

3.5. Качество оценивания: коэффициент r2
Как и в парном регрессионном анализе, коэффициент детерминации определяет долю дисперсии Y, объясненную регрессией, и определяется как
 (3.57)
(3.57)
а также как
 (3.58)
(3.58)
или как квадрат коэффициента корреляции Y и . Этот коэффициент никогда не уменьшается (а обычно увеличивается) при добавлении еще одной переменной в уравнение регрессии, если все ранее включенные объясняющие переменные сохраняются. Для иллюстрации этого предположим, что вы оцениваете регрессию Y на Х2 и Х3 и получаете уравнение вида
 (3.59)
(3.59)
Далее, предположим, что вы оцениваете регрессию Y только на Х2, в результате получив следующее уравнение:
 (3.60)
(3.60)
Это уравнение можно переписать:
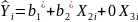 (3.61)
(3.61)
Если сравнить уравнения (3.59) и (3.61), то коэффициенты в первом из них свободно определялись с помощью метода наименьших квадратов на основе данных для Y, Х2 и Х3 при обеспечении наилучшего качества оценки. Однако в уравнении (3.61) коэффициент Х был произвольно установлен равным нулю. И оценивание не будет оптимальным, если только по случайному совпадение величина b3 не будет равна нулю, когда оценки будут такими же (в этом случае величина b* 1 будет равна Ь1, а величина Ь2* будет равна Ь2). Следовательно, обычно уровень коэффициента R2 будет выше в уравнении (3.59), чем в уравнении (3.61), и он никогда не станет ниже. Конечно, если новая переменная на самом деле не относится к этому уравнению, то увеличение коэффициента R2 будет, вероятно, незначительным.
Вы можете решить, что поскольку коэффициент R2 измеряет долю дисперсии, совместно объясненной независимыми переменными, то можно определить отдельный вклад каждой независимой переменной и таким образом получить меру ее относительной важности. Это было бы очень удобно, если бы можно было так сделать. К сожалению, такое разложение невозможно, если независимые переменные коррелированны, поскольку их объясняющая способность будет перекрываться. Эта проблема рассматривается в разделе 6.2.
F- тесты
В разделе 2.11 F-тест использовался для проверки объясняющей способности модели парной регрессии:
(3.62)
где в качестве нулевой рассматривалась гипотеза Н0: β2 = 0, а в качестве альтернативной — гипотеза Н1: β2 ≠ 0. Нулевая гипотеза — та же самая, что и при выполнении t-теста для коэффициента наклона; выяснилось, что F-тест эквивалентен двустороннему t-тесту. Однако в случае множественной регрессии эти тесты выполняют разные функции: t-тесты проверяют значимость коэффициента при каждой переменной по отдельности, в то время как F'-тест проверяет их совместную объясняющую способность. Нулевая гипотеза, которую мы надеемся отвергнуть, заключается в том, что модель не обладает никакой объясняющей способностью. Модель не обладает объясняющей способностью, если выясняется, что Y не связана ни с одной из объясняющих переменных. Математически, следовательно, если модель имеет вид
 (3.63)
(3.63)
то нулевая гипотеза для F-теста означает равенство всех коэффициентов β2,..., βk нулю:
H0:β2=…=βk=0 (3.64)
Альтернативная гипотеза Н1 заключается в том, что по крайней мере один из коэффициентов β2,..., βk отличен от нуля, F-статистика записывается как
 (3.65)
(3.65)
и тест выполняется путем сравнения этой величины с критическим уровнем F, приведенным в столбце, соответствующем k-1 степеням свободы, и строке, соответствующей п - к степеням свободы, в соответствующей части табл. А.З в Приложении А.
Данная F-статистика может быть также выражена в терминах R2 путем деления числителя и знаменателя в (3.65) на TSS, общую сумму квадратов отклонений, имея в виду, что ESS/TSS равно R2 и RSS/TSS равно (1 - R2):
 (3.66)
(3.66)
Пример
Иллюстрацией может служить модель продолжительности обучения. Предположим, что переменная S зависит от ASVABC, SM и SF:
(3.67)
Нулевая гипотеза для F-теста на общее качество уравнения состоит в том, что все три коэффициента наклона равны нулю:
H0: β2 = β3= β4=0 (3.68)
Альтернативная гипотеза состоит в том, что, по крайней мере, один из этих коэффициентов не равен нулю. В табл. 3.12 приведена распечатка результатом оценивания регрессии по набору данных EAEF21.
