

Структуры
Структура-это совокупность логически связанных переменных, возможно, различных типов, сгруппированных под одним именем для удобства дальнейшей обработки. Традиционным примером структуры служит учетная карточка работающего: служащий предприятия описывается набором атрибутов, таких, как табельный номер, имя, дата рождения, пол, адресс, зарплата. В свою очередь, некоторые из этих атрибутов сами могут оказаться структурами. Таковы, например: имя, дата рождения, адресс, имеющие несколько компонент. Элементы структуры обозначаются идентификаторами, с которыми можно связываьб описатели типов. В результате структуру можно рассматривать как единое целое и осуществлять при необходимости выбор составляющих ее элементов. Для образования структуры присваиваются имена каждому из включаемых элементов и структуре в целом. Затем посредством спечиального описания задают иерархию, порядок следования и типы элементов, включаемых в структуру. Так, для рассмотренного выще примера с анкетой служащего можно выбрать имена:
: Все эти понятия можно объединить в такую, например, структуру:
Эта запись называется описанием структуры. Она начинается с ключевого слова struct и состоит из заключенного в фигурные скобки списка описаний. За словом struct может следовать необязательное имя, которое называется именем типа структуры (иногда его называют тэгом или ярлыком структуры). Этот ярлык именует структуру и в дальнейшем может использоваться для сокращения подробного описания. Переменные, упоминающиеся в записи, называются элементами. Следом за правой фигурной скобкой, заканчивающей список элементов, может следовать список переменных, так же, как и в случае базисных типов. Вот почему в приведенном выше описании структуры после закрывающей фигурной скобки стоит точка с запятой; она завершает пустой список. Описание struct {....} p1, p2, p3; синтаксически аналогично int p1, p2, p3; в том смысле, что каждый из операторов описывает p1, p2, p3 как переменные соответствующего типа и приводит к выделению для них памяти. Описание же структуры без последующего списка переменных не выделяет никакой памяти. Оно только определяет форму сируктуры и действует как шаблон. Если такое описание снабжено ярлыком (именем типа), то его можно позже использовать при определении фактических экземпляров структуры. Например, используя указание выше описане anketa, можно с помощью строки struct anketa a0, a1 ,a2; описать структурные переменные a0, a1, a2, каждая из которых строится по шаблону, введенному структурой anketa. Любая переменная a0, a1, a2 содержит в строго определенном порядке элементы tab_nom, fio, data, pol, adres, summa. Все переменные , как и все остальные переменные языкаЮ получают места в памяти. |
Объявление структур.
12.1. Определение структуры
Структура – тип данных, задаваемый пользователем. В общем случае при работе со структурами следует выделить четыре момента:
- объявление и определение типа структуры,
- объявление структурной переменной,
- инициализация структурной переменной,
- использование структурной переменной.
Определение типа структуры представляется в виде
struct ID
{
<тип> <имя 1-го элемента>;
<тип> <имя 2-го элемента>;
…………
<тип> <имя последнего элемента>;
};
Определение типа структуры начинается с ключевого слова struct и содержит список объявлений, заключенных в фигурные скобки. За словом struct следует имя типа, называемое тегом структуры (tag – ярлык, этикетка). Элементы списка объявлений называются членами структуры или полями. Каждый элемент списка имеет уникальное для данного структурного типа имя. Однако следует заметить, что одни и те же имена полей могут быть использованы в различных структурных типах.
Определение типа структуры представляет собой шаблон (template), предназначенный для создания структурных переменных.
Объявление переменной структурного типа имеет следующий вид:
struct ID var1;
при этом в программе создается переменная с именем var1 типа ID. Все переменные, использующие один шаблон (тип) структуры, имеют одинаковый набор полей, однако различные наборы значений, присвоенные этим полям. При объявлении переменной происходит выделение памяти для размещения переменной. Шаблон структуры позволяет определить размер выделяемой памяти.
В общем случае, под структурную переменную выделяется область памяти не менее суммы длин всех полей структуры, например,
struct list
{
char name[20];
char first_name[40];
int;
}L;
В данном примере объявляется тип структура с именем list, состоящая из трех полей, и переменная с именем L типа struct list,при этом для переменной L выделяется 64 байта памяти.
