

Функции
В программировании рекурсия — вызов функции (процедуры) из неё же самой, непосредственно (простая рекурсия) или через другие функции (сложная или косвенная рекурсия), например, функция A вызывает функцию B, а функция B — функцию A. Количество вложенных вызовов функции или процедуры называется глубиной рекурсии.
Преимущество рекурсивного определения объекта заключается в том, что такое конечное определение теоретически способно описывать бесконечно большое число объектов. С помощью рекурсивной программы же возможно описать бесконечное вычисление, причём без явных повторений частей программы.
Реализация рекурсивных вызовов функций в практически применяемых языках и средах программирования, как правило, опирается на механизм стека вызовов — адрес возврата и локальные переменные функции записываются в стек, благодаря чему каждый следующий рекурсивный вызов этой функции пользуется своим набором локальных переменных и за счёт этого работает корректно. Оборотной стороной этого довольно простого по структуре механизма является то, что на каждый рекурсивный вызов требуется некоторое количество оперативной памяти компьютера, и при чрезмерно большой глубине рекурсии может наступить переполнение стека вызовов. Вследствие этого, обычно рекомендуется избегать рекурсивных программ, которые приводят (или в некоторых условиях могут приводить) к слишком большой глубине рекурсии.
Процедура или функция может содержать вызов других процедур или функций. В том числе процедура может вызвать саму себя. Никакого парадокса здесь нет – компьютер лишь последовательно выполняет встретившиеся ему в программе команды и, если встречается вызов процедуры, просто начинает выполнять эту процедуру. Без разницы, какая процедура дала команду это делать.
Пример рекурсивной процедуры:
procedure Rec(a: integer);
begin
if a>0 then
Rec(a-1);
writeln(a);
end;
Замена рекурсии итерациями.
Впрочем, имеется специальный тип рекурсии, называемый «хвостовой рекурсией». Интерпретаторы и компиляторы функциональных языков программирования, поддерживающие оптимизацию кода (исходного и/или исполняемого), автоматически преобразуют хвостовую рекурсию к итерации, благодаря чему обеспечивается выполнение алгоритмов с хвостовой рекурсией в ограниченном объёме памяти. Такие рекурсивные вычисления, даже если они формально бесконечны (например, когда с помощью рекурсии организуется работа командного интерпретатора, принимающего команды пользователя), никогда не приводят к исчерпанию памяти. Однако, далеко не всегда стандарты языков программирования чётко определяют, каким именно условиям должна удовлетворять рекурсивная функция, чтобы транслятор гарантированно преобразовал её в итерацию. Одно из редких исключений — язык Scheme (диалект языка Lisp), описание которого содержит все необходимые сведения.
#include <windows.h>
#include <iostream>
#include <conio.h>
using namespace std;
int Fibonachi(int i){
int fib = 1, fib0 = 1;
for(int n=2; n<=i; n++){
int tmp = fib;
fib += fib0;
fib0 = tmp;
}
return fib;
}
int main(){
SetConsoleOutputCP(1251);// Для отображения русских символов
cout << "--- ЧИСЕЛА ФИБОНАЧИ ---\n\n";
cout << "Нажмите любую клавишу, чтобы получить следующее число\n";
cout << "\'Esc\' - Для выхода\n\n";
for(int i=0; ; i++){
if(getch() == 27) return 0;
cout << "Fib(" << i << ") = " << Fibonachi(i) << endl;
}
return 0;
}
Привести пример рекурсивного и итерационного алгоритмов вычисления чисел Фибоначчи.
Рекурсия
#include <windows.h>
#include <iostream>
#include <conio.h>
using namespace std;
int Fibonachi(int i){
if(i==0 || i==1) return 1;
return Fibonachi(i-1) + Fibonachi(i-2);
}
int main(){
SetConsoleOutputCP(1251);// Для отображения русских символов
cout << "--- ЧИСЛА ФИБОНАЧИ ---\n\n";
cout << "Нажмите любую клавишу, чтобы получить следующее число\n";
cout << "\'Esc\' - Для выхода\n\n";
for(int i=0; ; i++){
if(getch() == 27) return 0;
cout << "Fib(" << i << ") = " << Fibonachi(i) << endl;
}
return 0;
}
Замена рекурсии итерациями
#include <windows.h>
#include <iostream>
#include <conio.h>
using namespace std;
int Fibonachi(int i){
int fib = 1, fib0 = 1;
for(int n=2; n<=i; n++){
int tmp = fib;
fib += fib0;
fib0 = tmp;
}
return fib;
}
int main(){
SetConsoleOutputCP(1251);// Для отображения русских символов
cout << "--- ЧИСЕЛА ФИБОНАЧИ ---\n\n";
cout << "Нажмите любую клавишу, чтобы получить следующее число\n";
cout << "\'Esc\' - Для выхода\n\n";
for(int i=0; ; i++){
if(getch() == 27) return 0;
cout << "Fib(" << i << ") = " << Fibonachi(i) << endl;
}
return 0;
}
10.Статические одномерные массивы.
Массив - последовательность однотипных элементов.
Если говорить упрощенно, то массив представляет собой компьютерный эквивалент таблицы. Они используются для упорядоченного хранения данных, к которым требуется многократные обращения в ходе выполнения программы.
