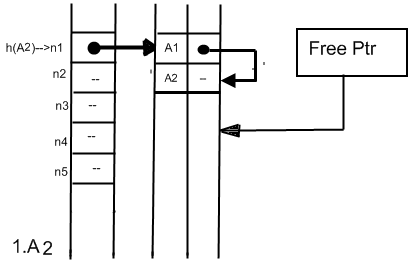
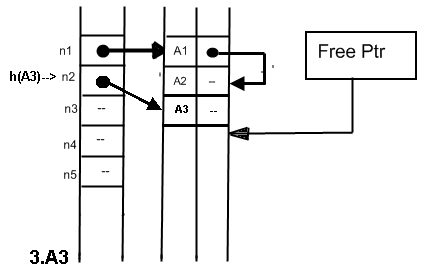
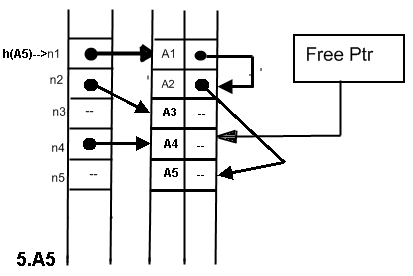
Мал. 3 Заповнення таблиці ідентифікаторів при використанні найпростішого рехешерування
Навіть такий примітивний метод рехеширування є досить ефективним засобом організації таблиць ідентифікаторів при приватному заповненні таблиці. Маючи, наприклад, заповнену на 90% таблицю для 1024 ідентифікаторів, в середньому необхідно виконати 5.5 порівнянь для пошуку одного ідентифікатора, у той час як навіть логарифмічний пошук дає в середньому від 9 до 10 порівнянь. Порівняльна ефективність методу буде ще вище при зростанні числа ідентифікаторів і зниженні заповнювання таблиці. Середній час на приміщення одного елемента в таблицю і на пошук елемента в таблиці можна знизити, якщо застосувати більш досконалий метод рехеширування. Одним з таких методів є використання як р1, для функції h1(A) = (h (A) + р1,) mod Nm послідовності псевдовипадкових цілих чисел р1, р2, рk. При хорошому виборі генератора псевдовипадкових чисел довжина послідовності до буде k = Nm. Тоді середній час пошуку одного елемента в таблиці можна оцінити таким чином [17]:
Em = О((l / Lf) * log2 (l - Lf)).
Існують і інші методи організації функцій рехеширування h1(A), основані на квадратичних обчисленнях або, наприклад, на обчисленні за формулою: h1 (A) = (h(A) * i) mod Nm, якщо Nm - просте число. В цілому рехеширування дозволяє досягти непоганих результатів для ефективного пошуку елемента з таблиці (кращих, ніж бінарний пошук і бінарне дерево), але ефективність методу сильно залежить від заповнювання таблиці ідентифікаторів і якості використовуваної хеш-функції - чим рідше виникають колізії, тим вище ефективність методу. Вимога часткового заповнення таблиці веде до неефективного використання обсягу пам'яті.
Побудова таблиць ідентифікаторів за методом ланцюжків
Часткове заповнення таблиці ідентифікаторів при застосуванні хеш-функцій веде до неефективного використання всього обсягу пам'яті, доступного компілятору. Причому обсяг не використовуваної пам'яті буде тим вище, чим більше інформації зберігається для кожного ідентифікатора. Цього недоліку можна уникнути, якщо доповнити таблицю ідентифікаторів деякої проміжної хеш-таблицею.
В осередках хеш-таблиці може зберігатися або пусте значення, або значення покажчика на деяку область пам'яті з основної таблиці ідентифікаторів. Тоді хеш-функція обчислює адресу, за якою відбувається звернення спочатку до хеш-таблиці, а потім вже через неї по знайденому адресою - до самої таблиці ідентифікаторів. Якщо відповідна клітинка таблиці ідентифікаторів порожня, то комірка хеш-таблиці міститиме порожнє значення. Тоді зовсім не обов'язково мати в самій таблиці ідентифікаторів клітинку для кожного можливого значення хеш-функції - таблицю можна зробити динамічної так, щоб її обсяг зростав у міру заповнення (спочатку таблиця ідентифікаторів не містить жодної клітинки, а всі комірки хеш-таблиці мають пусте значення). Такий підхід дозволяє домогтися двох позитивних результатів: по-перше, немає необхідності заповнювати порожніми значеннями таблицю ідентифікаторів - це можна зробити тільки для хеш-таблиці;по-друге, кожному ідентифікатору буде відповідати строго одна комірка в таблиці ідентифікаторів (у ній не буде порожніх не використовуваних комірок). Порожні комірки в такому випадку будуть тільки в хеш-таблиці, і обсяг не використовуваної пам'яті не буде залежати від об’єму інформації, що зберігається для кожного ідентифікатора, - для кожного значення хеш-функції буде витрачатися тільки пам'ять, необхідна для зберігання одного покажчика на основну таблицю ідентифікаторів. На основі цієї схеми можна реалізувати ще один спосіб організації таблиць ідентифікаторів за допомогою хеш-функцій, званий «метод ланцюжків». Для методу ланцюжків у таблицю ідентифікаторів для кожного елемента додається ще одне поле, в якому може міститися посилання на будь-який елемент таблиці. Спочатку це поле завжди порожнє (нікуди не вказує). Також для цього методу необхідно мати одну спеціальну змінну, яка завжди вказує на першу вільну комірку основної таблиці ідентифікаторів (спочатку - вказує на початок таблиці).
