

4.5. Предсказание
Предположим, что вы оценили модель
 (11.50)
(11.50)
на выборке из Т наблюдений временною ряда (t= 1,..., Т):
 (11.51)
(11.51)
Имея некоторое послевыборочное значение переменной X, например ХT+р, вы можете предсказать соответствующее значение У:
 (11.52)
(11.52)
Такие предсказания могут быть важными по двум причинам. Во-первых, вы можете быть одним из тех эконометристов, чья работа — заглядывать в экономическое будущее. Некоторые эконометристы изучают экономические закономерности с целью улучшить наше понимание того, как работает экономика, но для других это является лишь средством достижения более практичной цели — предвидеть, что может случиться. Во многих странах макроэкономическое прогнозирование имеет высокую репутацию, и коллективы эконометристов поддерживаются министерствами финансов или другими правительственными органами, частными финансовыми учреждениями, университетами и исследовательскими институтами, и их предсказания активно используются для формирования и обсуждения государственной политики или в деловых целях. Когда подобные предсказания публикуются в печати, они, как правило, привлекают гораздо больше внимания, чем большинство других видов экономического анализа, в основном благодаря своей сути и тому, что в отличие от большинства других видов экономического анализа они легко могут быть поняты средним гражданином. Даже человек с совершенно нематематическим и нетехническим складом ума в состоянии понять, что подразумевается под оценками будущего уровня безработицы, инфляции и т.д.
Есть, однако, и другое применение эконометрического предсказания, которое делает его предметом заботы большинства эконометристов независимо от того, заняты они прогнозированием или нет. Оно дает метод оценки устойчивости регрессионной модели, который имеет большую исследовательскую направленность, чем диагностические статистики, использовавшиеся до сих пор.
Прежде чем двигаться дальше, необходимо уточнить, что мы понимаем под предсказанием. К сожалению, в эконометрической литературе этот термин может иметь несколько различных значений, в соответствии с пониманием ХT+p в модели (11 52). Мы будем различать предсказания (ex post predictions) и прогнозы (forecasts). Это разделение сделано в соответствии с обычным использованием терминов, но, тем не менее, применяемая здесь терминология не вполне стандартная.
Предсказания
Мы опишем
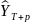 как предсказание, если значение
XT+p
известно. Как это возможно? В общем
случае эконометристы хотят включить
все имеющиеся данные в свою выборку для
максимизации ее размера и, как следствие,
для минимизации дисперсии оценок,
поэтому XT
является последним зафиксированным
значением X на момент
оценки регрессии. Тем не менее, возможны
две ситуации, когда
ХT+p
известны: когда вы ждете
р или больше периодов после
оценки регрессии или когда вы заранее
ограничили период выборки так, чтобы
у вас остались несколько последних
наблюдений. Как мы увидим в следующем
подразделе, весомой причиной так
поступать может стать возможность без
задержки оценить прогнозную точность
модели.
как предсказание, если значение
XT+p
известно. Как это возможно? В общем
случае эконометристы хотят включить
все имеющиеся данные в свою выборку для
максимизации ее размера и, как следствие,
для минимизации дисперсии оценок,
поэтому XT
является последним зафиксированным
значением X на момент
оценки регрессии. Тем не менее, возможны
две ситуации, когда
ХT+p
известны: когда вы ждете
р или больше периодов после
оценки регрессии или когда вы заранее
ограничили период выборки так, чтобы
у вас остались несколько последних
наблюдений. Как мы увидим в следующем
подразделе, весомой причиной так
поступать может стать возможность без
задержки оценить прогнозную точность
модели.
Так, например, обращаясь снова к уравнению (3.39) модели связи общей инфляции и инфляции зарплаты, предположим, что для всего периода выборки мы оценили уравнение
 (11.53)
(11.53)
где р и w — годовой уровень общей инфляции и инфляции зарплаты (в процентах) соответственно, и что мы знаем, что в один послевыборочный год уровень инфляции зарплаты составлял 6%. Тогда мы можем утверждать, что предсказанный уровень общей инфляции равен 5,8%. Мы, конечно, должны иметь возможность сразу сравнить его с действительным уровнем инфляции в этом году и рассчитать ошибку предсказания, которая равна разности между предсказанным и действительным значением В общем случае, если YT +р — действительное значение, а - предсказываемое, то ошибка предсказания fT+p определяется как
 (11.54)
(11.54)
Почему появляется ошибка предсказания? Это происходит по двум причинам. Во-первых, значение - было рассчитано с помощью оценок параметров b1 и b2, вместо их реальных значений. Во-вторых, - не учитывает воздействие случайного члена иT+ р, являющегося составной частью YT+p. В дальнейшем мы будем предполагать, что данные включают (T+р) наблюдений переменных, из них первые Т наблюдений (период выборки) используются для построения регрессии, а последние р (период, или интервал предсказания) используются для анализа точности предсказания.
