

16. Построение дерева синтаксического разбора.
Дерево разбора может рассматриваться как графическое представление порождения, из которого удалена информация о порядке замещения не терминалов.
Каждый внутренний узел дерева представляет применение продукции.
Внутренний узел дерева помечен нетерминалом А из заголовка соответствующей продукции, а дочерние узлы слева направо символами из тела продукции, использованные в порождении для замены А.
Например, дерево для разбора – (id+id):
E
/ \
- E
/ | \
( E )
/ | \
E + E
| |
id id
Листья дерева разбора не терминальными или терминальными и будучи прочитаны слева на право, образуют сентенциальную форму называемую кроной или границей дерева.
Для того что бы увидеть связь между порождениями и деревьями разбора рассмотрим произвольное приведение. α1 → α2 → … → αn
Где альфа 1 отдельный не терминал А.
Для каждой сентенциальной формы альфа 1 можно построить дерево разбора, кроной которого является альфа 1 этот процесс представляет собой индукцию по i.
Пример, последовательность деревьев разбора:
1) Порождение E => -E
E -> E
/ \
- E
Для моделирования этого шага корню Е в начало дерева добавляют два дочерних узла помеченных «-» и «Е».
2) – E => - (E) добавляют 3 дочерних узла, помеченных (, Е, ) к листу Е для получения дерева с кроной – (Е).
E
/ \
- E
/ | \
( E )
Продолжая построение описываемым способом получается полноценное дерево разбора.
E -> E -> E
/ \ / \ / \
- E - E - E
/ | \ / | \ / | \
( E ) ( E ) ( E )
/ | \ / | \ / | \
E + E E + E E + E
| | |
id id id
Т.к. дерево разбора игнорирует порядок, в котором производилось замещение символов в сентенциальной форме, между порождениями и деревьями возникает соотношение «многих к одному».
Каждое дерево связано с единственным левым и единственным правым порождением.
17. Нисходящий синтаксический анализ
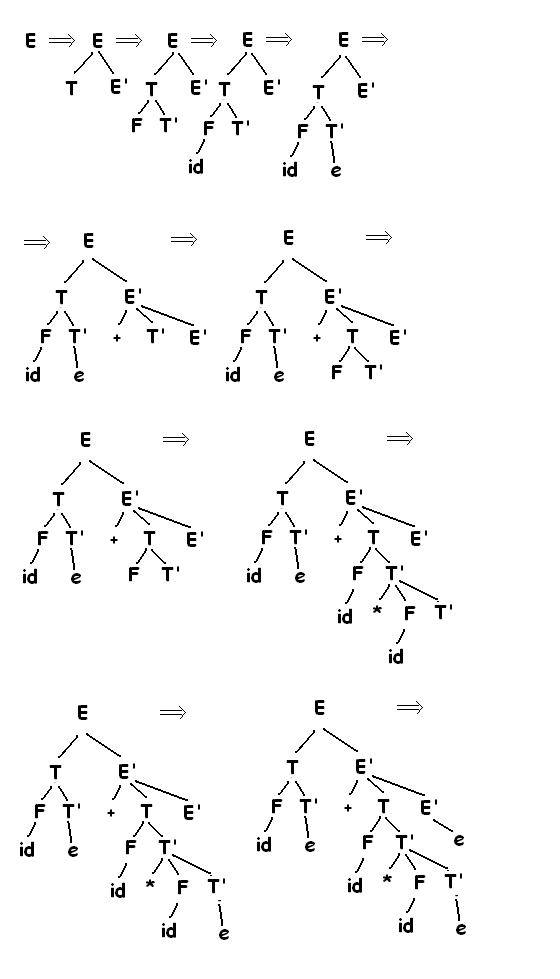
Можно рассмотреть как поиск левого порождения входящей строки. Рассмотрим последовательность построений деревьев разбора для входящей строки (id+id)*id, представляющий собой нисходящий синтаксический анализ, построенный в соответствии с грамматикой:
E -> TE’
E’ -> +TE’|e
T ->FT’
T’ -> *FT’|e
F -> (E)|id
Эта последовательность деревьев соответствует левому порождению входящей строки. На каждом шаге нисходящего синтаксического анализа ключеваой проблемой является определение продукции, применимой для нетерминалов, например А. Когда А продукция выбрана, остальные части процесса синтаксического анализа состоят из проверки соответвствий терминальных символов в теле продукции входящей строки. В рассмотренном примере строится дерево с двумя узлами, помеченными E’, в первом (в прямом) порядке обхода узла Е’ выбирается продукция
E’ -> +TE’, во втором E’ -> e. Синтаксический анализатор может выбрать нужную E’ продукцию, рассматривающую очередной входящий символ. Класс Грамматик для которых можно построить синтаксический анализатор, просматривающий k-символов во входящем потоке называется классом LL(k).