В этом примере число объясняющих переменных к - 1 равно 3, и число степеней свободы п - к равно 536. Числитель F-статистики есть объясненная сумма квадратов отклонений, деленная на к- 1. В распечатке программы Stata эти числа (1181,4 и 3 соответственно) приведены в строке Model. Знаменатель здесь есть сумма квадратов остатков, деленная на остающееся число степеней свободы (2023,6 и 536 соответственно). Следовательно, F-статистика равна
 (3.69)
(3.69)
как указано в распечатке. Все серьезные регрессионные пакеты рассчитывав эту F-статистику как один из элементов диагностической распечатки результатов оценивания.
Критическое значение F(3; 536) не приведено в таблицах .F-распределения. но мы знаем, что оно должно быть меньше, чем F(3; 500), которое в этих таблицах приведено. При 0,1 %-ном уровне значимости оно равно 5,51. Следовательно, мы с уверенностью отвергаем Н0 на 0,1 %-ном уровне. Этот результат мол но было ожидать, поскольку как ASVABC, так и SF имеют высоко значимы: t-статистики. Поэтому мы знали заранее, что оба коэффициента β2 и β3 не равны нулю.
Вообще говоря, F-статистика будет значимой, если значима по крайней мере одна из t-статистик. Однако в принципе F-статистика может и не быть значимой в этом случае. Предположим, что вы оценили не имеющую смысл регрессию с 40 объясняющими переменными, каждая из которых не является действительным детерминантом зависимой переменной. В этом случае F-статистика должна оказаться достаточно низкой, чтобы гипотеза Н0 не была отвергнута. Однако если вы выполните t-тесты для коэффициентов наклона на
Таблица 3.12
reg S ASVABC SM SF |
|
|
|
|
|
|
Source |
SS |
df |
MS |
|
Number of obs = |
540 |
Model |
1181.36981 |
3 |
393.789935 |
|
F(3, 536) Prob > F |
104.30 0.0000 |
Residual |
2023.61353 |
536 |
3.77539837 |
|
R-squared = Adj R-squared = |
0.3686 0.3651 |
Total
|
3204.98333 |
539 |
5.94616574 |
|
Root MSE |
1.943 |
S |
Coef. |
Std. Err. |
t |
P>|t| |
[95% Conf. |
Interval] |
ASVABC |
.1257087 |
.0098533 |
12.76 |
0.000 |
.1063528 |
.1450646 |
SM |
.0492424 |
.0390901 |
1.26 |
0.208 |
-.027546 |
.1260309 |
SF |
.1076825 |
.0309522 |
3.48 |
0.001 |
.04688 |
.1684851 |
_cons |
5.370631 |
.4882155 |
11.00 |
0.000 |
4.41158 |
6.329681 |
5%-ном уровне, с 5%-ной вероятностью ошибки I рода, то в среднем можно ожидать, что 2 из 40 переменных будут иметь «значимые» коэффициенты.
В то же время легко может случиться и так, что F-статистика будет значимой при незначимости всех t-статистик. Предположим, у вас имеется модель множественной регрессии, которая правильно специфицирована, и коэффициент детерминации R2 высок. Вероятно, в этом случае F-статистика высоко значима. Однако если объясняющие переменные сильно коррелированны и модель подвержена сильной мультиколлинеарности, то стандартные ошибки коэффициентов наклона могут оказаться столь велики, что ни одна из t-статистик не будет значима. В этом случае вы знаете, что ваша модель хороша, но у вас нет возможности выделить вклад каждой отдельно взятой переменной.
Дальнейший анализ дисперсии
Помимо проверки уравнения в целом F-тест можно использовать для определения значимости совместного предельного вклада группы переменных. Предположим, что вы сначала оцениваете регрессию
 (3.70)
(3.70)
где объясненная сумма квадратов отклонений составляет ESSk. затем вы добавляете еще (m - к) переменных и оцениваете регрессию
 (3.71)
(3.71)
где объясненная сумма квадратов отклонений равна ESSm . Таким образом, вы объяснили дополнительную величину (ESSm - ESSk), использовав для этого дополнительные (m - к) степеней свободы, и требуется понять, превышает ли данное увеличение то, которое может быть получено случайно.