Положение элемента в массиве однозначно определяется его индексом (для одномерного массива) или индексами (для многомерного массива). Размерность массива – это количество индексов у каждого элемента массива.
Каждый индекс изменяется в некотором диапазоне [a,b]. Диапазон [a,b] называется граничной парой, a - нижней границей, b - верхней границей индекса. При объявлении массива границы задаются выражениями. Если при объявлении массива все границы заданы константными выражениями, то число элементов массива известно в момент его объявления и ему может быть выделена память уже на этапе трансляции. Такие массивы называются статическими.
Они определены установленными, неизменяемыми размерами. Они могут быть одномерными или многомерными - последний является массивом массивов (массивов и т.д). Размер и диапазон такого многомерного массива всегда даются для самого высокого, крайнего левого массива - родительского массива.
Размер каждого измерения определен двумя способами, которые могут быть свободно смешаны в многомерном массиве :
Index type, где Index целое число, обычно Byte или Word. Диапазон этого типа определяет диапазон измерения. Например, Byte дает дипазон 0..255.
Ordinal..Ordinal Альтернативно, диапазон каждого измерения может быть задан предписанными порядковыми значениями, типа 22..44.
Имя
массива
Индекс
Массив







Хранение одномерных массивов в памяти компьютера.
Для размещения массива в памяти ЭВМ отводится поле памяти, размер которого определяется типом, длиной и размерностью массива. В языке C/C++ эта информация задается в разделе описаний.
Элементы массива размещаются в памяти последовательно, друг за другом. Каждый элемент массива занимает столько памяти, сколько отводится под переменную, тип которой указан при описании массива.
Размер массива – это общее количество элементов в массиве. Чаще под размером массива понимают объем памяти, занимаемый массивом – это общее количество элементов в массиве, умноженное на размер одного элемента. Размер, который занимает переменная-массив в памяти можно узнать в программе с использованием конструкции
sizeof(A);
где А – имя переменной или массива.


Реальный адрес элемента массива в памяти можно вычислить, зная базовый адрес массива (адрес начала массива), тип элементов массива и номер нужного элемента.
char C[5];
Addr(C[i]) = Addr(C) + i*sizeof(char);
При выполнении инженерных и математических расчетов часто используются переменные более чем с одним индексом. При решении задач на ЭВМ такие переменные представляются как компоненты соответственно двух-, трех-, четырехмерных массивов и т.д.
Описание массива в виде многомерной структуры делается лишь из соображений удобства программирования как результат стремления наиболее точно воспроизвести в программе объективно существующие связи между элементами данных решаемой задачи. Что же касается образа массива в памяти ЭВМ, то как одномерные, так и многомерные массивы хранятся в виде линейной последовательности своих компонент, и принципиальной разницы между одномерными и многомерными массивами в памяти ЭВМ нет. Однако порядок, в котором запоминаются элементы многомерных массивов, важно себе представлять. В большинстве алгоритмических языков реализуется общее правило, устанавливающее порядок хранения в памяти элементов массивов: элементы многомерных массивов хранятся в памяти в последовательности, соответствующей более частому изменению младших индексов.
Объявление массивов, работа с массивами,.
Обработка массивов
Над элементами массивами чаще всего выполняются такие действия, как
а) поиск значений;
б) сортировка элементов в порядке возрастания или убывания;
в) подсчет элементов в массиве, удовлетворяющих заданному условию.
Способ 1. Инициализация при описании массива
Если ничего не засылать в массив перед началом работы с ним, то внешние, статические и автоматические массивы инициализируются для числовых типов нулем и '\0' (null) для символьных типов. Если в статическом, внешнем или автоматическом массиве нам нужны первоначальные значения, отличные от нуля, то язык С/С++ позволяет сделать это следующим образом:
/* дни месяца */
int days[12]={31,28,31,30,31,30,31,31,30,31,30,31};
int main( )
{
int index;
for(index = 0; index<12; index++)
printf("Месяц %d имеет %d дней.\n", index+1,
days[index]);
return 0;
}
Объявление и инициализация массивов
const int N = 10;
int A1[N]; // | Объявление массивов
int A2[N], A3[20]; // | без инициализации
// Объявление и инициализация массивов
int B1[N] = {5, 6, 6, 6, 5, 6, 6, 7, 8, 2};
int B3[N] = {1, 2, 3};
int B2[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int B4[] = {1, 2, 3};
// Инициализация массива A1
for(int i=0; i<N; i++) A1[i] = i;
// Печать массивов
for(int i=0; i<N; i++){
cout <<A1[i] <<'\t' <<A2[i] <<'\t' <<B1[i] <<'\t' <<B2[i] <<endl;
}
передача массивов в функции
#include <windows.h>
#include <iostream>
#include <conio.h>
#include <time.h>
using namespace std;
int GetNumber(int Numbers[]);
int main(){
SetConsoleOutputCP(1251);// Для отображения русских символов
cout << "--- РУССКОЕ ЛОТО ---\n\n";
cout << "Нажмите любую клавишу, чтобы достать бочонок\n ";
cout << "\'Esc\' - Для выхода\n\n";
srand((unsigned int)clock());
int Numbers[99];
for(int i=0; i<99; i++) Numbers[i] = i;
while(getch() != 27) {
cout << GetNumber(Numbers) << endl;
}
return 0;
}
int GetNumber(int Numbers[]){
static int Size = 99;
if(Size == 0) return -1;// Если все номера выпали, возвращаем -1
int rnd = rand()%Size; // rnd - случайное число от 0 до Size;
int N = Numbers[rnd];// Сохраняем значение
// Смещаем влево все номера массива, правее N
for(int i=rnd; i<Size-1; i++){
Numbers[i] = Numbers[i+1];
}
Size--;
return N + 1;
}
?11. Статические многомерные массивы.