Пример
Предположим, что, когда мы оценивали функцию спроса на жилье по набору данных для оценивания функций спроса, мы использовали лишь первое 41 наблюдение из выборки, т.е. данные за 1959—1999 гг., оставив последние четыре наблюдения для анализа предсказаний. Полученное на выборке 1959-1999 гг. уравнение выглядит следующим образом (в скобках приведены стандартные ошибки):
 (11.55)
(11.55)
Значения LGHOUS для периода 2000—2003 гг., предсказанные с помощью этого уравнения, при использовании действительных значений личного располагаемого дохода и относительных цен жилья в эти годы, показаны в табл. 11.6 вместе с фактическими значениями этой переменной и ошибками предсказания. Предсказания, как и исходные данные, приведены в логарифмической шкале. Для удобства в табл. 11.6 показаны также абсолютные значения (в млрд. долл.) в ценах 2000 г., которые могут быть рассчитаны на основе логарифмических значений.
Таблица 11.6. Предсказанные и фактические расходы на жилье в 2000-2003 гг.
|
|
Логарифмы |
|
Абсолютные значения |
||
Год |
LGHOUS |
|
Ошибка |
HOUS |
|
Ошибка |
2000 |
6,914 |
6,956 |
-0,042 |
1006 |
1049 |
-43 |
2001 |
6,941 |
6 963 |
-0,027 |
1034 |
1063 |
-29 |
2002 |
6,968 |
6 990 |
-0,022 |
1062 |
1086 |
-24 |
2003 |
6 981 |
7,012 |
-0,030 |
1076 |
1109 |
-33 |


Мы можем видеть, что в этом случае предсказанные значения расходов на жилье превосходят фактические значения на 2,2—4,2%. Может ли такое предсказание считаться удовлетворительным? Мы обсудим эго в следующем разделе.
Прогнозы
Если вы хотите предсказать конкретное значение УT+p , не зная действительное значение ХT+p, то считается, что вы делаете прогноз (по крайней мере, если использовать терминологию этого текста). Макроэкономические предвидения, публикуемые в прессе, обычно являются в этом смысле прогнозами. Политиков, а в особенности широкую публику, мало интересуют «двусторонние» экономисты, рассуждения которых имеют вид «с одной стороны..., но если нет, то с другой стороны...». Обычно все желают точных однозначных оценок, дополненных, может быть, границами возможной ошибки, но часто даже и без этого. Прогнозы менее точны, чем предсказания, поскольку они подвержены воздействию дополнительного источника ошибки — предсказания значения ХT+p . Очевидно, что делающий прогноз эконометрист пытается, как правило, минимизировать эту дополнительную ошибку, моделируя как можно более точно поведение переменной X. Иногда для нее строят отдельную модель, иногда совмещают в одну модель уравнение для Y и уравнение для X, дополняя их множеством других соотношений и оценивая получающуюся систему одновременных уравнений (что рассматривалось в гл. 9).
Свойства предсказаний, полученных с помощью МНК
В последующих рассуждениях мы сосредоточимся в основном на предсказаниях, а не на прогнозах, и обсудим свойства коэффициентов уравнения регрессии и свойства случайного члена, а не переменной X в случае, когда ее значения неизвестны. И в этом есть положительные моменты. Если значение YT+p порождается тем же процессом, что и выборочные значения переменной Y (т.е. в соответствии с уравнением (11.50), где uT+p удовлетворяет предпосылкам регрессионной модели, и если мы строим наше предсказание YT+p с помощью уравнения (11.52), то ошибка предсказания fT+p будет иметь нулевое математическое ожидание и минимальную дисперсию. Первое свойство легко продемонстрировать:


 (11.56)
(11.56)
поскольку Е(b1) = β1, Е(b2)= β2 и Е(иT+р) = 0. Мы не будем доказывать свойство минимума дисперсии. Доказательство можно найти у Дж. Джонстона и Дж. Динардо (Jonston, Dinardo. 1997). Оба эти свойства сохраняются и для общего случая множественного регрессионного анализа.
В случае уравнения парной регрессии теоретическая дисперсия fT+p определяется как
 (11.57)
(11.57)
где
и
 – соответственно выборочное среднее
значение и сумма квадратов отклонений
переменной X. Из формулы следует, и это
неудивительно, что чем больше значение
X отклоняется от выборочного среднего,
тем больше теоретическая дисперсия
ошибки предсказания. Из формулы так же
следует, и это вновь неудивительно, что
чем больше объем выборки, тем меньше
теоретическая дисперсия ошибки
предсказания с нижним пределом,
равным
.
