

3 ВОПРОС
Представление информации в ЭВМ.
Двоичное кодирование
В какой бы форме не представлялась подлежащая обработке информация, она должна быть переведена компьютером на язык, доступный для автоматической обработки. Язык компьютера – это язык чисел, причем не обычных (десятичных), а двоичных, алфавит которых состоит всего лишь из двух цифр – 0 и
1. Двоичная система наиболее проста и удобна для обработки на ЭВМ, т. к. компьютер – электрическая машина и работает с электрическими сигналами: есть сигнал – включено, нет сигнала – выключено.
В современной вычислительной технике информация как раз и кодируется с помощью сиг-налов двух видов: включено или выключено. Все входные сигналы, поступающие в компьютер, преобразуются в нули и единицы, при этом 0 означает отсутствие тока (нет сигнала, т. е. выклю-чено), а 1 – присутствие тока в цепи (есть сигнал, т. е. включено). Принято обозначать одно со-стояние цифрой 0, а другое – цифрой 1. Такое кодирование называется двоичным, а цифры 0 и 1 называются битами (от англ. bit – binary digit – двоичная цифра).
На этом простом принципе и основана работа ЭВМ. Любая информация в компьютере мо-жет быть представлена в виде последовательности двоичных символов – бит.
Представление текстовой информации
При двоичном кодировании текстовой информации каждому символу соответствует его код – последовательность из 8 нулей и единиц, называемая байтом. Всего существует 256 разных последовательностей из 8 нулей и единиц. Это позволяет закодировать 256 символов, например большие и малые буквы латинского и русского алфавитов, цифры, знаки препинания, специаль-ные символы, пробел и т. д.
Соответствие байтов и символов задается с помощью таблицы кодировки, в которой уста-навливается взаимосвязь между символами и их порядковыми номерами в компьютерном алфави-те. Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответ-ствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код есть порядковый но-мер символа в двоичной системе счисления. Для разных типов ЭВМ используются различные таблицы кодировки. С распространением персональных компьютеров типа IBM PC международным стандартом стала таблица кодировки под названием ASCII (American Standard Code for Information Interchange) – Американский стан-дартный код для информационного обмена.
Стандартными в этой таблице являются только первые 128 символов, т. е. символы с номе-рами от 0 (двоичный код 000000000) до 127 (двоичный код 01111111). Сюда входят буквы латин-ского алфавита, цифры, знаки препинания, скобки и некоторые другие символы. остальные 128 кодов, начиная с 128 (двоичный код 10000000) и кончая 255 (двоичный код 11111111), использу-ются для кодировки букв национальных алфавитов, символов псевдографики и научных симво-лов. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита.
Принцип последовательного кодирования алфавита: в кодовой таблице ASCII латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений. Данное правило соблюдается и других таблицах кодиров-ки (КОИ-8). Благодаря этому и в машинном представлении для символьной информации сохраня-ется понятие «алфавитный порядок». Из всего вышесказанного следует, что когда вы нажимаете клавишу с буквой L на клавиа-туре ПК, центральный процессор получает команды из восьми сигналов: выключить – включить – выключить – выключить – включить – включить – выключить – выключить. Если учесть чрезвы-чайно высокое быстродействие компьютера, то станет очевидным, что для отображения на экране буквы практически не требуется никакого времени. ASCII или UNICODE
Для кодирования необходимо описать базовые информационные объекты. Для этого необ-ходимо создать модель интересующей информации.