Вновь используется F-тест, и соответствующая F-статистика может быть описана следующим образом:
Улучшение качества уравнения/Число использованных F= степеней свободы
Необъясненная сумма квадратов отклонений/Оставшееся число степеней свободы
(3.72)
Поскольку RSSm — необъясненная сумма квадратов отклонений в уравнении со всеми т переменными — равняется TSS-ESSm и RSSk — сумма квадратов отклонений в уравнении с к переменными — равняется TSS - ESSk, улучшение качества уравнения при добавлении (т - к) переменных, т.е. ESSm – ESSk, записывается выражением RSSk-RSSm. Следовательно, cсоответствующая F-статистика равна
 (3.73)
(3.73)
При выполнении нулевой гипотезы о том, что дополнительные переменные не увеличивают объясняющей способности уравнения
H0: βk+1 = βk+2= …= βm=0 (3.74)
эта F'-статистика распределена с (т - к) и (п - т) степенями свободы. В верхней половине табл. 3.13 проведен дисперсионный анализ объясняющей способности первоначальных k - 1 переменных. В нижней половине таблицы это сделано для совместного предельного вклада новых переменных.
Пример
Мы проиллюстрируем описанный тест с помощью функции продолжительности обучения. Таблица 3.14 показывает результат оценивания регрессии переменной S на ASVABC с использованием набора данных EAEF21. Заметим, что сумма квадратов отклонений равна здесь 2123,0.
Таблица 3.13. Анализ дисперсии, исходные переменные и группа дополнительных
переменных
Сумма Степени Сумма квадратов, деленная
квадратов свободы на число степеней свободы
F-статистика
Объяснено исходными переменными
ESSk
k-1
ESSk/(k-1)
R SSk/(k-
1) RSSk/(
n-k)
SSk/(k-
1) RSSk/(
n-k)
Остаток
RSSk=TSS-ESSk
n-k
RSSk/(n-k)
Объяснено
новыми
переменными
ESSm-ESSk = = RSSk-RSSm
m-k
(RSSk-RSSm) /(m-k)
(RSSk-RSSm) /(m-k) RSSm/ (n-m)
Остаток RSSm=TSS-ESSm n-m RSSm/(n-m)
Таблица 3.14
reg S ASVABC |
|
|
|
|
|
|
Source |
SS |
df |
MS |
|
Number of obs = |
540 |
Model |
1081.97059 |
1 |
1081.97059 |
|
F(1, 538) Prob > F |
274.19 0.0000 |
Residual |
2123.01275 |
538 |
3.94612035 |
|
R-squared = Adj R-squared = |
0.3376 0.3364 |
Total
|
3204.98333 |
539 |
5.94616574 |
|
Root MSE |
1.9865 |
S |
Coef. |
Std. Err. |
t |
P>|t| |
[95% Conf. |
Interval] |
ASVABC |
.148084 |
.0089431 |
. 16.56 |
0.000 |
.1305165 |
.1656516 |
_cons |
6.066225 |
.4672261 |
12.98 |
0.000 |
5.148413 |
5.148413 |
Теперь добавим группу из двух переменных, представляющих завершенное число лет обучения каждого из родителей респондента (табл. 3.15). Вносят ли эти переменные совместно значимый вклад в объясняющую способность модели? Можно заметить, что t-тест показывает высокую значимость коэффициента при SF, но мы все же выполним и /F-тест. Заметим, что RSS- 2023,6.
Улучшение качества регрессии после добавления «родительских» переменных представлено уменьшением суммы квадратов остатков, равным 2123,0 - 2023,6. Ценой этого является потеря двух степеней свободы, поскольку требуется оценить два дополнительных параметра. Сумма квадратов отклонений, остающаяся необъясненной после добавления SM и SF, равна 2023,6. Остающееся после добавления переменных число степеней свободы равно 540 - 4 = = 536. Отсюда
 (3.75)
(3.75)
Таким образом, F-статистика равна 13,16. Критическое значение F(2; 500) на 0,1%-ном уровне равно 7,00. Критическое значение F(2; 536) должно быть еще меньше, и поэтому мы отвергаем H0 и делаем вывод о том, что переменные, отражающие уровень образования родителей респондента, имеют значимую совместную объясняющую способность.