Отметим, что определение типа структуры может быть задано в программе на внешнем уровне, при этом имя пользовательского типа имеет глобальную видимость (при этом память не выделяется). Определение типа структуры также может быть сделано внутри функции, тогда имя типа структуры имеет локальную видимость.
Создание структурной переменной возможно двумя способами: с использованием шаблона (типа) или без него.
Создание структурной переменной pt на основе шаблона выполняется следующим образом:
struct point //Определение типа структуры
{
int x;int y;
};
……
struct point pt; //Создание структурной переменной
Структурная переменная может быть задана уникальным образом:
struct //Определение анонимного типа структуры
{
char name[20];
char f_name[40];
char s_name[20];
} copymy; //Создание структурной переменной
При размещении в памяти структурной переменной можно выполнить ее инициализацию. Неявная инициализация производится для глобальных переменных, переменных класса static. Структурную переменную можно инициализировать явно при объявлении, формируя список инициализации в виде константных выражений.
Формат: struct ID name_1={значение1, … значениеN};
Внутри фигурных скобок указываются значения полей структуры, например,
struct point pt={105,17};
при этом первое значение записывается в первое поле, второе значение – во второе поле и т. д., а сами значения должны иметь тип, совместимый с типом поля.
Над структурами возможны следующие операции:
- присваивание значений одной структурной переменной другой структурной переменной, при этом обе переменные должны иметь один и тот же тип;
- получение адреса переменной с помощью операции &;
- осуществление доступа к членам структуры.
Присваивание значения одной переменной другой выполняется путем копирования значений соответствующих полей, например:
struct point pt={105,15},pt1;
pt1=pt;
В результате выполнения этого присваивания в pt1.x будет записано значение 105, а в pt1.y – число 15.
Работа со структурной переменной обычно сводится к работе с отдельными полями структуры. Доступ к полю структуры осуществляется с помощью операции. (точка) посредством конструкции вида:
имя_структуры.имя_поля_структуры;
при этом обращение к полю структуры представляет собой переменную того же типа, что и поле, и может применяться везде, где допустимо использование переменных такого типа.
Например,
struct list copy = {"Ivanov","Petr",1980};
Обращение к "Ivanov" имеет вид copy.name. И это будет переменная типа указатель на char. Вывод на экран структуры copy будет иметь вид: printf("%s%s%d\n",copy.name,copy.first_name,copy.i);
Структуры нельзя сравнивать. Сравнивать можно только значения конкретных полей.
Как правило, члены структуры связаны друг с другом по смыслу. Например, элемент списка рассылки, состоящий из имени и адреса логично представить в виде структуры. В следующем фрагменте кода показано, как объявить структуру, в которой определены поля имени и адреса. Ключевое слово struct сообщает компилятору, что объявляется (еще говорят, "декларируется") структура.
struct addr
{
char name[30];
char street[40];
char city[20];
char state[3];
unsigned long int zip;
};
Обратите внимание, что объявление завершается точкой с запятой, потому что объявление структуры является оператором. Кроме того, тег структуры addr идентифицирует эту конкретную структуру данных и является спецификатором ее типа.
Доступ к элементам структуры.
Доступ к элементам структуры.
Для обращения к отдельным элементам структуры используется операция обращения к члену структуры – “точка”. Она разделяет имя структурной переменной и имя поля, например
used_boat.year=1955;
printf(“%lf”,used_boat_price);
Элементы структуры обрабатываются также, как и любые другие переменные С, необходимо только использовать операцию “точка”.
Можно создавать массивы структур и указатели на структуру, для обращения к элементам структуры предусмотрен оператор “->” (стрелка, он состоит из знаков минус и больше).
sboat boat_array[10];
boat_array[3].year=1980;
sboat *pboat;
pboat=&used_boat;
pboat->price=12570.25;
Доступ к элементам структуры
Элементы структуры могут иметь модификаторы доступа: public, private и protected. По умолчанию все элементы структуры объявляются как общедоступные (public). Забегая вперед, следует сказать, что все члены класса по умолчанию объявляются как защищенные (private).
Для обращения к отдельным элементам структуры используются операторы: . и ->.
