

Основные схемы данных типа «объект-признак»
Характерной
особенностью данных типа «объект-признак»
является то, что формирование матрицы
связано со временем. В связи с этим
различют несколько схем матрицы данных
«объект-признак». Если наблюдения
признаков осуществляются с неизменным
сдвигом по времени, то получаем синхронную
схему. Частным
случаем синхронной схемы являются
данные, полученные одномоментно. Под
моментом времени понимаем такой короткий
период, в течение которого не может
произойти изменение отклика объекта.
Матрица синхронных данных представлена
на рис. 1.2.
В
этой схеме для п
объектов
![]() фиксируются
значения т
признаков
фиксируются
значения т
признаков
![]() приблизительно
в одно и то же время.
приблизительно
в одно и то же время.
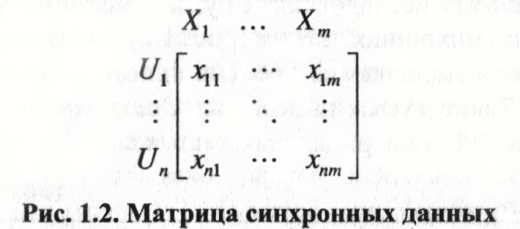
В
синхронной схеме признаки так соотносятся
между собой, что со-ответствующие
процессы совершаются с неизменным
сдвигом. Величина этого сдвига зависит
и от решаемой задачи. Например, в задаче
идентификации статических характеристик
сложного динамического
объекта с
помощью множественного регрессионного
анализа измерение всех признаков
(входов
и выходов) в один и тот же момент времени
t
не обеспечивает синхронной матрицы
статических данных. Рассмотрим простейший
случай идентификации объекта с входами
X
=
![]() и
с одним выходом Y
= Хт.
По
наблюдениям
и
с одним выходом Y
= Хт.
По
наблюдениям
![]() и нужно найти оценку уравнения регрессии
и нужно найти оценку уравнения регрессии
![]() .
(1.2)
.
(1.2)
В
этой задаче значение отклика Y
определяется не только мгновенными
значениями входов в момент времени
измерения, но и всей их предысторией
до этого момента. Поэтому для получения
синхронных данных нужно учесть динамику
исследуемого объекта по каждому из
каналов
![]() .
.
Приближенное решение задачи синхронизации наблюдений в данном случае можно получить заменой динамического звена каждого канала звеном чистого запаздывания. Тогда вместо формулы (1.2) получаем
![]() ,
,
где
![]() -
величина чистого запаздывания по j-му
каналу определяется по корреляционному
сдвигу, соответствующему максимуму
взаимной корреляционной функции
-
величина чистого запаздывания по j-му
каналу определяется по корреляционному
сдвигу, соответствующему максимуму
взаимной корреляционной функции
![]() между выходом и соответствующим входом.
После определения всех
между выходом и соответствующим входом.
После определения всех
![]() нужно
в эксперименте измерять каждый вход с
опережением на величину
относительно исследумого момента t
для
Y.
Таким образом, в задаче идентификации
статики объекта с множеством входов
выход синхронизируется с каждым входом
нужно
в эксперименте измерять каждый вход с
опережением на величину
относительно исследумого момента t
для
Y.
Таким образом, в задаче идентификации
статики объекта с множеством входов
выход синхронизируется с каждым входом
![]() с
постоянным опережением
относительно
момента времени измерения выхода Y.
Отметим,
что рассмотренная синхронизация матрицы
данных необходима и при оценке
корреляционной матрицы данных.
с
постоянным опережением
относительно
момента времени измерения выхода Y.
Отметим,
что рассмотренная синхронизация матрицы
данных необходима и при оценке
корреляционной матрицы данных.
В большинстве исследований оказывается, что некоторые значения X были получены в различное время, тогда предпринимаются действия для устранения этого влияния, например, случайным образом определяется порядок, в котором будут опрошены люди.
При более точных исследованиях нужно учесть изменение данных от времени. Тогда к синхронной схеме (рис. 1.2) добавляются еще три схемы, учитывающие изменения во времени одного или нескольких признаков и объектов. Такие схемы называются диахронными. Виды этих схем приведены в табл. 1.2, а матрицы диахронных схем на рис. 1.3 [14, гл. 1].
Таблица 1.2. Виды схем
Схема |
Название |
Число объектов |
Число переменных |
Число моментов времени |
0 1
2
3 |
Синхронная Диахронная, одна переменная Диахронная, один объект Полная |
Несколько Несколько
Один
Несколько |
Несколько Одна
Несколько
Несколько |
Один Несколько
Несколько
Несколько |
В схеме 1 один и тот же признак замеряется в различные моменты времени, в схеме 2 измерения проводятся в различные моменты времени для одного объекта, в схеме 3 измерения повторяются в различные заданные времена для всей матрицы данных.
Схема 3 является обобщением остальных трех схем, и в соответствии с ней п объектов описываются т признаками в р различных моментов времени (для нее надо птр значений). Данные не всегда собираются по этой схеме, так как она требует больших затрат времени, энергии и средств. Поэтому при анализе процессов во времени вынуждены иметь дело со схемой 1 или схемой 2. Выбор одной из них определяется целью, которая используется при анализе.

Временные
ряды. Простейшим
способом анализа по одной переменной,
т. е. одномерного
диахронного анализа (ОДА), было
бы отделение либо одной строки в схеме
1 (рис. 1.3), либо одного столбца в схеме
2. Получаем обычный временной
ряд
![]() ,
причем каждому из моментов времени
,
причем каждому из моментов времени
![]() соответствует
фиксированное значение переменной Х
для фиксированного объекта U.