В отношении текстовой информации решили отделить ее внешнее представление от со-держательного смысла. Это существенно облегчило задачу: осталось выписать все возможные знаки, которые могут быть использованы для написания любого текста, и поставить в соответст-вие каждому из них число. Таким образом, в качестве элементарного информационного объекта приняли текстовый знак. В список используемых знаков включили все, что сумели найти на клавиатуре англоязыч-ной пишущей машинки- она оказалась лучшей моделью для законодателей компьютерной моды. Список лишь слегка расширили с учетом специфики компьютера. Поскольку компьютер работает с числами в двоичной системе, которые традиционно груп-пируют по 8 разрядов, решили в получившейся таблице использовать сразу двоичные 8-разрядные числа. Часто такие таблицы состоят из 3-х колонок, чтобы можно было видеть сразу и двоичный код, и привычный 10-чный. Текстовых знаков в таблице оказалось 128, а в 8-разрядное двочное число можно закоди-ровать 256 знаков. Это позволило учесть то, о чем не могли заранее подумать изобретатели коди-рования. Различные варианты заполнения свободной части таблицы привели к похожим, но не-сколько отличающимся стандартам. В настоящее время наиболее известный вариант такой табли-цы называется ASCII. Той же частью таблицы смогли воспользоваться программисты других стран, которым невоз-можно было обойтись без английского алфавита, но и родной язык было бы странно не использо-вать. Поскольку такие модернизации таблицы никем жестко не контролировались, появилось не-сколько вариантов кодирования национальных языков. В частности, для русского языка сущест-вует несколько кодировок, которые использовались в различных операционных системах, напри-мер: • 866 (в среде DOS) • win-1251 (в среде Windows) • mac-cyrilic (в среде Macintosh) • koi-8r (в среде UNIX) Кириллица - не самый сложный вариант: в ней только 33 буквы, что чуть больше латиницы (26), но даже с ней были сложности. По мере развития информационных технологий (ИТ) возникли новые вопросы: • Как быть с абсолютно другими по системе кодирования языками, например, китайским? • Как разработанные в одной стране программы использовать в другой? • Можно ли разрабатывать многоязычные словари?
КОДИРОВАНИЕ СИМВОЛОВ. ВИДЫ КОДИРОВОК. ТАБЛИЦЫ ASCII. UNICODE
Можно ли считать выражение лица кодировкой мыслей?
А. Алешин
Помимо цифр, на мониторы ЭВМ необходимо выводить еще и множество символов. Ясно, что для вывода каждого символа необходим некий машинный код, однозначно соответствующий этому символу, или некое правило, по которому можно организовать корректный вывод каждого символа на дисплей. Разумеется, разрабатывать такую систему ввода-вывода следует оптималь-ным образом с точки зрения потребления ресурсов компьютера. Особенно важно в этом случае помнить о том, что производительность компьютеров в отдаленные времена зарождения вычис-лительной техники была ничтожной, с современных позиций, а системные программисты и раз-работчики аппаратной части боролись за каждый бит, адрес, инструкцию, регистр, освобождая оперативную память и адресное пространство компьютерных "малышей". Давайте подсчитаем, сколько необходимо символов для вывода информации на дисплей. Исторически сложилось так, что первые разработчики компьютеров были носителями английско-го языка. Что им было необходимо обеспечить для вывода на монитор? Во-первых, 26 букв анг-лийского алфавита (строчных), во-вторых, 26 прописных, 9 знаков препинания (. , : ! " ; ? ( ) ), пробел, 10 цифр, 5 знаков арифметических действий (+,-,*, /, ^) и специальные символы (№ % _ # $, и так далее ^, &, >, <, |, \). Получается чуть больше сотни символов. Такой сравнительно не-большой базовый набор символов можно закодировать при помощи таблиц соответствия этого набора машинным кодам (фактически, двоичным числам). Можно вполне ограничиться набором двоичных чисел от 0 до 27 (всего 128 позиций), что и было сделано. Таблица соответствия полу-чила название ASCII (American Standard Code for Information Interchange). В рамках таблицы ASCII создание многоязычных документов являлось очень проблематичной, а в большинстве случаев и совершенно невыполнимой задачей. Однако базового набора кодов стало быстро не хватать. Возросший дефицит знакомест в стандартной таблице ASCII потребовал ее немедленного расширения. В результате возникла но-вая таблица кодировок, получившая название "расширенная таблица ASCII", число знакомест в которой возросло до 28 (256 знакомест). Эта таблица получила название международного стандар-та IS 646, а восьмибитный код - Latin-1. В него были добавлены в основном латинские буквы со штрихами и диакритические символы. Вскоре появился новый стандарт IS 8859, в котором вводи-лось понятие "кодовая страница", т.е. набор из 256 символов для определения языка или группы языков, т.е. IS 8859-1 это Latin-1, IS 8859-2 включал славянские языки с латинским алфавитом (чешский, польский, вергерский), IS 8859-3 включал турецкий, мальтийский, эсперанто, галисий-ский языки, и т.д. Недостатком такого подхода является то, что программное обеспечение должно следить за кодовыми страницами, смешивать языки при этом невозможно, кроме того не были созданы кодовые страницы японского и китайского языков.