Доступ к элементам структуры может иметь следующее формальное описание:
переменная_структурного_типа.элемент_структуры=значение;
имя_структурного_типа *указатель_структуры=
& переменная_структурного_типа;
указатель_структуры->элемент_структуры=значение;
Например:
struct structA {
char c1;
char s1[4];
float f1;} aS1,
// aS1 - переменная структурного типа
*prtaS1=&aS1;
// prtaS1 - указатель на структуру aS1
struct structB {
struct structA aS2;
// Вложенная структура
} bS1,*prtbS1=&bS1;
aS1.c1= 'Е';
// Доступ к элементу c1 структуры aS1
prtaS1->c1= 'Е';
// Доступ к элементу c1 через
// указатель prtaS1
(*prtaS1).c1= 'Е';
// Доступ к элементу c1
(prtbS1->aS2).c1='Е';
// Доступ к элементу вложенной структуры
Доступ к элементу массива структурного типа имеет следующий формальный синтаксис:
имя_массива[индекс_элемента_массива].элемент_структуры
При использовании указателей на массив структур следует сначала присвоить указателю адрес первого элемента массива, а затем реализовывать доступ к элементам массива, изменяя этот указатель адреса.
Например:
struct structA {
int i; char c;} sA[4], *psA;
psA=&sA[0];
…
cout<<psA->i;
// Доступ к первому элементу массива
// структур
// Переход ко второму элементу массива
psA++;
// Эквивалентно записи: psA=&sA[1];
cout<<psA->i;
Примеры использования структур.
Пример:
#include <iostream>
using namespace std;
struct Vector2D{
double x;
double y;
}; // !!!!!
void Print(Vector2D V){
cout << "(" << V.x << ", " << V.y << ")";
}
int main(){
Vector2D Vector;
Vector.x = 1;
Vector.y = 2;
Print(Vector);
cout << endl;
return 0;
}
19.Структуры данных.
Структуры – это составные типы данных, построенные с использованием других типов.
Структура данных — программная единица, позволяющая хранить и обрабатывать множество однотипных и/или логически связанных данных в вычислительной технике. Для добавления, поиска, изменения и удаления данных структура данных предоставляет некоторый набор функций, составляющих её интерфейс. Структура данных часто является реализацией какого-либо абстрактного типа данных.
При разработке программного обеспечения большую роль играет проектирование хранилища данных и представление всех данных в виде множества связанных структур данных.
Хорошо спроектированное хранилище данных оптимизирует использование ресурсов (таких как время выполнения операций, используемый объём оперативной памяти, число обращений к дисковым накопителям), требуемых для выполнения наиболее критичных операций.
Структуры данных формируются с помощью типов данных, ссылок и операций над ними в выбранном языке программирования.
Различные виды структур данных подходят для различных приложений; некоторые из них имеют узкую специализацию для определённых задач. Например, B-деревья обычно подходят для создания баз данных, в то время как хеш-таблицы используются повсеместно для создания различного рода словарей, например, для отображения доменных имён в интернет-адреса компьютеров.
Структура - это набор данных, где данные могут быть разного типа. Например, структура может содержать несколько переменных типа int и несколько переменных типа char. Переменные, которые содержаться в структуре называются членами или полями структуры. Структуры можно определять с помощью ключевого слова struct.
Пример описания структуры:
struct student
{
char name[50];
int kurs;
int age;
};
Мы определили структуру в которую входят переменные kurs, age и массив name. В этом описании student является шаблоном структуры, struct student является типом данных. После описания структуры нужно ставить точку с запятой. Чтобы использовать структуру необходимо объявить переменные типа struct student.
Например,
struct student s1, s2;
Переменные s1 и s2 являются переменными типа struct student. Компилятор автоматически выделит память под эти переменные. Под каждую из переменных типа структуры выделяется непрерывный участок памяти.
Для получения доступа к полям структуры используется операция точка. Например,
strcpy(s1.name, "Бардин Павел");
s1.kurs=3;
s1.age=20;
В языке С есть возможность объявлять переменные структуры при описании структуры:
struct student
{
char name[50];
int kurs;
int age;
} s1, s2;
Переменные s1 и s2 являются переменными типа struct student.
Элементами или полями структуры могут быть переменные, массивы, ранее определенные структуры. Функции не могут быть полями структуры (В языке Си). В языке С++ функции могут быть полями структуры и такие структуры называются классами. Они определяются с помощью ключевого слова class.