Для статического массива — отсутствие динамики, невозможность удаления или добавления элемента без сдвига других.
Они определены установленными, неизменяемыми размерами. Они могут быть одномерными или многомерными - последний является массивом массивов (массивов и т.д). Размер и диапазон такого многомерного массива всегда даются для самого высокого, крайнего левого массива - родительского массива.
Размер каждого измерения определен двумя способами, которые могут быть свободно смешаны в многомерном массиве :
Index type, где Index целое число, обычно Byte или Word. Диапазон этого типа определяет диапазон измерения. Например, Byte дает дипазон 0..255.
Ordinal..Ordinal Альтернативно, диапазон каждого измерения может быть задан предписанными порядковыми значениями, типа 22..44.
Одномерные массивы хорошо подходят для представления простых списков данных. Однако часто бывает необходимо представить таблицы данных в программах с организацией данных в формате строк и столбцов, подобно ячейкам в рабочих листах Excel. Для этого необходимо использовать многомерные массивы. Так адрес каждой ячейки листа состоит из двух чисел, одно из которых (номер строки) является первым индексом, а второе (номер столбца) - вторым индексом массива. Такой массив называется двумерным массивом. Добавив еще номер листа, получим трехмерный массив. VBA позволяет создавать массивы, имеющие до 60 измерений.
Многомерные массивы.
new позволяет выделять только одномерные массивы, поэтому для работы с многомерными массивами необходимо воспринимать их как массив указателей на другие массивы.
Для примера рассмотрим задачу выделения динамической памяти под массив чисел размера n на m.
1ый способ
На первом шаге выделяется указатель на массив указателей, а на втором шаге, в цикле каждому указателю из массива выделяется массив чисел в памяти:
int ** a = new int*[n];
for (int i = 0; i != n; ++i)
a[i] = new int[m];
Однако, этот способ плох тем, что в нём требуется n+1 выделение памяти, а это достаточно дорогая по времени операция.
2ой способ
На первом шаге выделение массива указателей и массива чисел размером n на m. На втором шаге каждому указателю из массива ставится в соответствие строка в массиве чисел.
int ** a = new int*[n];
a[0] = new int[n*m];
for (int i = 1; i != n; ++i)
a[i] = a[0] + i*m;
В данном случае требуется всего 2 выделения памяти.
Для освобождения памяти требуется выполнить:
1ый способ:
for (int i = 0; i != n; ++i)
delete [] a[i];
delete [] a;
2ой способ:
delete [] a[0];
delete [] a;
Таким образом, второй способ опять же требует гораздо меньше вызовов функции delete [], чем первый.
Хранение многомерных массивов в памяти компьютера.
Двумерный массив (массив массивов) хранится в памяти последовательно, по строкам: сначала хранятся все элементы первой строки (первый индекс = 0), затем элементы второй строки (первый индекс = 1) и т.д. – т.е. при последовательном перемещении по элементам массива в памяти всегда сначала изменяется младший индекс, затем более старший и т.д.

int D[Rows][Cols];
Addr(D[j][i]) = Addr(D) + (j*Cols+i)*sizeof(int);
где (j*Cols+i) – порядковый номер элемента в памяти при обходе массива.
Объявление массивов, работа с массивами, передача массивов в функции.
Обработка массивов
Над элементами массивами чаще всего выполняются такие действия, как
а) поиск значений;
б) сортировка элементов в порядке возрастания или убывания;
в) подсчет элементов в массиве, удовлетворяющих заданному условию.
Многомерные массивы
#include <windows.h>
#include <iostream>
#include <conio.h>
#include <time.h>
using namespace std;
void FillMatr(int matr[][3]);
void PrintMatr(int matr[][3]);
void SumMatr(int M1[][3], int M2[][3], int Sum[][3]);
int main(){
SetConsoleOutputCP(1251);// Для отображения русских символов
srand((unsigned int)clock());
int M1[3][3], M2[3][3], Sum[3][3];
FillMatr(M1);
FillMatr(M2);
cout << "Первая матрица\n";
PrintMatr(M1);
cout << "\nВторая матрица\n";
PrintMatr(M2);
SumMatr(M1, M2, Sum);
cout << "\nСумма\n";
PrintMatr(Sum);
return 0;
}
Многомерные массивы
void FillMatr(int matr[][3]){
for(int i=0; i<3; i++){
for(int j=0; j<3; j++){
matr[i][j] = rand()%8-4;
}
}
}
void PrintMatr(int matr[][3]){
for(int i=0; i<3; i++){
for(int j=0; j<3; j++){
cout << matr[i][j] << '\t';
}
cout << endl;
}
}
void SumMatr(int M1[][3], int M2[][3], int Sum[][3]){
for(int i=0; i<3; i++){
for(int j=0; j<3; j++){
Sum[i][j] = M1[i][j] + M2[i][j];
}
}
}
12.Строки в С++.