Эти
данные являются предметом исследований
теории
временных рядов. Схему
ОДА
можно
расширить, введя в рассмотрение не один,
а два и более объектов.
соответствует
фиксированное значение переменной Х
для фиксированного объекта U.
Эти
данные являются предметом исследований
теории
временных рядов. Схему
ОДА
можно
расширить, введя в рассмотрение не один,
а два и более объектов.
Результаты анализа по одной переменной для разных объектов не всегда можно сравнивать непосредственно, потому что процессы по-разному соотнесены со шкалой времени. Например, в социальной сфере и в биологии некоторые объекты изменяются «быстрее», чем другие. Иначе говоря, социальное или биологическое время - не то же самое, что и хронологическое. Следовательно, первой задачей может явиться построение временных рядов для объектов так, чтобы ряды были сравнимыми, т. е. рядов по социальному или биологическому, а не хронологическому времени [14].
Пример 1.5. Исследуя рост растений, Торнвейт пришел к выводу о непригодности астрономического времени к измерению скорости роста. Биологические часы он обнаружил в горохе. В качестве единицы измерения времени он использовал промежуток между появлениями соседних узлов на стебле гороха. Эти промежутки имели различную длительность в астрономических единицах времени, но с их помощью удавалось лучше предсказывать урожай и управлять его сбором, чем при использовании астрономического времени.
В рассмотренных примерах время - это функциональное понятие. Сравнение объектов можно осуществить путем оценки параметров уравнения регрессии из некоторого семейства (линейной, логарифмической, логистической) на плоскости (t, X) которая аппроксимирует траекторию объекта, а затем, преобразовав параметры уравнений, привести траектории к общему временному базису. Выполнив преобразования, можно построить новые графики уже на плоскости (t*, X), где t* - функциональное время.
После выполнения преобразования нужно разброс точек проанализи- ровать статистическими методами и определить, насколько точно объекты следуют постулированной зависимости между функциональным временем и X. Если зависимые переменные измеряются в шкале интервалов, то часто можно использовать стандартные статистические процедуры регрессионного, логит и пробит анализов. Полученные уравнения мог быть использованы для проверки тех или иных гипотез.
Таким образом, с помощью ОДА можно ответить на вопросы связан- ные с анализом данных типа тех, которые фигурируют в схеме 1: данные о нескольких объектах по одной переменной, измеряемой в различные моменты времени. Они пригодны для статистического анализа, но лишь после того, как произведены некоторые преобразования, связанные с отсчетом времени. Эти преобразования нетривиальны и во много зависят от типа шкалы измерения и решаемой задачи [8, 16].
Большинство задач, связанных с временными рядами, решается в рамках корреляционной теории. Чаще всего взаимная корреляционная функция между двумя центрированными переменными х(t) и у(t) вычисляется по прямому выборочно-шаговому алгоритму [5]
![]() ,
(1.4)
,
(1.4)
где
![]() -
шаг дискретности корреляционного сдвига
-
шаг дискретности корреляционного сдвига
![]() ;
;
![]() -
шаг дискретности отбора выборочных пар
-
шаг дискретности отбора выборочных пар
![]() определенным образом связанный с
величинами
определенным образом связанный с
величинами
![]() ,
,
![]() ,
,
![]() ;
;
![]() ,
,
![]() .
Если в формуле (1.4), то получаем
автокорреляционную функцию (АКФ). В
зависимости от соотношения между
.
Если в формуле (1.4), то получаем
автокорреляционную функцию (АКФ). В
зависимости от соотношения между
![]() и
можно получить различные виды
выборочно-шаговых алгоритмов. Выборка
пар
и
можно получить различные виды
выборочно-шаговых алгоритмов. Выборка
пар
![]() называется максимально коррелированной,
если
называется максимально коррелированной,
если
![]() ,
и некоррелированной, если
,
и некоррелированной, если
![]() (
(![]() -
максимальный из интервалов корреляции
переменных х(t)
и
у(t)).
-
максимальный из интервалов корреляции
переменных х(t)
и
у(t)).
Наблюдения
временных рядов часто содержат пропуски.
Для к
>0
и
максимально коррелированной выборки
любые пропуски при нахождении
ковариационных функций недопустимы,
т. е. пропуски неигнорируемы.
В
этом случае при вычислении ковариационных
функций нужно выбирать величины
такой кратности значениям
![]() ,
чтобы полученная парная
не содержала пропущенные значения.
Например, если ряд
содержит
пропуски, то величины
,
нужно выбрать так, как это показано на
рис. 1.4 для
,
чтобы полученная парная
не содержала пропущенные значения.
Например, если ряд
содержит
пропуски, то величины
,
нужно выбрать так, как это показано на
рис. 1.4 для
![]() .
На рис. 1.4 пары, отбираемые для вычисления
.
На рис. 1.4 пары, отбираемые для вычисления
![]() ,
изображены
жирной линией.
,
изображены
жирной линией.
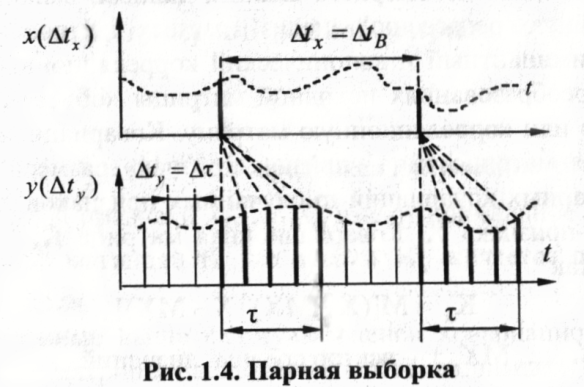
Из
рисунка ясно, что пропущенные значения
ряда должны располагаться в интервале
![]() .
.