случайная величина , представленная рядом распределения.
Для моделирования значений дискретной случайной величины разделим единичный интервал [0; 1] на n непересекающихся отрезков длиной i = pi (см.рис. 3.1).
Предположим, что в нашем распоряжении имеется совокупность случайных чисел 1, 2, . . . N , являющихся выборкой равномерно распределенной на интервале [0; 1] случайной величины .
Выбирая очередное значение j и проверяя, в какой из интервалов i это значение попадает (см. рис. 3.1), по номеру i интервала разбиения определяется конкретное значение случайной величины .
1 2 3 4 5 n
0 1
Рис.1.3.
Теорема 1. Случайная величина , определенная соотношением (1.4.1)
= хi , если i , (1.4.1)
имеет заданный закон распределения, представленный в виде ряда распределения
-
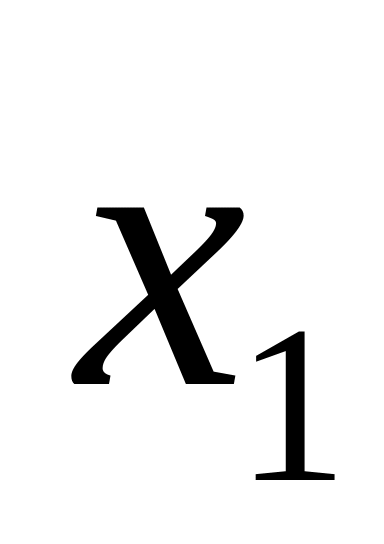
…
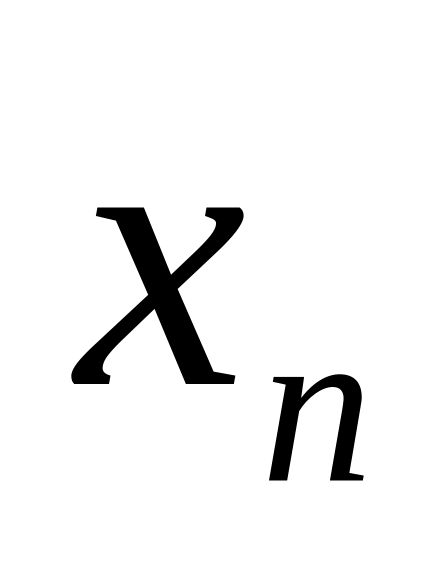
р
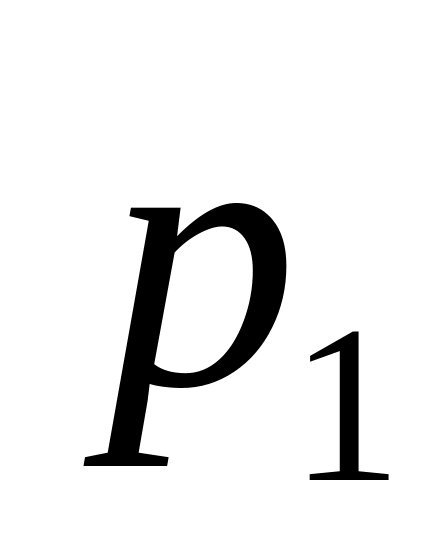
…
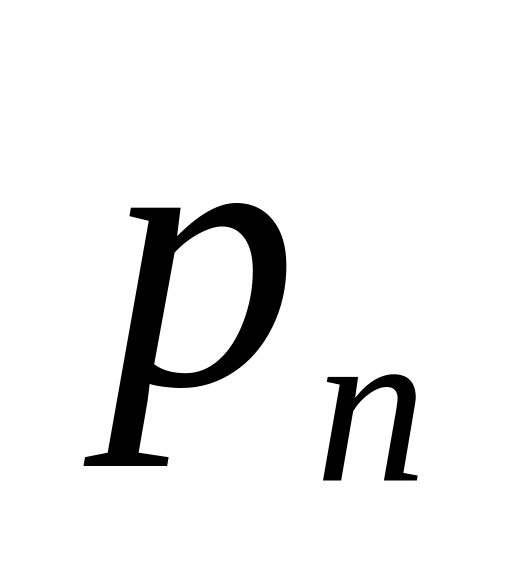
Доказательство. Рассмотрим вероятности:
Р { = xi} = P { i} = длина i = pi ,
что и требовалось доказать.