Строка – это массив символов. Любая строка должна заканчиваться символом ‘\0’
Объявление строк, работа со строками, передача строк в функции.
char S1[] = {'С', 'Т', 'Р', 'О', 'К', 'А', '1', '\0'};
char S2[] = {'С', 'Т', 'Р', 'О', 'К', 'А', '2', 0};
char S3[] = "СТРОКА3";
char S4[8] = "СТРОКА4"; // размер массива - 8!!!!
cout << S1 << '\n' << S2 << '\n' << S3 << '\n' << S4 << endl;
/* output:
СТРОКА1
СТРОКА2
СТРОКА3
СТРОКА4
*/
Массивы строк.
Введение
Исторически работа со строками в языках С и С++ вызывает затруднения у новичков. Как мне кажется, во многом это связано с тем, что в этих языках строки значительно отличается от строк в языках типа Basic и Pascal. Непонимание базовых принципов приводит к тому, что код либо не работает вовсе, либо что еще хуже, работает, но не стабильно или непредсказуемо даже для его авторов. Основой для написания данной статьи по большей части послужили вопросы, часто задаваемые новичками. Надеюсь, хотя бы часть таких вопросов она снимет.
Это первая часть, в которой обсуждаются «традиционные» строки в С. В С++ существуют более удобные механизмы для работы со строковыми данными, эти механизмы рассматриваются во второй части статьи. А зачем вообще обсуждать неудобные С-строки, если есть С++? К сожалению, совсем забыть о строках в стиле С нельзя по двум причинам:
существует большое количество библиотек (например, API операционных систем) работающих именно с С-строками
строковые классы в С++ все равно основаны на традиционных С-строках, и если мы хотим разобраться в том, как они работают, нам придется понимать их основы.
Строковые литералы
Самая простая строковая сущность (под строковой сущностью я понимаю нечто, с чем можно работать как с привычной строкой) в С — это так называемый «строковый литерал». Он представляет собой последовательность символов, заключенную в двойные кавычки. Пример:
"Здравствуй, мир!"
Пока я намеренно игнорирую вопрос о том, что есть строковый литерал с точки зрения компилятора или языка, ограничиваясь только его свойствами с точки зрения программиста.
Основное свойство строкового литерала — простота его использования. Не имея ни малейшего представления о том, чем он является на самом деле, мы можем использовать его практически везде, где от нас ждут строку. Например, в WinAPI-функцию SetWindowText (она задает текст, связанный с окном) нужно передать описатель окна и строку текста. И мы можем вызвать ее очень просто:
SetWindowText(hwnd, "Новый заголовок окна");
Но конечно, строковых литералов, естественно, фиксируемых при создании программы, будет маловато. Хотелось бы иметь возможность использовать переменные, не правда ли?
13.Ссылки.
Ссылка – это псевдоним переменной.
В языке программирования C++ ссылка — это простой ссылочный тип, менее мощный, но более безопасный, чем указатель, унаследованый от языка Си. Название C++ ссылка может приводить к путанице, так как в информатике под ссылкой понимается обобщенный концептуальный тип, а указатели и С++ ссылки являются специфическими реализациями ссылочного типа.
Ссылка в программировании — это объект, указывающий на определенные данные, но не хранящий их. Получение объекта по ссылке называется разыменованием.
Ссылка не является указателем, а просто является другим именем для объекта.
В языках программирования ссылка может быть реализована как переменная, содержащая адрес ячейки памяти. В некоторых языках высокого уровня также имеется возможность использовать ссылки на объекты при передаче объектов в подпрограмму и из подпрограммы.
Объявление и работа с ссылками.
#include <iostream>
using namespace std;
void myAbs(int *pA){
if(*pA<0) *pA = -*pA;
}
void myInc(int &A){
A++;
}
int main(){
int A = -5; // А = -5
int &B = A; // В - это ссылка на А (ПСЕВДОНИМ А)
B--; // В = -6, А = -6 (!!!)
myAbs(&A); // А = 6
myInc(A); // А = 7
myInc(B); // А = 8
B = -B; // А = -8
myAbs(&B); // А = 8
return 0;
}
Передача параметров в функции по значению и по ссылке.
Передача параметров в функции по значению и по ссылке.
Переменные, в которых сохраняются параметры, передаваемые функции, также являются локальными для этой функции. Эти переменные создаются при вызове функции и в них копируются значения, передаваемые функции в качестве параметров. Эти переменные можно изменять, но все изменения этих переменных будут "забыты" после выхода из функции. Такой способ передачи параметров называется передачей параметров по значению.
Чтобы функция могла изменять значения переменных, объявленных в других функциях, необходимо указать, что передаваемый параметр является не просто константной величиной, а переменной, необходимо передавать значения по ссылке. Для этого функцию swap следовало бы объявить следующим образом:
void swap(int & a, int & b)
void f(int x)
{
// передача параметра по значению
cout << x;
x = 1;
cout << x;
}
void h(int& x)
{
// передача параметра по ссылке
cout << x;
x = 3;
cout << x;
}
void i(const int& x)
{
// передача неизменяемого параметра по ссылке
cout << x;
x = 4; //Ошибка из-за которой код не будет скомпилирован
cout << x;
}
Передача параметра по ссылке
Передача параметра по ссылке означает что копируется не само значение, а адрес исходной переменной (как в случае передачи параметра по адресу), однако синтаксис используется такой, чтобы программисту не приходилось использовать операцию разыменования и он мог иметь дело непосредственно со значением, хранящимся по этому адресу (как в случае передачи параметра по значению).