UNICODE
В январе 1991 года возник консорциум UNICODE, целью которого является продвижение, развитие и реализация стандарта Unicode как международной системы кодирования для обмена информацией, а также поддержание качества этого стандарта в будущих версиях.
Стандарт UNICODE 4.0 представляет собой новую систему кодирования символов, выво-димых на экран монитора или на принтер, позволяющую закодировать 1 114 112 символов (в стандарте из принято называть code points). Большинство символов, используемых в основных языках мира занимают 65 536 code points, образуя Basic Multilingual Plane (BMP) (Основной Мно-гоязычный Уровень - мой перевод). Оставшиеся (более миллиона) code points вполне достаточно для кодирования всех известных символов, включая малораспространенные языки и исторические знаки. Стандарт UNICODE поддерживается тремя формами, 32-битной (UTF-32), 16-битной (UTF-16) и 8-битной (UTF-8). Восьмибитная форма UTF-8 была разработана для удобной совмес-тимости с ASCII-ориентироваными системами кодирования. Стандарт UNICODE совместим с Международным стандартом International Standard ISO/IEC 10646. Наиболее просто устроена форма UTF-32. В ней каждый символ закодирован при помощи 32-битного блока. Благодаря этому каждый символ UTF-32 обладает однозначным соответствием между декодированным символом и блоком кода. Это форма имеет фиксированную длину знако-места. Она покрывает все кодовое пространство UNICODE - 0...10FFFF16. Это гарантирует пол-ную совместимость с UTF-16 и UTF-8. Форма UTF-32 является наиболее предпочитаемой для большинства UNIX платформ. Стандарт UNICODE содержит 96 382 символа, взятых их мировых шрифтов. Этих симво-лов более чем достатонно для общения на всех известных языках мира, а также для написания классических (исторических ) шрифтов многих языков. UNICODE всключает в себя шрифты ев-ропейских алфавитов, средне-азиатское письмо, направленное справа на лево, шрифты Азии, и многие другие. Подмножество символов (code points) HUN включает 70 207 идеографических символов определяемых по национальным и промышленным стандартам Китая, Японии, Кореи, Тайвани, Вьетнама и Сингапура. Более того, UNICODE содержит знаки пунктуации, математиче-ские символы, технические символы, герметрические фотмы и графические метки (dingbats), фо-нетические знаки.
4 Вопрос
Система счисле́ния — символический метод записи чисел, представление чисел с помощью письменных знаков.
Система счисления:
даёт представления множества чисел (целых и/или вещественных);
даёт каждому числу уникальное представление (или, по крайней мере, стандартное представление);
отражает алгебраическую и арифметическую структуру чисел.
Системы счисления подразделяются на позиционные, непозиционные и смешанные.
Чем больше основание системы счисления, тем меньшее количество разрядов (то есть записываемых цифр) требуется при записи числа в позиционных системах счисления.
[Править]Позиционные системы счисления
Основная статья: Позиционная система счисления
В позиционных системах счисления один и тот же числовой знак (цифра) в записи числа имеет различные значения в зависимости от того места (разряда), где он расположен. Изобретение позиционной нумерации, основанной на поместном значении цифр, приписывается шумерам ивавилонянам; развита была такая нумерация индусами и имела неоценимые последствия в истории человеческой цивилизации. К числу таких систем относится современная десятичная система счисления, возникновение которой связано со счётом на пальцах. В средневековой Европе она появилась через итальянских купцов, в свою очередь заимствовавших её у мусульман.
Под позиционной системой счисления обычно понимается b-ричная система счисления, которая определяется целым числом b > 1, называемым основанием системы счисления. Целое число x в b-ричной системе счисления представляется в виде конечной линейной комбинации степеней числа b:
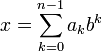 ,
где ak —
это целые числа, называемые цифрами,
удовлетворяющие неравенству
,
где ak —
это целые числа, называемые цифрами,
удовлетворяющие неравенству ![]() .
.
Каждая степень bk в такой записи называется весовым коэффициентом разряда. Старшинство разрядов и соответствующих им цифр определяется значением показателя k(номером разряда). Обычно для ненулевого числа x требуют, чтобы старшая цифра an − 1 в его b-ричном представлении была также ненулевой.