Для переменных s1 и s2 возможно присваивание
s1=s2
так как эти переменные созданы на базе одного шаблона. После такого присваивания поля структуры s1 будут содержать ту же информацию, что и поля s2. Если мы опишем две структуры с одними и теми же полями, но первая структура будет иметь шаблон student1, а вторая student2, то присваивание s1=s2 недопустимо.
Стеки,
Стек (англ. stack — стопка) — структура данных, в которой доступ к элементам организован по принципу LIFO (англ. last in — first out, «последним пришёл — первым вышел»). Чаще всего принцип работы стека сравнивают со стопкой тарелок: чтобы взять вторую сверху, нужно снять верхнюю.
Добавление элемента, называемое также проталкиванием (push), возможно только в вершину стека (добавленный элемент становится первым сверху). Удаление элемента, называемое также выталкиванием (pop), тоже возможно только из вершины стека, при этом второй сверху элемент становится верхним.
Код:
class cStack
{
struct sItem // структура элемента
{
int Value; // значение
sItem *Prev; // указатель на предыдущий элемент
}
sItem *fItem; // рабочее поле
}
Стеком (англ. stack) называется хранилище данных, в котором можно работать только с одним элементом: тем, который был добавлен в стек последним. Стек должен поддерживать следующие операции:
push
Добавить (положить) в конец стека новый элемент
pop
Извлечь из стека последний элемент
back
Узнать значение последнего элемента (не удаляя его)
size
Узнать количество элементов в стеке
clear
Очистить стек (удалить из него все элементы)
Хранить элементы стека мы будем в массиве. Для начала будем считать, что максимальное количество элементов в стеке не может превосходить константы MAX_SIZE, тогда для хранения элементов массива необходимо создать массив размера MAX_SIZE.
Объявим структуру данных типа stack.
const int MAX_SIZE=1000;
struct stack {
int m_size; // Количество элементов в стеке
int m_elems[MAX_SIZE]; // Массив для хранения элементов
stack(); // Конструктор
~stack(); // Деструктор
void push(int d); // Добавить в стек новый элемент
int pop(); // Удалить из стека последний элемент
// и вернуть его значение
int back(); // Вернуть значение последнего элемента
int size(); // Вернуть количество элементов в стеке
void clear(); // Очистить стек
};
Объявленная здесь структура данных stack реализует стек целых чисел. Поле структуры m_size хранит количество элементов в стеке в настоящее время, сами элементы хранятся в элементах массива m_elems с индексами 0..m_size-1. Элементы, добавленные позже, получают большие номера.
Упражнение A - простой стек
Реализуйте структуру данных "стек", реализовав все указанные здесь методы. Напишите программу (функцию main), содержащую описание стека и моделирующую работу стека. Функция main считывает последовательность команд и в зависимости от команды выполняет ту или иную операцию. После выполнения одной команды программа должна вывести одну строчку. Возможные команды для программы:
push n
Добавить в стек число n (значение n задается после команды). Программа должна вывести ok.
pop
Удалить из стека последний элемент. Программа должна вывести его значение.
back
Программа должна вывести значение последнего элемента, не удаляя его из стека.
size
Программа должна вывести количество элементов в стеке.
clear
Программа должна очистить стек и вывести ok.
exit
Программа должна вывести bye и завершить работу.
Гарантируется, что набор входных команд удовлетворяет следующим требованиям: максимальное количество элементов в стеке в любой момент не превосходит 100, все команды pop_back и back корректны, то есть при их исполнении в стеке содержится хотя бы один элемент.
Пример протокола работы программы
Ввод Вывод
push 2 ok
push 3 ok
push 5 ok
back 5
size 3
pop 5
size 2
push 7 ok
pop 7
clear ok
size 0
exit bye
очереди,
Очередью (aнгл. queue)) называется структура данных, в которой элементы кладутся в конец, а извлекаются из начала. Таким образом, первым из очереди будет извлечен тот элемент, который будет добавлен раньше других.
Элементы очереди будем также хранить в массиве. При этом из очереди удаляется первый элемент, и, чтобы не сдвигать все элементы очереди, будем в отдельном поле m_start хранить индекс элемента массива, с которого начинается очередь. При удалении элементов, очередь будет "ползти" дальше от начала массива. Чтобы при этом не происходил выход за границы массива, замкнем массив в кольцо: будем считать, что за последним элементом массива следует первый.
