Мал. 1 Заповнення бінарного дерева для послідовності ідентифікаторів в ga, d1, m22, e, a12, bc, f
Наприклад, зробимо пошук в дереві, зображеному на мал.1, ідентифікатора А12. Беремо корінну вершину (вона стає поточним вузлом), порівнюємо ідентифікатори GA і А12. Шуканий ідентифікатор менше - поточним вузлом стає ліва вершина D1. Знову порівнюємо ідентифікатори. Шуканий ідентифікатор менше - поточним вузлом стає ліва вершина А12. При наступному порівнянні шуканий ідентифікатор знайдений.
Якщо шукати відсутній ідентифікатор - наприклад, A11, - то пошук знову піде від корінної вершини. Порівнюємо ідентифікатори A і А11. Шуканий ідентифікатор менше - поточним вузлом стає ліва вершина D1. Знову порівнюємо ідентифікатори. Шуканий ідентифікатор менше - поточним вузлом стає ліва вершина А12. Шуканий ідентифікатор менше, але ліва вершина у вузла А12 відсутня, тому в даному випадку шуканий ідентифікатор не знайдений.
Для даного методу число необхідних порівнянь і форма отриманого дерева залежать від того порядку, в якому надходять ідентифікатори. Наприклад, якщо в розглянутому вище прикладі замість послідовності ідентифікаторів GА, D1, М22, Е, А12, ВС, F взяти послідовність А12, GA, D1, М22, Е, ВС, F, то отримане дерево матиме інший вигляд. А якщо як приклад взяти послідовність ідентифікаторів А, В, С, D, Е, F, то дерево виродиться в упорядкований односпрямований зв'язний список. Ця особливість є недоліком даного методу організації таблиць ідентифікаторів. Іншим недоліком є необхідність роботи з динамічним виділенням пам'яті при побудові дерева. Якщо припустити, що послідовність ідентифікаторів у вихідній програмі є статистично невпорядкованою (що в цілому відповідає дійсності), то можна вважати, що побудоване бінарне дерево буде невиродженим. Тоді середній час на заповнення дерева (Т3) і на пошук елемента в ньому (Т) можна оцінити таким чином [4, т.2]:
Т3 = N*О(log2 N)
Тn =О(log2 N)
У цілому метод бінарного дерева є досить вдалим механізмом для організації таблиць ідентифікаторів. Він знайшов своє застосування в ряді компіляторів. Іноді компілятори будують кілька різних дерев для ідентифікаторів різних типів і різної довжини [17, 50].
Хеш-функції і хеш-адресація.
Принципи роботи хеш-функцій
Логарифмічна залежність часу пошуку і часу заповнення таблиці ідентифікаторів - це найкращий результат, якого можна досягти за рахунок застосування різних методів організації таблиць. Однак у реальних вихідних програмах кількість ідентифікаторів настільки велика, що навіть логарифмічну залежність часу пошуку від їх числа не можна визнати задовільно. Необхідні більш ефективні методи пошуку інформації в таблиці ідентифікаторів.
Кращих результатів можна досягти, якщо застосувати методи, пов'язані з використовування хеш-функцій та хеш-адресації.
Хеш-функцією
F називається деяке відображення множини
вхідних елементів R
на безліч цілих невід'ємних чисел Z:
F(r)=n, r
![]() R,
n
R,
n
![]() Z.
Сам термін «хеш-функція» походить від
англійського терміна «hash function» (hash
-«мішати»,« змішувати »,«плутати»).
Замість терміна «хешування» іноді
використовують терміни «рандомізація»,
«переупорядковування». Множина
допустимих вхідних елементів R
називається областю визначення
хеш-функції. Безліччю значень хеш-функції
F називається підмножина М
з множини цілих невід'ємних чисел Z:
M
≤
Z,
що містить всі можливі значення, які
повертаються функцією F:
Z.
Сам термін «хеш-функція» походить від
англійського терміна «hash function» (hash
-«мішати»,« змішувати »,«плутати»).
Замість терміна «хешування» іноді
використовують терміни «рандомізація»,
«переупорядковування». Множина
допустимих вхідних елементів R
називається областю визначення
хеш-функції. Безліччю значень хеш-функції
F називається підмножина М
з множини цілих невід'ємних чисел Z:
M
≤
Z,
що містить всі можливі значення, які
повертаються функцією F:
![]() r
r
![]() R:
F(r)
R:
F(r)
![]() M
і
M
і
![]() m
m
![]() M:
M:
![]() r
r
![]() R:
F(r)=m. Процес відображення області
визначення хеш-функції на множену
значень називається «хешируванням».
R:
F(r)=m. Процес відображення області
визначення хеш-функції на множену
значень називається «хешируванням».
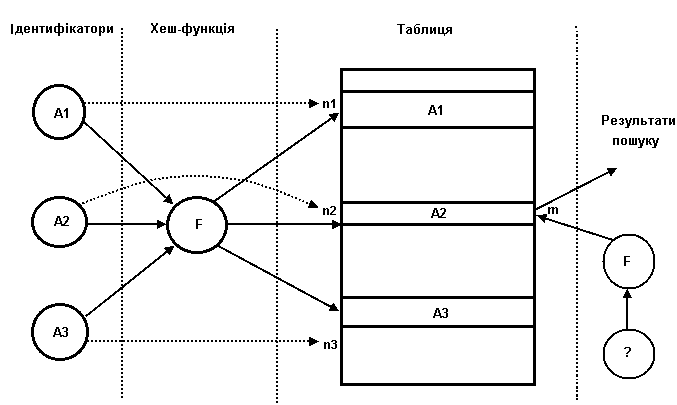
При роботі з таблицею ідентифікаторів хеш-функція повинна виконувати відображення імен ідентифікаторів на множину цілих невід'ємних чисел. Областю визначення хеш-функції буде множина всіх можливих імен ідентифікаторів.
Хеш-адресація полягає у використанні значення, що повертається хеш-функцією, в якості адресу комірки з деякого масиву даних. Тоді розмір масиву даних повинен відповідати області значень використовуваної хеш-функції. Отже, в реальному компіляторі область значень хеш-функції ніяк не повинна перевищувати розмір доступного адресного простору комп'ютера.
Метод організації таблиць ідентифікаторів, заснований на використанні хеш-адресації, полягає в розміщенні кожного елемента таблиці у комірці, адресу якої повертає хеш-функція, обчислена для цього елемента. Тоді в ідеальному випадку для розміщення будь-якого елементу в таблиці ідентифікаторів достатньо тільки обчислити його хеш-функцію і звернутися до потрібної комірки масиву даних. Для пошуку елемента в таблиці необхідно обчислити хеш-функцію для шуканого елемента і перевірити, чи не є задана нею комірка масиву порожньою (якщо вона не порожня - елемент знайдений, якщо порожня - не знайдено).Спочатку таблиця ідентифікаторів повинна бути заповнена інформацією, яка дозволила б говорити про те, що всі її комірки є порожніми.