Если не возникает разночтений (например, когда все цифры представляются в виде уникальных письменных знаков), число x записывают в виде последовательности его b-ричных цифр, перечисляемых по убыванию старшинства разрядов слева направо:
![]()
Например, число сто три представляется в десятичной системе счисления в виде:
![]()
Наиболее употребляемыми в настоящее время позиционными системами являются:
1 — единичная[1] (счёт на пальцах, зарубки, узелки «на память» и др.);
2 — двоичная (в дискретной математике, информатике, программировании);
3 — троичная;
8 — восьмеричная;
10 — десятичная (используется повсеместно);
12 — двенадцатеричная (счёт дюжинами);
16 — шестнадцатеричная (используется в программировании, информатике);
60 — шестидесятеричная (единицы измерения времени, измерение углов и, в частности, координат, долготы и широты).
[Править]Смешанные системы счисления
Смешанная
система счисления является
обобщением b-ричной
системы счисления и также зачастую
относится к позиционным системам
счисления. Основанием смешанной системы
счисления является возрастающая последовательность
чисел ![]() ,
и каждое число x в
ней представляется как линейная
комбинация:
,
и каждое число x в
ней представляется как линейная
комбинация:
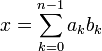 ,
где на коэффициенты ak,
называемые как и прежде цифрами,
накладываются некоторые ограничения.
,
где на коэффициенты ak,
называемые как и прежде цифрами,
накладываются некоторые ограничения.
Записью числа x в смешанной системе счисления называется перечисление его цифр в порядке уменьшения индекса k, начиная с первого ненулевого.
В зависимости от вида bk как функции от k смешанные системы счисления могут быть степенными, показательными и т. п. Когда bk = bk для некоторого b, смешанная система счисления совпадает с b-ричной системой счисления.
Наиболее
известным примером смешанной системы
счисления являются представление
времени в виде количества суток, часов,
минут и секунд. При этом величина
«d дней,h часов, m минут, s секунд»
соответствует значению ![]() секунд.
секунд.
[править]Факториальная система счисления
В факториальной системе счисления основаниями являются последовательность факториалов bk = k!, и каждое натуральное число x представляется в виде:
![]() ,
где
,
где ![]() .
.
[править]Фибоначчиева система счисления
Основная статья: Фибоначчиева система счисления
Фибоначчиева система счисления основывается на числах Фибоначчи. Каждое натуральное число x в ней представляется в виде:
![]() ,
где Fk —
числа Фибоначчи,
,
где Fk —
числа Фибоначчи, ![]() ,
при этом в записи
,
при этом в записи ![]() не
встречается две единицы подряд.
не
встречается две единицы подряд.
[править]Непозиционные системы счисления
В непозиционных системах счисления величина, которую обозначает цифра, не зависит от положения в числе. При этом система может накладывать ограничения на положение цифр, например, чтобы они были расположены в порядке убывания.
[править]Биномиальная система счисления
Представление, использующее биномиальные коэффициенты
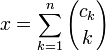 ,
где
,
где ![]() .
.
[править]Система остаточных классов (СОК)
Представление
числа в системе остаточных классов
основано на понятии вычета и китайской
теореме об остатках.
СОК определяется набором взаимно
простых модулей ![]() с
произведением
с
произведением ![]() так,
что каждому целому числу x из
отрезка [0,M −
1] ставится
в соответствие набор вычетов
так,
что каждому целому числу x из
отрезка [0,M −
1] ставится
в соответствие набор вычетов ![]() ,
где
,
где
![]()
![]()
…
![]()
При этом китайская теорема об остатках гарантирует однозначность представления для чисел из отрезка [0,M − 1].
В СОК арифметические операции (сложение, вычитание, умножение, деление) выполняются покомпонентно, если про результат известно, что он является целочисленным и также лежит в [0,M − 1].
Недостатками
СОК является возможность представления
только ограниченного количества чисел,
а также отсутствие эффективных алгоритмов
для сравнения чисел, представленых в
СОК. Сравнение обычно осуществляется
через перевод аргументов из СОК в
смешанную систему счисления по
основаниям ![]() .
.