

1.4 Вопросы для самоконтроля к главе 1
Что понимается под ведением данных?
Можно ли использовать термины «база данных» и «банк данных» как эквивалентные?
Какие функции по отношению к пользователю выполняет СУБД?
Что включают требования надежности и безопасности БД?
Чем характеризуются БД первого поколения?
Глава 2 Модели данных
2.1. Классификация моделей данных
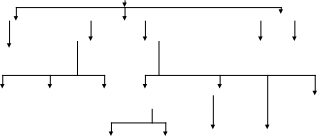
Модель данных - это совокупность структур данных, взаимосвязей и операций их обработки. На рис.2.1 представлена классификация моделей данных в соответствии с рассмотренной ранее трехуровневой архитектурой.
Инфологическая модель отображает реальный мир в некоторые понятные человеку концепции, полностью независимые от параметров среды хранения данных. Инфологическая модель отражает ПО в виде совокупности информационных объектов и их структурных связей. Существует множество подходов к построению таких моделей. Наиболее популярной из них оказалась модель «сущность-связь» (ER - Entity Relationship), которая будет рассмотрена в п.5.2. Инфологическая модель должна быть отображена в компьютеро-ориентированную даталогическую модель, «понятную» СУБД. В процессе развития теории и практического использования баз данных, а также средств вычислительной техники создавались СУБД, поддерживающие различные даталогические модели – документальные и фактографические.
Документальные модели соответствуют представлению о слабо структурированной информации, ориентированной на свободные форматы текста на естественном языке.
Модели, ориентированные на формат документа, связаны прежде всего со стандартным общим языком разметки - SGML, чаще используются HTML и XML
Тезаурусные модели основаны на принципе организации словарей и содержит определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели используются в системах - переводчиках, особенно в многоязыковых переводчиках.
Дескрипторные модели – самые простые из документальных моделей и широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствует дескриптор (описатель), имеющий жесткую структуру. Дескриптор описывал документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой БД. Например, для БД с описаниями патентов дескриптор содержал название области, к которой относился патент, номер, дату выдачи патента и еще ряд ключевых характеристик. Обработка информации в таких БД велась исключительно по дескрипторам, а не по самому текстовому описанию патента.
 Модели
данных
Модели
данных
Инфологические Даталогические Физические
модель документальные фактографические основанные основанные
сущность-связь (ER) на файловых на странично-
структурах сегментной
организации
ориентиро- дескрип- тезаурусные теоретико- теоретико- объектно-
ванные торные графовые множественные ориентиро-
на формат ванные
документа
иерархические сетевые реляционные основанные на
инвертированных файлах
Рисунок. 2.1. Классификация моделей данных
Физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде. Физическая организация данных оказывает основное влияние на эксплуатационные характеристики БД.
Фактографические модели. Сначала стали использовать иерархические даталогические модели. Простота организации, наличие заранее заданных связей между сущностями, сходство с физическими моделями данных позволяли добиваться приемлемой производительности иерархических СУБД на медленных ЭВМ с весьма ограниченными объемами памяти. Но, если данные не имели древовидной структуры, то возникало много сложностей при построении иерархической модели.
Сетевые модели также создавались для мало ресурсных ЭВМ. Это достаточно сложные структуры, состоящие из «наборов» – поименованных двухуровневых деревьев. «Наборы» соединяются с помощью «записей-связок», образуя цепочки и т.д. При разработке сетевых моделей было выдумано множество «маленьких хитростей», позволяющих увеличить производительность СУБД, но существенно усложнивших последние. Прикладной программист должен изучить несколько внутренних языков СУБД, детально представлять логическую структуру базы данных для осуществления навигации среди различных экземпляров, наборов, записей и т.п.
Сложность практического использования иерархических и сетевых СУБД заставляла искать иные способы представления данных. В конце 60-х годов появились СУБД на основе инвертированных файлов, отличающиеся простотой организации и наличием весьма удобных языков манипулирования данными. Однако такие СУБД обладают рядом ограничений на количество файлов для хранения данных, количество связей между ними, длину записи и количество ее полей.
Сегодня наиболее распространены реляционные модели, которые будут подробно рассмотрены в главе 3.
Любая логическая модель данных должна содержать три компоненты:
структура данных;
набор допустимых операций, выполняемых на структуре данных. Модель данных предполагает наличие языка определения данных, описывающего структуру их хранения, и языка манипулирования данными, включающего операции извлечения и модификации данных;
ограничение целостности: механизм поддержания соответствия данных ПО на основе формально описанных правил.
Прежде, чем перейти к детальному и последовательному изучению реляционных систем БД, остановимся коротко на логических моделях ранних (дореляционных) СУБД.
Для обозначения типов структур данных широко используется терминология, предложенная CODASYL (The Conference on Data Systems Languages): элемент данных, агрегат данных, запись, база данных.
Элемент данных (ЭД) - наименьшая поименованная единица данных, к которой СУБД может адресоваться непосредственно, и с помощью которой выполняется построение всех остальных структур. ЭД имеет имя и значение.
Агрегат данных (АД) - поименованная совокупность ЭД внутри записи, которую можно рассматривать как единое целое. АД может быть простым или составным.
Запись - поименованная совокупность ЭД и агрегатов. Запись это АД, не входящий в состав другого АД. Запись может иметь сложную иерархическую структуру, так как допускается многократное применение агрегации.
База данных - поименованная совокупность экземпляров записей различного типа, содержащая ссылки между записями, представленные экземплярами наборов. Описание структуры БД задается ее схемой.