С ростом объема выборки оценки b1,
и b2 стремятся к
истинным значениям соответствующих
коэффициентов (в случае выполнения
предпосылок модели), и единственным
источником ошибки при предсказании
будет случайный член uT+р,
а он по определению имеет дисперсию
.
– соответственно выборочное среднее
значение и сумма квадратов отклонений
переменной X. Из формулы следует, и это
неудивительно, что чем больше значение
X отклоняется от выборочного среднего,
тем больше теоретическая дисперсия
ошибки предсказания. Из формулы так же
следует, и это вновь неудивительно, что
чем больше объем выборки, тем меньше
теоретическая дисперсия ошибки
предсказания с нижним пределом,
равным
.
С ростом объема выборки оценки b1,
и b2 стремятся к
истинным значениям соответствующих
коэффициентов (в случае выполнения
предпосылок модели), и единственным
источником ошибки при предсказании
будет случайный член uT+р,
а он по определению имеет дисперсию
.
Доверительные интервалы для предсказаний
Мы можем
получить значение стандартного отклонения
для ошибки предсказания, если заменим
в уравнении (11.57) на
 и извлечем квадратный корень. Тогда
отношение величины (YT+p
-
и извлечем квадратный корень. Тогда
отношение величины (YT+p
-
 )
к стандартной ошибке при оценивании
уравнения для периода выборки будет
подчиняться t-распределению
с числом степеней свободы
(Т- к). Отсюда мы можем
получить доверительный интервал для
действительного значения YT+p:
)
к стандартной ошибке при оценивании
уравнения для периода выборки будет
подчиняться t-распределению
с числом степеней свободы
(Т- к). Отсюда мы можем
получить доверительный интервал для
действительного значения YT+p:
 (11.58)
(11.58)
где tкрит — критическое значение t при заданных уровне значимости и числе степеней свободе, а с.о. — стандартная ошибка предсказания. На рис. 11.3 в общем виде показано соотношение между доверительным интервалом для предсказания и значением объясняющей переменной.
Пример
В табл. 11.7 представлены результаты оценивания логарифмической регрессии расходов на жилье на показатели дохода и относительных цен,
Таблица 11.7
Dependent Variable LGHOUS
Method: Least Squares
Sample: 1959 2003
Included observations 45
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
С |
-0.298460 |
0.194922 |
-1.531173 |
0.1340 |
LGDPI |
1.036576 |
0.006497 |
159. 5366 |
0.0000 |
LGPRHOUS |
-0.423765 |
0.045451 |
-9.323628 |
0.0000 |
D00 |
-0.041629 |
0.017210 |
-2.418867 |
0.0205 |
D01 |
-0.027473 |
0.017436 |
-1.575655 |
0.1234 |
D02 |
-0.022256 |
0.017788 |
-1.251167 |
0.2185 |
D03 |
-0.030428 |
0.017893 |
-1.700556 |
0.0072 |
R-squared |
0. 998852 |
|
Mean dependent var |
6. 359334 |
Adjusted R-squared |
0 .998670 |
|
S.D. dependent var |
0.437527 |
S.E of regression |
0. 015955 |
|
Akaike info enter |
-5.296084 |
Sum squared resid |
0. 0096 73 |
|
Schwarz criterion |
-5.015048 |
Log likelihood |
12 6.1619 |
|
F-statistic |
5508. 485 |
Durbin-Watson stat |
0 802456 |
|
Prob(F-statistic) |
0.000000 |
с фиктивными переменными D00—D03 для 2000—2003 гг. Коэффициенты при фиктивных переменных показывают ошибки предсказания, указанные в табл. 11.6. Предсказанный логарифм расходов на жилье в 2000 г в табл. 11.6 равняется 6,956. Из распечатки регрессии видно, что стандартная ошибка предсказания для этого года составляет 0,017. Для 38 степеней свободы критическое значение t-статистики при 5%-ном уровне значимости равно 2,024, и мы получаем следующий 95%-ный доверительный интервал предсказания для данного года:
6,956 - 2,024 х 0,017 < Y< 6,956 + 2,024 х 0,017, (11.59)
то есть
6,922 < Y< 6,990. (11.60)
Доверительный интервал не включает фактическое значение (6,914), и, таким образом, по крайней мере, для этого года предсказание оказалось неудовлетворительным. Очевидное объяснение этому состоит в том, что мы использовали очень простую статическую модель для оценки расходов на жилье. Как мы убедимся в следующей главе, динамическая модель является более предпочтительной.