Описание структуры очередь:
const int MAX_SIZE=1000;
struct queue {
int m_size; // Количество элементов в очереди
int m_start; // Номер элемента, с которого начинается очередь
int m_elems[MAX_SIZE]; // Массив для хранения элементов
queue(); // Конструктор
~queue(); // Деструктор
void push(int d); // Добавить в очередь новый элемент
int pop(); // Удалить из очереди первый элемент
// и вернуть его значение
int front(); // Вернуть значение первого элемента
int size(); // Вернуть количество элементов в очереди
void clear(); // Очистить очередь
};
деревья.
Цель: изучить фундаментальную абстрактную структуру - дерево
Структуры, которые мы прежде обсуждали были одномерные: в них один элемент следует за другим. Сегодня мы сосредоточим наше внимание на двухмерных связанных структурах называемых деревьями, на которых основаны многие из наиболее важных алгоритмов. Полное описание деревьев могло бы занять не одну книгу, потому что они возникают во многих задачах, даже вне информатики, и довольно интенсивно изучаются как математический объект. Сегодня мы рассмотрим основные определения и терминологию связанную с деревьями, изучим некоторые их свойства, и обсудим способы из компьютерной реализации. Позднее, мы встретим множество алгоритмов использующих эту структуру данных.
В повседневной жизни мы очень часто встречаем примеры деревьев, и Вы уже наверняка знакомы с этой концепцией.
Например, люди часто используют генеалогическое дерево для изображения структуры своего рода; как мы увидим, много терминов, связанных с деревьями, взято именно отсюда.
Второй пример - это структура большой организации; использование древообразной структуры для представления ее "иерархической структуры" ныне широко используется во многих компьютерных задачах.
Третий пример - это грамматическое дерево; изначально оно служило для грамматического анализа компьютерных программ, а ныне широко используется и для грамматического анализа литературного языка.
Мы начнем изучение деревьев с того, что определим их как некий абстрактный объект и введем всю связанную с ними терминологию.
Самые простые из деревьев считаются бинарные деревья.
Бинарное дерево-это конечное множество элементов, которое либо пусто, либо содержит один элемент, называемый корнем дерева, а остальные элементы множества делятся на два непересекающихся подмножества, каждое из которых само является бинарным деревом.
Эти подмножества называются левым и правым поддеревьями исходного дерева.
Каждый элемент бинарного дерева называется узлом дерева.
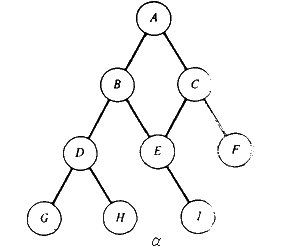
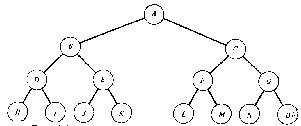
|

На рисунке показан общепринятый способ изображения бинарного дерева. Это дерево состоит из девяти узлов, А-корень дерева. Его левое поддерево имеет корень В, а правое- корень С. Это изображается двумя ветвями, исходящими из А: левым - к В и правым - к С. Отсутствие ветви обозначает пустое поддерево. Например, левое поддерево бинарного дерева с корнем С и правое поддерево бинарного дерева с корнем Е оба пусты. Бинарные деревья с корнями D, G, Н и I имеют пустые левые и правые поддеревья.
|
|
|
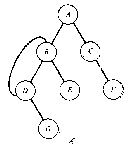
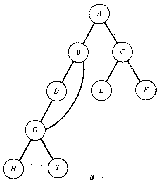
На рисунке приведены некоторые структуры, не являющиеся бинарными деревьями.
Если А - корень бинарного дерева и В - корень его левого или правого поддерева, то говорят, что А-отец В, а В-левый или правый сын А.
Узел, не имеющий сыновей (такие как узлы D, G, Н и I), называется листом.
Узел nl -предок узла n2 (а n2-потомок nl), если nl-либо отец n2, либо отец некоторого предка n2. Например, в дереве из рисунке А-предок G и Н-потомок С, но Е не является ни предком, ни потомком С.
Узел n2-левый потомок узла n1, если n2 является либо левым сыном n1, либо потомком левого сына n1. Похожим образом может быть определен правый потомок.