Таблица 3.15
reg S ASVABC SM SF |
|
|
|
|
|
|
Source |
SS |
df |
MS |
|
Number of obs = |
540 |
Model |
1181.36981 |
3 |
393.789935 |
|
F(3, 536) Prob > F |
104.30 0.0000 |
Residual |
2023.61353 |
536 |
3.77539837 |
|
R-squared = Adj R-squared = |
0.3686 0.3651 |
Total
|
3204.98333 |
539 |
5.94616574 |
|
Root MSE |
1.943 |
S |
Coef. |
Std. Err. |
t |
P>|t| |
[95% Conf. |
Interval] |
ASVABC |
.1257087 |
.0098533 |
12.76 |
0.000 |
.1063528 |
.1450646 |
SM |
.0492424 |
.0390901 |
1.26 |
0.208 |
-.027546 |
.1260309 |
SF |
.1076825 |
.0309522 |
3.48 |
0.001 |
.04688 |
.1684851 |
_cons |
5.370631 |
.4882155 |
11.00 |
0.000 |
4.41158 |
6.329681 |
Зависимость между F- и t-статистиками
Предположим, что вы рассматриваете следующие альтернативные спецификации модели:
 (3.76)
(3.76)
 (3.77)
(3.77)
единственным различием между которыми является добавление Хк как объясняющей переменной в (3.77). У вас теперь есть два способа проверки того, принадлежит ли Хк модели. Вы можете выполнить t-тест для ее коэффициента после оценивания (3.77). В качестве альтернативы вы можете выполнить F-тест только что обсужденного вида, обращаясь с Хк как с «группой» лишь из одной переменной, проверив ее предельную объясняющую способность. Для F-теста нулевой гипотезой является H0: βk = 0, поскольку была добавлена только переменная Хк, и это — та же самая нулевая гипотеза, что и для t-теста. Таким образом, может показаться, что имеется риск того, что результаты двух тестов могу: находиться в противоречии друг с другом.
К счастью, это невозможно, так как можно показать, что F-статистика должна равняться квадрату t-статистики и что критическое значение F равно квадрату критического значения t (при двустороннем тесте). Этот результат означает, что t-тест для коэффициента при переменной — это в действительности проверка его предельной объясняющей способности после того, как все другие переменные были включены в уравнение.
Если переменная коррелированна с одной или более другими переменными, то ее предельная объясняющая способность может быть весьма низкой, даже если эта переменная действительно принадлежит модели. Если все переменные коррелированны, то все они могут иметь низкую предельную объясняющую способность, так что ни один из t-тестов не является значимым, даже при том, что F-тест на их совместную объясняющую способность высоко значим Если дело обстоит таким образом, то считают, что модель страдает от проблемы мультиколлинеарности, обсужденной выше в этой главе.
Мы не будем приводить здесь доказательство эквивалентности, но она будет проиллюстрирована на модели продолжительности обучения. В первой регрессии предполагалось, что переменная S зависит от ASVABC и SM. Во второй — считалось, что она также зависит и от SF.