Передача по ссылке позволяет избежать копирования всей информации, описывающей состояние объекта (а это может быть существенно больше чем sizeof(int)) и является необходимой для конструктора копирования.
Передача параметра по значению
Передача параметра по значению означает что вызывающая функция копирует в память, доступную вызываемой, (обычно стек) непосредственное значение. Изменение копии переменной, соответственно, оригинал не затрагивает.
14.Указатели.
Указатели – это переменные, которые содержат в качестве своих значений адреса в памяти. Каждая переменная, объявляемая как указатель должна иметь перед собой знак звездочки (*).
10
N
pN
pN
N
0x001efe3c
:
0x001efe48
0x001efe48
:
10






Объявление и работа с указателями.
Пример:
int N = 10, *pN;
pN = &N;
& - Операция адресации
(унарная операция, возвращающая адрес своего операнда).
Операция разыменовывания и взятия адреса.
* – операция косвенной адресации или операция разыменовывания
Пример:
int N = 10, *ptr1, *ptr2;
ptr1 = &N; // ptr1 = адрес N
ptr2 = &N; // ptr2 = адрес N
*ptr1 = 5; // N = 5, ptr1 = адрес N (значение ptr1 НЕ МЕНЯЕТСЯ!)
*ptr2 = 6; // N = 6, ptr2 = адрес N (значение ptr2 НЕ МЕНЯЕТСЯ!)
int M = *ptr2; // M = 6;
ptr1 = &M; // ptr1 = адрес M
*ptr1 = 8; // M = 8, ptr1 = адрес M (значение ptr1 НЕ МЕНЯЕТСЯ!)
Особенности передачи адресов переменных в функции в качестве параметров.
Имя массива является УКАЗАТЕЛЕМ на его первый элемент
int v[6] = {1,2,3,4,5,6};
int *ptr;
ptr = v; //ptr = адрес v[0]
ptr = &v[0]; //ptr = адрес v[0] (ТО-ЖЕ САМОЕ!!!)
int A;
A = v[3];
A = *(ptr + 3); //(ТО-ЖЕ САМОЕ!!!)
15.Указатели на функции.
Указатель на функцию содержит адрес функции в памяти
Имя функции – начальный адрес её кода
Пример:
void bubbleSort(int *arr, int N, bool (*compare)(int, int)){
for(int pass = 1; pass < N; pass++){
for(int i=0; i<N-1; i++){
if(compare(arr[i], arr[i+1])) swap(&arr[i], &arr[i+1]);
}
}
}
Пример:
void bubbleSort(int *arr, int N, bool (*compare)(int, int));
void swap(int *el1, int *el2);
bool Ascending(int a, int b){ return a>b;}
bool Decending(int a, int b){ return a<b;}
int main(){
SetConsoleOutputCP(1251);// Для отображения русских символов
cout << "--- Сортировка массива ---\n\n";
const int N = 10;
int arr[N] = {2,6,8,2,4,1,9,0,1,7};
cout << "Исходные данные: \n";
for(int i=0; i<N; i++) cout << arr[i] << " ";
cout << "Нажмите\n\
+ для сортировки по возрастанию\n\
- для сортировки по убыванию";
char ch = 0;
while(ch != '+' && ch != '-')ch = _getch();
if(ch == '+') bubbleSort(arr, N, Ascending);
else bubbleSort(arr, N, Decending);
cout << "\nОтсортированные данные: \n";
for(int i=0; i<N; i++) cout << arr[i] << " ";
cout << "\n\n";
return 0;
}
Пример работы с указателем на функции.
Пример:
void bubbleSort(int *arr, int N, int (*compare)(int, int)){
for(int pass = 1; pass < N; pass++){
for(int i=0; i<N-1; i++){
if(compare(arr[i], arr[i+1])) swap(&arr[i], &arr[i+1]);
}
}
}
Пример:
void bubbleSort(int *arr, int N, bool (*compare)(int, int));
void swap(int *el1, int *el2);
bool Ascending(int a, int b){ return a>b;}
bool Decending(int a, int b){ return a<b;}
int main(){
SetConsoleOutputCP(1251);// Для отображения русских символов
cout << "--- Сортировка массива ---\n\n";
const int N = 10;
int arr[N] = {2,6,8,2,4,1,9,0,1,7};
cout << "Исходные данные: \n";
for(int i=0; i<N; i++) cout << arr[i] << " ";
cout << "Нажмите\n\
+ для сортировки по возрастанию\n\
- для сортировки по убыванию";
char ch = 0;
while(ch != '+' && ch != '-')ch = _getch();
if(ch == '+') bubbleSort(arr, N, Ascending);
else bubbleSort(arr, N, Decending);
cout << "\nОтсортированные данные: \n";
for(int i=0; i<N; i++) cout << arr[i] << " ";
Во
время выполнения функции:


return 0;
}
16.Динамическое выделение памяти.
void Function(){
int N = 10, *pN, *pM;
pN = &N;
pM = new int;
*pM = 20;
}
После
выполнения функции:

НЕ ОСВОБОЖДАЕТСЯ АВТОМАТИЧЕСКИ !