Для того, чтобы проверить какому интервалу разбиения i принадлежит случайное число , в памяти ЭВМ подряд располагаются значения х1, х2, х3, . . . хn и значения р1, р1+ р2, р1+ р2+ р3, . . . 1 .
Формируя число , его сначала сравнивают с р1; если < p1 , то = х1 .
Если это условие
не выполняется, то
сравнивается с р1
+ р2
. При условии, что
![]()
< р1
+ р2
, то
= х2.
Если и это условие не выполняется, то
сравнивают с р1
+ р2 +
р3
и т.д.
< р1
+ р2
, то
= х2.
Если и это условие не выполняется, то
сравнивают с р1
+ р2 +
р3
и т.д.
Возникает вопрос, каким образом располагать значения вероятностей в памяти ЭВМ, чтобы количество сравнений было минимальным.
В том случае, когда = хi (1 < i < n-1) , количество сравнений, необходимое для определения значения , равно i . И только когда = хn , количество сравнений будет равно n - 1.
Следовательно, среднее количество t сравнений, необходимое для определения значения величины :
![]() (
1.4.2 )
(
1.4.2 )
Величина t будет минимальной, если расположить значения pi в порядке убывания соответствующих вероятностей p1 p2 p3 . . . pn .
Моделирование случайных событий проводится на основе схемы моделирования дискретных случайных величин.
Моделирование отдельного случайного события
В соответствии с доказанной выше теоремой для проведения каждого испытания необходимо сформировать число и проверить условие : < pА. Если это условие выполняется, то наступило событие А, если не выполняется, то наступило событие А.
Моделирование полной группы случайных событий
События А1, А2, . . . Аn составляют полную группу с вероятностями р1, р2, . . . , рn . Введем в рассмотрение дискретную случайную величину , имеющую смысл номера события полной группы:
В соответствии с доказанной выше теоремой формируются числа , проверяется в какой из интервалов i они попадают. Номер этого интервала определяет индекс события Аi .
Моделирование совместных независимых событий