Метод ланцюжків працює за наступним алгоритмом:
Крок 1. У всі комірки хеш-таблиці помістити порожнє значення, таблиця ідентифікаторів порожня, мінлива FreePtr (покажчик першої вільної комірки) вказує на початок таблиці ідентифікаторів; i: = 1.
Крок 2. Обчислити значення хеш-функції n1, для нового елемента А1. Якщо комірка хеш-таблиці за адресою n1, порожня, то помістити в неї значення змінної FreePtr і перейти до кроку 5; інакше перейти до кроку 3.
Крок 3. Покласти j:=1, вибрати з хеш-таблиці адресу комірки таблиці ідентифікаторів mj і перейти до кроку 4.
Крок 4. Для комірки таблиці ідентифікаторів за адресою mj перевірити значення поля посилання. Якщо воно порожнє, то записати в нього адресу з перемінної FreePtr і перейти до кроку 5; інакше j:=j+1, вибрати з поля посилання адресу mj, і повторити крок 4.
Крок 5. Додати в таблицю ідентифікаторів нову комірку, записати в неї інформацію для елемента А1 (поле посилання повинне бути порожнім), в змінну FreePtr помістити адресу за кінцем доданої комірки. Якщо більше немає ідентифікаторів, які треба розмістити в таблиці, то виконання алгоритму закінчено, інакше i:=i+1 і перейти до кроку 2.
Пошук елемента в таблиці ідентифікаторів, організованої таким чином, буде виконуватися за наступним алгоритмом:
Крок 1. Обчислити значення хеш-функції n для шуканого елемента А. Якщо комірка хеш-таблиці за адресою n порожня, то елемент не знайдений і алгоритм завершений, інакше покласти j:=1, вибрати з хеш-таблиці адресу комірки таблиці ідентифікаторів mj.
Крок 2. Порівняти ім'я елемента в комірці таблиці ідентифікаторів за адресою mj, з ім'ям шуканого елемента А. Якщо вони збігаються, то шуканий елемент знайдений і алгоритм завершений, інакше перейти до кроку 3.
Крок 3. Перевірити значення поля посилання в комірці таблиці ідентифікаторів за адресою mj. Якщо воно порожнє, то шуканий елемент не знайдений і алгоритм завершений, інакше j:=j+1, вибрати з поля посилання адреса mj, і перейти до кроку 2.
При такій організації таблиць ідентифікаторів у разі виникнення колізії алгоритм розміщує елементи в комірках таблиці, пов'язуючи їх одне з другом послідовно через поле посилання. При цьому елементи не можуть потрапляти в комірку з адресами, які потім будуть збігатися зі значеннями хеш-функції. Таким чином, додаткові колізії не виникають. У результаті в таблиці виникають своєрідні ланцюжки пов'язаних елементів, звідки походить і назва даного методу - «метод ланцюжків».
На мал.4 проілюстровано заповнення хеш-таблиці і таблиці ідентифікаторів для прикладу, який раніше був розглянутий на мал.3 для методу простого рехеширування. Після розміщення в таблиці для пошуку ідентифікатора А1, потрібно 1 порівняння, для А2 - 2 порівняння, для A3 - 1 порівняння, для А4 - 1 порівняння і для А5 - 3 порівняння (порівняйте з результатами простого рехеширування).
Метод ланцюжків є дуже ефективним засобом організації таблиць ідентифікаторів. Середній час на розміщення одного елемента і на пошук елементу в таблиці для нього залежить тільки від середнього числа колізій, виникаючих при обчисленні хеш-функції. Накладні витрати пам'яті, пов'язані з необхідністю мати одне додаткове поле покажчика в таблиці ідентифікаторів на кожен її елемент, можна визнати цілком виправданими. Цей метод дозволяє більш економно використовувати пам'ять, але вимагає організації роботи з динамічними масивами даних.