Два узла являются братьями, если они сыновья одного и того же отца. Если каждый узел бинарного дерева, не являющийся листом, имеет непустые правые и левые поддеревья, то дерево называется строго бинарным деревом.
|
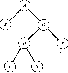
Свойство 1. Строго бинарное дерево с n листами всегда содержит 2n-1 узлов.
Уровень узла в бинарном дереве может быть определен следующим образом. Корень дерева имеет уровень 0, и уровень любого другого узла дерева имеет уровень на 1 больше уровня своего отца.
Например, в бинарном дереве на первом рисунке узел Е- узел уровня 2, а узел Н-уровня 3.
Глубина бинарного дерева-это максимальный уровень листа дерева, что равно длине самого длинного пути от корня к листу дерева.
Стало быть, глубина дерева на первом рисунке равна 3.
Полное бинарное дерево уровня n - это дерево, в котором каждый узел уровня n является листом и каждый узел уровня меньше n имеет непустые левое и правое поддеревья
|
На рисунке приведен пример полного бинарного дерева уровня 3.
|
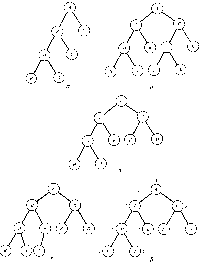
Почти полное бинарное дерево - это бинарное дерево, для которого существует неотрицательное целое k такое, что
1. Каждый лист в дереве имеет уровень k или k+1.
2. Если узел дерева имеет правого потомка уровня k+1, тогда все его левые потомки, являющиеся листами, также имеют уровень k+1.
Строго бинарное дерево из рис. а не является почти полным, поскольку оно содержит листы уровней 1, 2 и 3, нарушая тем самым условие 1.
Строго бинарное дерево на рис. 6 удовлетворяет условию 1, так как каждый лист имеет уровень 2 или 3. Однако при этом нарушается условие 2, поскольку А имеет не только правого потомка уровня 3 (J), но также и левого потомка, являющегося листом уровня 2 (Е).
Строго бинарное дерево на рис. в удовлетворяет обоим условиям и, следовательно, является почти полным бинарным деревом.
Бинарное дерево на рис. г-также почти полное бинарное дерево, но оно не является строго бинарным, поскольку узел Е имеет лишь левого сына.
Узлы почти полного бинарного дерева могут быть занумерованы так, что корню назначается номер 1, левому сыну-удвоенный номер его отца, а правому-удвоенный номер отца плюс единица (намного проще это понять, если представить эти числа в двоичной системе).
Есть еще одна разновидность бинарных деревьев, которая называется упорядоченные бинарные деревья.
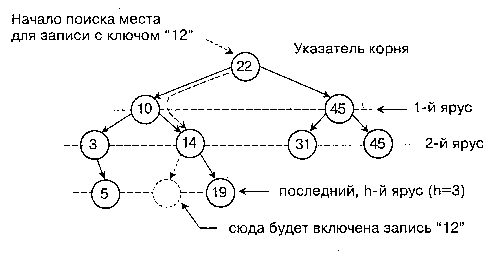
Упорядоченные бинарные деревья - это деревья, в которых для каждого узла Х выполняется правило: в левом поддереве - ключи, меньшие Х, в правом поддереве - большие или равные Х.
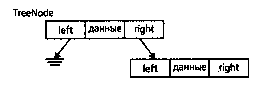
Структура бинарного дерева построена из узлов.
Узел дерева содержит поле данных и два поля с указателями.
|
Поля указателей называются левым указателем и правым указателем, поскольку они указывают на левое и правое поддерево, соответственно. Значение nil является признаком пустого дерева.
Тогда бинарное дерево можно будет представить в следующем виде.
|
|
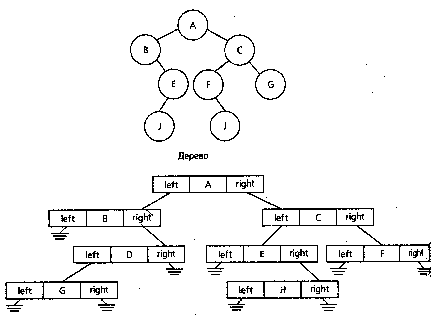
Над бинарным деревом есть операция - его прохождение, т.е. нужно обойти все дерево, отметив каждый узел один раз.
Существует 3 способа обхода бинарного дерева.
в прямом порядке
в симметричном порядке
в обратном порядке