Пусть заданы совместные независимые события А и В. Известны вероятности наступления событий РА и РВ, соответственно.
Моделирование указанных событий может осуществляться двумя способами:
1. С использованием двух случайных чисел 1 и 2 .
С помощью числа
1
проверяется
условие: 1
< рА
. Если условие выполняется, то считается,
что наступило событие А. В противном
случае -
![]() .
.
С помощью числа
2
проверяется условие 2
< pВ
. При выполнении условия наступило
событие В, в противном случае
![]() .
.
Недостаток данного способа моделирования заключается в том, что при использовании двух чисел 1 и 2 возрастают затраты машинного времени, связанные с обращениями к датчикам .
2. С использованием одного числа , но предполагающее некоторую предварительную подготовку.
Определяется
полная группа событий:
![]() и соответствующий ей ряд распределения
:
и соответствующий ей ряд распределения
:
-
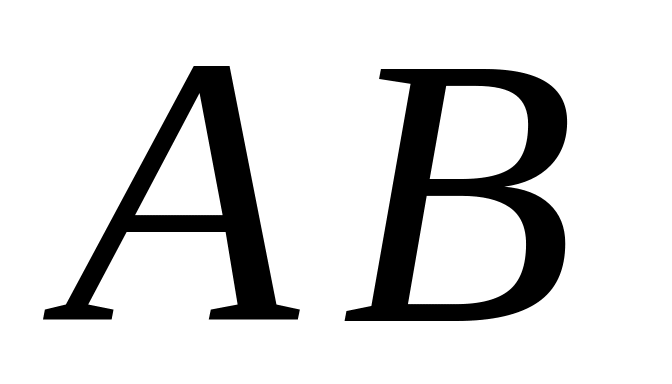
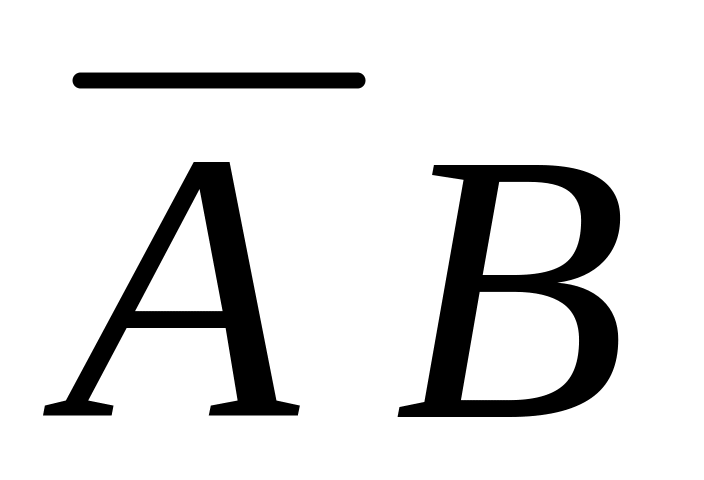
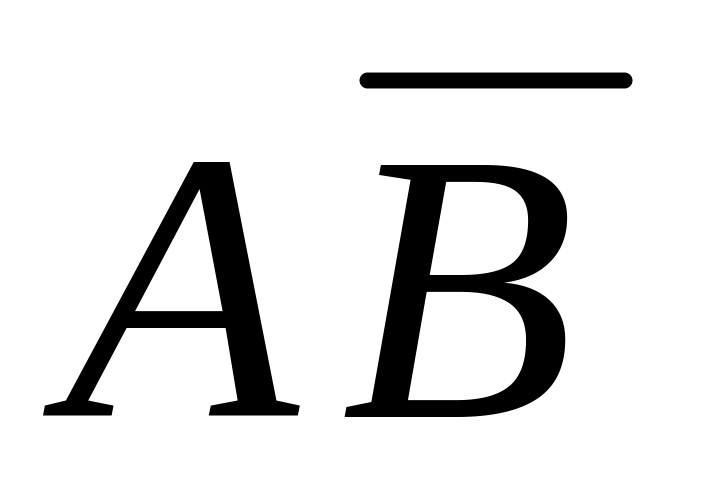
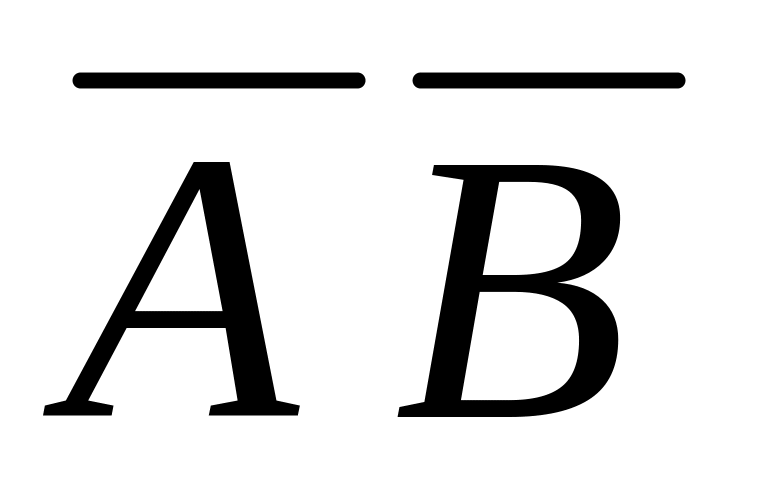
р
рАрВ
(1-рА)рВ
рА(1-рВ)
(1-рА)(1-рВ)
Получив ряд распределения, моделирование сводится к ранее рассмотренной схеме моделирования полной группы событий.
Моделирование совместных зависимых событий.
В качестве исходной информации используются вероятности РА , РВ , РАВ .
Моделирование также может осуществляться двумя способами:
1. С использованием двух чисел 1 и 2 .
По числу 1 проверяется наступление события А. Если А наступило, то по условной вероятности Р (В/А) с помощью числа 2 определяется, наступило ли событие В - 2 < р (В/А) .
Если событие А не
наступило, то наступление события В
проверяется с помощью условной вероятности
![]() .
.
2. Моделирование осуществляется с использованием одного числа по рассмотренной выше схеме моделирования полной группы событий, вероятности которых вычисляется следующим образом:
-
р
рАВ
рА - рАВ
рВ - рАВ
1 -рА - рВ + рАВ