После
выполнения функции:
Во
время выполнения функции:
Пример:
void Function(){
int N = 10, *pN, *pM;
pN = &N;
pM = new int;
*pM = 20;
delete pM;
}
После выполнения функции память выделенная оператором new освобождается вручную с помощью оператора delete.
Пример выделения памяти под массив:
void Function(int N){
double *Arr;
//Выделение памяти:
Arr = new double[N];
…… // Использование массива Arr
//Освобождение памяти:
delete[] Arr; // !!! []-обязательно !!!
}
В языке С динамическое распределение памяти осуществляется с помощью функций библиотеки stdlib:
malloc, calloc – для выделения памяти;
free – для освобождения выделенной памяти.
Поскольку С++ является приемником С, эти функции доступны и при программировании на С++, но их использование считается «ПЛОХИМ ТОНОМ». Кроме того, память выделенная с помощью функций malloc и calloc НЕ МОЖЕТ быть удалена с помощью оператора delete, и наоборот, для освобождения памяти выделенной оператором new НЕ МОЖЕТ использоваться функция free.
Динамические массивы.
Динамическим называется массив, размер которого может меняться во время исполнения программы. Для изменения размера динамического массива язык программирования, поддерживающий такие массивы, должен предоставлять встроенную функцию или оператор. Динамические массивы дают возможность более гибкой работы с данными, так как позволяют не прогнозировать хранимые объёмы данных, а регулировать размер массива в соответствии с реально необходимыми объёмами. Обычные, не динамические массивы называют ещё статическими.
Объявление динамических массивов,
Пример
ArrayList array=new ArrayList();
array.Add(256);
array.Add("Hello World!");
array.Add(true);
Код:
int *mas = new int[10]; // массив из 10 целочисленных переменных.
// теперь сделаем матрицу 10 на 10
int i;
int **matr;
matr = new int*[10];
for(i=0;i<10; i++)
matr[i] = new int[10];
//и не забываем освободить память:
delete[] mas;
for(i=0; i<10; i++)
delete[] matr[i];
delete[] matr;
работа с динамически выделенной памятью.
Динамическое распределение памяти — способ выделения оперативной памяти компьютера для объектов в программе, при котором выделение памяти под объект осуществляется во время исполнения программы.
При динамическом распределении памяти объекты размещаются в т.н. «куче» (англ. heap): при конструировании объекта указывается размер запрашиваемой под объект памяти, и, в случае успеха, выделенная область памяти, условно говоря, «изымается» из «кучи», становясь недоступной при последующих операциях выделения памяти. Противоположная по смыслу операция — освобождение занятой ранее под какой-либо объект памяти: освобождаемая память, также условно говоря, возвращается в «кучу» и становится доступной при дальнейших операциях выделения памяти.
По мере создания в программе новых объектов, количество доступной памяти уменьшается. Отсюда вытекает необходимость постоянно освобождать ранее выделенную память. В идеальной ситуации программа должна полностью освободить всю память, которая потребовалась для работы. По аналогии с этим, каждая процедура (функция или подпрограмма) должна обеспечить освобождение всей памяти, выделенной в ходе выполнении процедуры. Некорректное распределение памяти приводит к т.н. «утечкам» памяти, когда выделенная память не освобождается. Многократные утечки памяти могут привести к исчерпанию всей оперативной памяти и нарушить работу операционной системы.
Другая проблема — это проблема фрагментации памяти. Выделение памяти происходит блоками — непрерывными фрагментами оперативной памяти (таким образом, каждый блок — это несколько идущих подряд байтов). В какой-то момент, в куче попросту может не оказаться блока подходящего размера и, даже, если свободная память достаточна для размещения объекта, операция выделения памяти окончится неудачей.
Для управления динамическим распределением памяти используется «сборщик мусора» — программный объект, который следит за выделением памяти и обеспечивает её своевременное освобождение. Сборщик мусора также следит за тем, чтобы свободные блоки имели максимальный размер, и, при необходимости, осуществляет дефрагментцию памяти.
14.1. Распределение памяти
Память для хранения данных может выделяться как статически, так и динамически [7]. В первом случае выделение памяти выполняет компилятор, встретивший при компиляции объявление объекта. В соответствии с типом встретившегося объекта вычисляется объем памяти, требуемый для его размещения. Класс памяти задает место, где эти объекты (данные) будут располагаться. Это может быть сегмент данных либо стек. Напомним, что стек (магазин, список LIFO – Last In First Out) представляет собой последовательный список переменной длины, в котором включение и исключение элементов производится только с одной стороны. Главные операции при работе со стеком – включение и исключение элемента – осуществляются с вершины стека, причем в каждый момент доступен элемент, находящийся на вершине стека.