Метод рекурсивного спуска
Программа синтаксического анализатора методом рекурсивного спуска состоит из набора процедур по одной для каждого нетерминала. Работа программы начинается с вызова процедуры для стартового символа и успешно заканчивается в случае сканирования всей входящей строки.
Типичная процедура для нетерминала низходящего анализатора
Void A() {
Выбираем А-продукцию А->X1X2…Xk
For(от 1 до k) {
If (Xi-нетерминал) Вызов процедуры Xi();
else if(Xi равно текущему входному символу a)
Переход к следующему входному символу
else (Обнаружена ошибка)
}}
Этот псевдокод недетерминирован т.к. он начинается с выбором А-продукции не указанным способом.
Рекурсивный способ в общем случае может потребовать выполнения возврата т.е. повторения сканирования входного потока. При анализе синтаксической конструкции языка программирования возврат требуется редко. В ситуациях , наподобие, синтаксического анализа естественного языка возврат не слишком эффективен и предпочтительней являются табличные методы. Чтобы разрешить возврат код в примере должен быть модифицирован:
Невозможно выбрать единую А-продукцию в строке (1), поэтому требуется испытывать каждую из нескольких продукций в некотором порядке.
Ошибка в строке (*) не является окончательной и предполагает возворат к строке (1) и испытание другой А-продукции.
Объявлять о найденной во входной строке ошибке можно только в том случае, если больше не имеется непроверенных А-продукций.
Пример:
Рассмотрим Грамматику:
S -> cAd
A -> ab|a
Чтобы построить дерево разбора для входной строки ω-cod начинают с дерева, состоящего из единичного узла с меткой S и указателя входного потока, указывающего на С или первый символ ω.
S имеет единичную продукцию, поэтому ее используют для разворачивания и получения дерева.
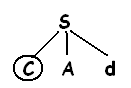
Соответствует первому символу входного потока ω, поэтому указатель входного потока перемещается к а-второму символу ω и рассматривается следующий лист, помеченный А.
Затем разворачивается А с использованием альтернативы А -> ab и получаем таким образом дерево, показанное на рис.
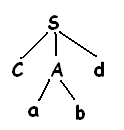
Имеется совпадение второго входного символа а, поэтому выполняется переход к третьему символу d и сравнивают его с очередным листком b. Т.к. b не соответствует d, то сообщается об ошибке и происходит возврат к А.
Чтобы выяснить нет ли альтернативной продукции, которая не была проверена до этого времени, вернувшись к а необходимо отбросить указатель входного потока так, чтобы он указывал на позицию 2, в которой указатель находится, когда впервые столкнулся с а. Это означает что процедура для а должна хранить указатель на входной поток в локальной переменной.
Вторая альтернатива для а дает дерево разбора:
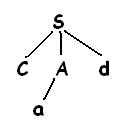
Лист а соответствует второму символу ω, а лист d – третьему символу. Т.к. построено дерево разбора для входящей строки ω, то алгоритм завершает работу и сообщает об успешном выполнении синтаксического анализа и построении дерева разбора. Левосторонняя грамматика может привести синтаксический анализатор, работающий методом рекурсивного спуска к бесконечному циклу, т.е. когда пытаются проверить нетерминал а, то в конечном счете можно найти этот же нетерминал а и перейти к попытке развернуть а, так и не взяв ни одного символа из входного потока.