

8.5. Линейные списки. Способы создания и обработки
Последовательное распределение – список членов последовательности, расположенных по порядку в последовательных ячейках памяти. Основными преимуществами последовательного распределения являются:
- легкость реализации и небольшой расход памяти;
-
простая связь между номером элемента
![]() и адресом ячейки
и адресом ячейки
![]() ,
в которой этот элемент хранится
,
в которой этот элемент хранится
![]() ,
где
,
где
![]() – адрес
ячейки, где хранится первый элемент,
– адрес
ячейки, где хранится первый элемент,
![]() – количество байт, требуемых для хранения
одного элемента данного типа;
– количество байт, требуемых для хранения
одного элемента данного типа;
152
- возможность представления многомерных массивов.
Однако при последовательном распределении сложно реализовать операции включения новых и исключения имеющихся элементов.
Связанное
распределение
– это такой тип организации
последовательности, при котором каждому
элементу последовательности
![]() ставится
в соответствие указатель
ставится
в соответствие указатель
![]() ,
отмечающий ячейку, в которую записан
элемент последовательности
,
отмечающий ячейку, в которую записан
элемент последовательности
![]() .
Существует также указатель
.
Существует также указатель
![]() ,
который указывает на начальную ячейку
последовательности:
,
который указывает на начальную ячейку
последовательности:

![]()
При выборе последовательного или связанного представления сначала нужно проанализировать типы операций, которые будут выполняться над последовательностью. Если операции производятся над
случайными элементами, осуществляют поиск специфических элементов или производят упорядочивание элементов, то обычно лучше использовать последовательное распределение. Связанное распределение предпочтительнее, если в значительной степени используются операции включения или (и) исключения элементов, а также операции сцепления или (и) разбиения последовательностей.
Разновидности
связанных списков.
Если элемент
![]() указывает
на
указывает
на
![]() ,
то такой список называется циклическим.
,
то такой список называется циклическим.


153
Tакой способ задания списка позволяет достигнуть любой элемент из любого другого элемента последовательности. Включение и исключение здесь осуществляется так же, как и в нециклических списках, а сцепление и разбиение реализуются сложнее.
Стек – последовательность, у которой все включения и выключения элементов происходят только в ее левом конце, называемом вершиной стека. Стек работает по правилу: “Первый пришел – последний ушел”.
Работа со стеком.
type ukaz = ^stack;
stack = record
inf: integer;
next: ukaz
end;
var top, kon, newel: ukaz; value: integer;
procedure sozd; {Помещение элементов в стек}
begin
top: = nil;
while true do
begin
read (value);
If value = 9999 then exit;
new(kon); {Выделение памяти для}
{хранения текущего элемента}
{Заполнение информационного поля}
kon^ . inf: = value; }
{В поле ссылки каждого элемента }
{помещаем адрес элемента, за которым}
{он следует; для элемента, вводимого}
{первым, этот адрес будет равным nil}
kon^ . next: = top;
154
{Запоминаем текущую вершину стека}
top: = kon;
end; {while}
end; {конец процедуры sozd}
procedure dob; {Добавляет новые элементы}
{в уже существующий стек,}
{адрес вершины которого }
{должен быть известен}
begin
while true do
begin
read (value);
if (value = 9999) then exit;
new (newel);
newel^ . next: = top;
newel^ . inf: = value;
top: = newel;
end;
end;
procedure udal; {Удаляется один элемент из}
{стека; указатель вершины}
{стека перемещается к}
{следующему элементу}
begin
top:= top^.next;
end;
procedure writ; {Вывод элементов стека}
{на экран}
begin
kon:=top;
while kon<> nil do
begin
writeln(kon^ . inf);
155
kon: = kon^ . next;
end;
end;
bеgin {Головная программа}
sozd;
writ;
dob;
writ;
udal;
writ;
end.
Вот как будет выглядеть стек, в который записаны последовательно числа 3, 15, 7:
![]()
![]()
![]()


![]() – адреса,
по которым элементы стека размещены в
динамической области памяти. Адрес
вершины стека хранится в переменной
– адреса,
по которым элементы стека размещены в
динамической области памяти. Адрес
вершины стека хранится в переменной
![]() .
.
Рассмотрим
механизм удаления из стека элемента,
находящегося в любом месте стека.
Допустим, что надо удалить элемент со
значением
![]() .
.
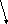
![]()
![]()
![]()