Часто возникают ситуации, когда заранее не известно, сколько объектов – чисел, строк текста и прочих данных будет хранить программа. В этом случае используется динамическое выделение памяти, когда память занимается и освобождается в процессе исполнения программы. При использовании динамической памяти (ДП) отпадает необходимость заранее распределять память для хранения данных, используемых программой. Управление динамической памятью – это способность определять размер объекта и выделять для его хранения соответствующую область памяти в процессе исполнения программы.
При динамическом выделении памяти для хранения данных используется специальная область памяти, так называемая «куча» (heap). Объем «кучи» и ее местоположение зависят от модели памяти, которая определяет логическую структуру памяти программы (гл. 8).
Функции, выполняющие динамическое распределение памяти в «куче», и заголовочные файлы, в которых эти функции объявлены, представлены в табл. 14.1.
При каждом обращении к функции распределения памяти выделяется запрошенное число байт. Адрес начала выделенной памяти возвращается в точку вызова функции и записывается в переменную-указатель. Созданная таким образом переменная называется динамической переменной. Распределенная память гарантируется от повторного выделения при следующих обращениях за байтами памяти. Дальнейшая работа с выделенной областью осуществляется через переменную-указатель, хранящую адрес выделенной области памяти. Сама же переменная остается безымянной.
Таблица 14.1
Если выделенный участок памяти больше не требуется, он может быть освобожден. При высокой активности по динамическому распределению памяти «куча» фрагментируется. Для смягчения отрицательных последствий фрагментации служат функции повторного распределения памяти. Они пытаются либо расширить, либо уменьшить размер ранее выделенного блока памяти.
Динамическое распределение памяти
Память, которую использует программа делится на три вида:
Статическая память (static memory)
хранит глобальные переменные и константы;
размер определяется при компиляции.
Стек (stack)
хранит локальные переменные, аргументы функций и промежуточные значения вычислений;
размер определяется при запуске программы (обычно выделяется 4 Мб).
Куча (heap)
динамически распределяемая память;
ОС выделяет память по частям (по мере необходимости).
Динамически распределяемую память следует использовать в случае если мы заранее (на момент написания программы) не знаем сколько памяти нам понадобится (например, размер массива зависит от того, что введет пользователь во время работы программы) и при работе с большими объемами данных (например, массив из 1 000 000 int`ов не поместится на стеке).
абота с динамической памятью в С++
В С++ есть свой механизм выделения и освобождения памяти — это функции new и delete.
Пример использования new:
int * p = new int[1000000]; // выделение памяти под 1000000 int`ов
Т.е. при использовании функции new не нужно приводить указатель и не нужно использовать sizeof().
Освобождение выделенной при помощи new памяти осуществляется посредством следующего вызова:
delete [] p;
Если требуется выделить память под один элемент, то можно использовать
int * q = new int;
или
int * q = new int(10); // выделенный int проинциализируется значением 10
в этом случае удаление будет выглядеть следующим образом:
delete q;
Замечание:
Выделять динамически небольшие кусочки памяти (например, под один элемент простого типа данных) не целесообразно по двум причинам:
При динамическом выделении памяти в ней помимо значения указанного типа будет храниться служебная информация ОС и С/С++. Таким образом потребуется гораздо больше памяти, чем при хранении необходимых данных на стеке.
Если в памяти хранить большое количество маленьких кусочков, то она будет сильно фрагментирована и большой массив данных может не поместиться.
17.Массивы указателей.
Все по указателю:
Указатель (поинтер, англ. pointer) — переменная, диапазон значений которой состоит из адресов ячеек памяти и специального значения — нулевого адреса. Значение нулевого адреса не является реальным адресом и используется только для обозначения того, что указатель в данный момент не может использоваться для обращения ни к какой ячейке памяти.
Указатели применяются в двух различных сферах. Во-первых, они позволяют использовать некоторые выгоды косвенной адресации, широко применяемой в программировании на языках ассемблера. Во-вторых, указатели предлагают метод динамического управления памятью: их можно использовать для доступа к области с динамическим размещением памяти, обычно называемой кучей, или динамической памятью.
Переменные, размещаемые в куче, называются динамическими. Часто они не содержат связанных с ними идентификаторов, и ссылаться на них можно только с помощью указателей и ссылок.
Операции над указателями
Языки программирования, в которых предусмотрен тип указателей, содержат, как правило, две основные операции над ними: присваивание и разыменование. Первая из этих операций присваивает указателю некоторый адрес. Вторая служит для обращения к значению в памяти, на которое указывает указатель. Разыменование может быть явным и неявным, в большинстве современных языков программирования разыменование происходит только при явном указании.
В случае, если указатель хранит адрес какого-либо объекта, то говорят, что указатель ссылается или указывает на этот объект p.
Языки, предусматривающие использование указателей для управления динамической памятью, должны содержать оператор явного размещения переменных в памяти. В некоторых языках помимо этого оператора предусмотрен ещё и оператор явного удаления переменных из памяти. Обе эти операции часто принимают форму встроенных подпрограмм.
Нулевой указатель
Нулевой указатель − это указатель, хранящий специальное значение, используемое для того, чтобы показать, что данная переменная-указатель не ссылается (не указывает) ни на какой объект. В различных языках программирования представлен различными константами.
17.Массивы указателей.=Повторому разу!
Указатели
Указатели - это переменные, которые содержат адрес адреса данных. В С++ указатели могут быть на любой тип данных.