Если сравнивать данные табл. 3.15 с данными табл. 3.16, то улучшение модели от добавления SF отражено в сокращении суммы квадратов остатков (2069,3 - 2023,6). Платой за это является единственная степень свободы, потраченная на оценку коэффициента при SF. Сумма квадратов отклонений, остающаяся после добавления SF, равна 2023,6. Число степеней свободы, остающееся после добавления SF, равно 540 - 4 = 536. Следовательно, F-статистика равна 12,10:
Таблица 3.16
reg S ASVABC SM |
|
|
|
|
|
|
Source |
SS |
df |
MS |
|
Number of obs = |
540 |
Model |
1135.67473 |
2 |
567.837363 |
|
F(2, 537) Prob > F |
147.36 0.0000 |
Residual |
2069.30861 |
537 |
3.85346109 |
|
R-squared = Adj R-squared = |
0.3543 0.3519 |
Total
|
3204.98333 |
539 |
5.94616574 |
|
Root MSE |
1.963 |
S |
Coef. |
Std. Err. |
t |
P>|t| |
[95% Conf. |
Interval] |
ASVABC |
.1328069 |
.0097389 |
13.64 |
0.000 |
.1136758 |
.151938 |
SM |
.1235071 |
.0330837 |
3.73 |
0.000 |
.0585178 |
.1884963 |
_cons |
5.420733 |
.4930224 |
10.99 |
0.000 |
4.452244 |
6.389222 |
 (3.78)
(3.78)
Критическое значение F при уровне значимости 0,1% с 500 степенями свободы равно 10,96. Критическое значение при 536 степенях свободы должно быть более низким, так что мы отклоняем Н0 на 0,1%-ном уровне значимости. Значение t-статистики для коэффициента при SF b регрессии с SM и SF нравно 3,48. Критическое значение t на уровне 0,1% с 500 степенями свободы равно 3,31. Критическое значение при 536 степенях свободы должно быть более низким, так что мы снова отклоняем H0 на основе t-теста. Квадрат числа 3,48 равен 12,11 и полностью совпал бы с F-статистикой, если бы не ошибка округления, а квадрат числа 3,31, равный 10,96, совпадает с критическим значением F(1; 500). Следовательно, выводы, сделанные на основе двух проведенных тестов, должны совпасть.
«Скорректированный» коэффициент R2
Если вы посмотрите
на распечатку результатов оценивания
регрессии, вы почти
наверняка найдете рядом с коэффициентом
R2
коэффициент,
который называют
скорректированным
коэффициентом R2
(«adjusted
R2»).
Иногда его
также называют
«исправленным» коэффициентом R2.
Это определение
не означает, по
мнению многих, что такой коэффициент
улучшен по сравнению с обычным.
Как отмечалось в данном разделе ранее,
при добавлении объясняющей
переменной к уравнению регрессии
коэффициент R2
никогда не
уменьшается,
а обычно увеличивается. Скорректированный
коэффициент R2,
который
обычно обозначают
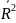 ,
обеспечивает
компенсацию для такого автоматического
сдвига вверх путем наложения «штрафа»
за увеличение числа объясняющих
переменных. Он определяется следующим
образом:
,
обеспечивает
компенсацию для такого автоматического
сдвига вверх путем наложения «штрафа»
за увеличение числа объясняющих
переменных. Он определяется следующим
образом:
 (3.79)
(3.79)
где (к - 1) — число объясняющих переменных. По мере увеличения к увеличивается отношение (к - 1)/(п - к), следовательно, возрастает корректировка R2 в сторону уменьшения.
Можно показать, что
добавление новой переменной к регрессии
приведет к
увеличению
 ,
если и только
если соответствующая t-статистика
больше (или меньше -1). Следовательно,
увеличение
при добавлении
новой переменной
необязательно означает, что ее коэффициент
значимо отличается от нуля.
Поэтому отнюдь не следует, как можно
было бы предположить, что увеличение
означает
улучшение спецификации уравнения.
,
если и только
если соответствующая t-статистика
больше (или меньше -1). Следовательно,
увеличение
при добавлении
новой переменной
необязательно означает, что ее коэффициент
значимо отличается от нуля.
Поэтому отнюдь не следует, как можно
было бы предположить, что увеличение
означает
улучшение спецификации уравнения.
Это является одной из причин того, почему не используется широко в качестве диагностической величины. Другая причина состоит в уменьшение внимания к самому коэффициенту R2. Ранее среди экономистов наблюдалась тенденция рассматривать коэффициент R2 в качестве основного индикатора успеха в спецификации модели. Однако на практике, как будет показано в следующих главах, даже плохо определенная модель регрессии может дать высокий коэффициент R2, и признание этого факта привело к снижению значение R2. Теперь он рассматривается в качестве одного из целого ряда диагностических показателей, которые должны быть проверены при построении модели регрессии, и, вероятно, как один из менее важных. Следовательно, и корректировка этого коэффициента мало что дает.
Ключевые понятия
множественный регрессионный анализ «скорректированный» коэффициент R2 мультиколлинеарность теорема Фриша—Вауга—Ловелла
ограничение