Алгоритм удаления элемента применительно к рассмотренной схеме стека, состоит из следующих шагов:
156
-
определение адреса удаляемого элемента
(![]() );
);
-
сохранение адреса элемента, предшествующего
удаляемому (![]() );
);
-
замена поля ссылки элемента, предшествующему
удаляемому элементу, на поле ссылки
удаляемого элемента (![]() ).
).
Однако этот алгоритм не будет работать в том случае, если необходимо удалять группы одинаковых элементов, находящихся в любой части стека.
В этом случае после определения адреса удаляемого элемента необходимо провести дополнительный анализ:
- если удаляемый элемент является вершиной стека, то вершина стека должна переноситься на следующий элемент до тех пор, пока вершиной стека не станет элемент, отличающийся от удаляемого, то есть, до тех пор, пока не будет удалена вся группа одинаковых элементов;
- если группа удаляемых элементов будет находиться не
в начале стека, то необходимо обеспечить сохранность адреса элемента, предшествующего группе удаляемых элементов до тех пор, пока эта группа не будет полностью удалена.
Далее приведен текст программы, реализующей алгоритм удаления заданного элемента из стека.
type
ukaz=^stek;
stek=record
inf: integer;
next:ukaz;
end;
var
v,w,flag,flag1:integer;
kon,top,t1,t:ukaz;
begin {Создание стека}
157
top:=nil;
while true do
begin
writeln('Введите очередной член ряда');
readln(v);
if(v=9999) then break;
new(kon);
kon^.inf: = v;
kon^.next: = top;
top:=kon;
end;
{Вывод элементов стека на экран}
kon:=top;
while kon<> nil do
begin
write(kon^.inf,' ');
kon:=kon^.next;
end;
kon: = top; flag: = 0; t1: = top; t: = kon; flag1: = 0;
writeln('Введите значение удаляемого элемента');
readln(w);
while kon<>nil do
begin
if(kon^.inf=w) then
{Удаление группы одинаковых элементов из начала}
{стека}
begin
if (flag=0) then
begin
t1:=kon^.next;
kon:=t1;
end
else
158
{Удаление группы одинаковых элементов из}
{середины и конца стека}
begin
if (flag1=0) then
begin
t^.next: = kon^.next;
kon:=kon^.next;
flag:=1;
end
else begin
t^.next:=kon^.next;
t:=kon;
kon:=kon^.next;
flag:=1;
flag1:=1;
end;
end;
end
else
begin
t:=kon;
kon:=kon^.next;
flag:=1;
end;
end;
{Вывод на экран результирующего стека}
kon:= t1;
while kon<> nil do
begin
write(kon^.inf,' ');
kon:=kon^.next;
end;
end.
159
Очередь - это последовательность, в которой все включения элементов производятся на правом конце списка (в конце очереди), а исключения производятся на левом конце (в начале очереди). Очередь работает в режиме “Первый пришел – первый ушел”. Поэтому при работе с очередью необходимо хранить как адрес первого элемента очереди, так и адрес последнего (right, left).
Механизм формирования очереди (3, 15, 7) можно по шагам представить так:
1.

2.
3
![]()
![]()
![]()

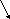
type
ukaz = ^stack;
stack = record
inf: integer;
next: ukaz
end;
var pp, kon, newel, right, left: ukaz; value: integer;
160
procedure sozd; {Организация очереди}
begin
read (value);
if (value =9999) then exit;
new(kon); kon^.next: = nil;
kon^.inf: = value;
right: = kon;
left: = kon;
while true do
begin
read (value);
if value = 9999 then exit;
new(kon); kon^ . next: = left;
kon^ . inf: = value; left: = kon;
end;
end;
{Добавление новых элементов в уже существующую очередь.} {Добавление происходит справа}
procedure dob;
begin
while true do
begin
read (value);
If value = 9999 then exit;
new (newel);
right^.next: = newel;
newel^ . next: = nil;
newel^ . inf: = value;
right = newel;
end;
end;
{Удаление элемента из очереди, удаление происходит слева}
161
procedure udal;
begin
left: = left^.next:
end;
{Вывод на экран элементов очереди}
procedure writ;
begin
pp: = top;
while pp <> nil do
begin
writeln(pp^ . inf);
pp: = pp^ . next;
end;
end;
bеgin
sozd; dob; udal; writ;
end.
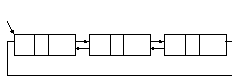
Двусвязный
список. Если
каждый элемент списка
![]() имеет два
связанных с ним указателя: на предыдущий
и последующий элемент
имеет два
связанных с ним указателя: на предыдущий
и последующий элемент
![]() и
и
![]() ,
то такой список называется дважды
связанным или двусвязным. В таком
списке для
,
то такой список называется дважды
связанным или двусвязным. В таком
списке для
любого элемента есть свободный доступ к предыдущему и последующему элементам. Двусвязный список можно сделать циклическим.
Структура двусвязного списка циклического может быть представлена так:

162
type ukaz = ^Stack;
stack = record
inf: integer;
{Левое и правое поля ссылок}
nextRight, nextLeft: ukaz;
end;
var point, kon, nt, newel, right, left: ukaz;
value: integer;
procedure sozd; {Организация двусвязной очереди}
begin {Запись первого элемента в очередь}
read (value);
if (value =9999) then exit;
new(kon);
kon^ . inf:=value;
kon^.nextRight: = nil;
kon^.nextLeft: = nil;
right: = kon;
nt: = kon;
{Запись элементов в очередь, начиная со }
{второго}
while true do
begin
read (value);
if value = 9999 then exit;
new(kon);
kon^ . inf:= value;
kon^ . nextRight: = nt;
nt^. nextLeft: = kon;
end;
nt^ .nextLeft: = nil;
left: = nt;
end;
{Добавление нового элемента в двусвязный}
163
{список. Новый элемент добавляется в}
{список после элемента, на который}
{указывает значение point}
procedure dob;
begin
read (value);
if value = 9999 then exit;
new (newel);
newel^ . inf: = value;
newel^ . nextRight: = point^. nextRight;
newel^ . nextLeft = point;
point^. nextRight ^. nextLeft: = newel;
point^. nextRight: = newel;
end;
{Удаление элемента из двусвязной очереди.}
{Из списка удаляется элемент, следующий}
{ за элементом, на который указывает}
{значение point}
procedure udal;
begin
point^. nextRight:=point^. nextRight^ . nextRight;
point^. nextRight^ .nextLeft: = point;
end; bеgin
sozd;
dob;
udal;
end.