Если необходимо, можно описать массив указателей.
int*ip[ 10 ];
массив указателей на целые значения из 10 элементов.
С указателем можно производить некоторые арифметические операции. Например, при работе с массивами.
Пусть sub содержит номер элемента массива, тогда до этого элемента можно "добраться"
mas [ sub ]
или
*(mas +sub)
Т.к. имя массива фактически является указателем на нулевой элемент массива. Переменная sub указывает на сколько элементов необходимо сместиться. Вы можете инкрементировать и декрементировать указатель. При этом вы смещаетесь на один элемент, независимо от типа элемента.
Допустим uk адрес нулевого элемента массива, тогда
cout<<*uk; // вывод значения 0-го элемента
uk++;
cout<<*uk; // вывод значения 1-го элемента, реально смещение на несколько байтов
uk+=2
cout<<*uk; // вывод значения 3-го элемента.
Наиболее полезное применение массивов указателей - это массив указателей на строки.
Пример.
char names [3] [20]= {
{"Иванов"},
{"Петров"},
{"Сидоров "}
};
Массив указателей (МУ) – простейшая структура данных, в которой проявляется различие между физическим и логическим порядком следования элементов. Способ организации данных ясен уже из самого определения: это массив, каждый элемент которого содержит указатель на переменную (объект).
Организация двумерных массивов через массивы указателей.
Организация двумерного динамического массива производится в два этапа.
Сначала создаётся одномерный массив указателей, а затем каждому элементу
этого массива присваивается адрес одномерного массива. Для характеристик
размеров массивов не требуется константных выражений.
*/
int **pArr = new int*[dim1];
for (i = 0; i < dim1; i++) pArr[i] = new int[dim2];
pArr[3][3] = 100;
cout << pArr[3][3] << endl;
fdArr(pArr,3,3);
/*
Последовательное уничтожение двумерного массива…
*/
for (i = 0; i < dim1; i++) delete[]pArr[i];
delete[]pArr;
/*
Промер использования массивов указателей(хранение симметричной матрицы).
Matr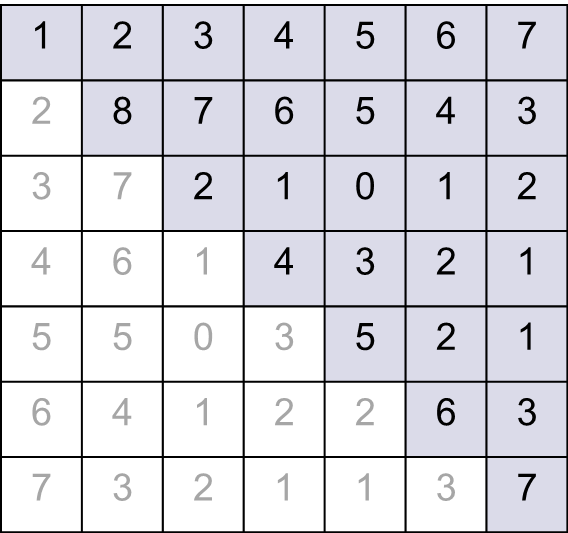







int main(){
int N = 7;
//Выделение памяти
double **Matr = new double *[7];
for(int i=0; i<N; i++){
Matr[i] = new double[N-i];
}
// Использование матрицы
// ..........
//Освобождение памяти
for(int i=0; i<N; i++){
delete[] Matr[i];
}
delete[] Matr;
return 0;
}
18.Структуры С++.
Основные понятия
Структура - это набор данных, где данные могут быть разного типа. Например,
структура может содержать несколько переменных типа int и несколько переменных
типа char. Переменные, которые содержаться в структуре называются членами или
полями структуры. Структуры можно определять с помощью ключевого слова
struct.
Пример описания структуры:
struct student
{
char name[50];
int kurs;
int
age;
};
Мы определили структуру в которую входят переменные kurs, age
и массив name. В этом описании student является шаблоном структуры, struct
student является типом данных. После описания структуры нужно ставить точку с
запятой. Чтобы использовать структуру необходимо объявить переменные типа struct
student.
Например,
struct student s1, s2;
Переменные s1 и s2 являются переменными типа struct student.
Компилятор автоматически выделит память под эти переменные. Под каждую из
переменных типа структуры выделяется непрерывный участок памяти.
Для получения доступа к полям структуры используется операция
точка. Например,
strcpy(s1.name, "Бардин Павел");
s1.kurs=3;
s1.age=20;
В языке С есть возможность объявлять переменные структуры при
описании структуры:
struct student
{
char name[50];
int kurs;
int age;
} s1, s2;
Переменные s1 и s2 являются переменными типа struct student.
Элементами или полями структуры могут быть переменные, массивы,
ранее определенные структуры. Функции не могут быть полями структуры (В языке
Си). В языке С++ функции могут быть полями структуры и такие структуры
называются классами. Они определяются с помощью ключевого слова class.
Для переменных s1 и s2 возможно присваивание
s1=s2
так как эти переменные созданы на базе одного шаблона. После
такого присваивания поля структуры s1 будут содержать ту же информацию, что и
поля s2. Если мы опишем две структуры с одними и теми же полями, но первая
структура будет иметь шаблон student1, а вторая student2, то присваивание s1=s2
недопустимо.