

2.3. Классификация систем по способам обработки данных
Данные могут храниться двумя способами – непосредственно в виде файлов или в базах данных. Файлы обычно создаются для работы с одной прикладной задачей или группой связанных задач. Представление программиста о файле практически соответствует физической структуре файла. Распределённые данные часто организуются в форме файлов, а не в форме баз данных. Данные могут храниться централизовано или децентрализовано, что диктуется существом самих хранимых данных. Например, если файл непрерывно обновляется, а территориально разобщённые пользователи должны получать всякий раз последнее состояние данных (как в файле резервирования авиабилетов), то естественно такой файл централизовать. Данные обычно централизуются и тогда, когда поиск производится во всей их совокупности. С другой стороны, если данные используются локально в точке их происхождения, они могут быть децентрализованными. При низкой скорости обновления или при автономном обновлении (off-line) допустимо хранение нескольких копий одних и тех же данных в разных местах. Рассмотрим различные типы систем, различающихся по характеру распределения данных.
1. Системы с централизованными данными:

Рис.2.3. Системы с централизованными данными
При наличии нескольких Хост-машин они могут либо находиться в том же месте, где размещены и данные, либо быть удалены от них.
2. Иерархические системы (рис.2.4) Различают: иерархии - зависимые системы и иерархии – независимые системы
В схеме иерархии зависимых системах данные в машинах нижнего уровня тесно связаны с данными в машине верхнего уровня. Зачастую они могут быть подмножествами данных верхнего уровня, используемыми в локальных приложениях. Эталонная копия данных (master copy) при этом может храниться на верхнем уровне. При внесении изменений в данные на нижнем уровне эти изменения должны передаваться в машину верхнего уровня – иногда немедленно, иногда позднее. В других системах такого типа нижний уровень может содержать те же данные, что и верхний, и ещё свои собственные, которые никогда не передаются наверх. Например, на нижнем уровне могут храниться адреса клиентов и более детальная информация о них. Эти данные, занимающие большой объём, обычно не требуются на верхнем уровне. Верхний же уровень может хранить номера клиентов, их имена, сведения о кредитах и заказах. Это - избыточная информация. Она повторяется на обоих уровнях, и любая её модификация на нижнем уровне должна передаваться на верхний уровень.
В схеме иерархии независимых данных все процессоры представляют собой независимые замкнутые системы обработки данных. Структура данных на машинах нижнего уровня отличается от структуры на верхнем уровне. Пример: нижний уровень предназначен для рутинных повторяющихся (массовых) операций: приёма заказов, контроля выпуска продукции, управления складом и т.п. В машинах верхнего уровня, расположенной возможно, при главном управлении предприятием, находится информационная система, которая должна снабжать необходимой информацией руководство, планирующие подразделения, отделы, разработчиков новых изделий и стратегий. Все данные могут быть извлечены из нижних уровней, но они суммируются, редактируются, реорганизуются с помощью вторичных индексов или иных методов поиска, чтобы обеспечить ответы на разнообразные, часто заранее непредвиденные вопросы.
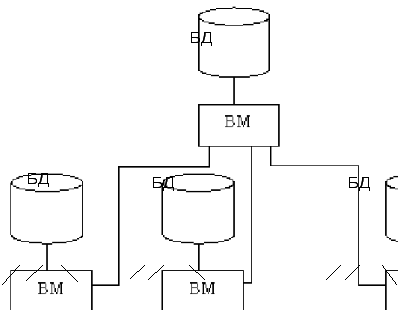
Рис.2.4. Иерархические системы
-
Расщепленные данные:

Рис.2.5. Системы с расщепленными данными
В схеме, соответствующей системе с расщеплёнными данными имеются несколько систем с идентичными структурами данных. Система в районе А хранит данные района А, система в районе В хранит данные района В и т.д. Большинству обрабатываемых транзакций требуются только те данные, которые находятся в обрабатывающей системе, но в некоторых случаях для обработки транзакции, возникающей в одном районе, могут потребоваться данные из другого района. В системах с расщеплёнными данными прикладные программы и структуры данных одинаковые во всех районах, программирование для всех машин выполняет одна общая группа разработчиков. 4. Разделенные данные:

Рис.2.6. Системы с разделенными данными
В системах с разделёнными данными (рис.2.6) объединённые в сеть подсистемы содержат разные данные и разные программы и, как правило, создаются разными группами разработчиков. Тем не менее, они обслуживают одну и ту же частную корпорацию или государственное учреждение. Компьютеры получают возможность запрашивать данные друг у друга.
На схеме одна из подсистем связана с производством, другая – со снабжением (закупками), а третья – с бухгалтерией. Подсистема территориально разделена. Подсистема управления производством, расположенная возможно, на заводе, формирует заявки на поставки, передаваемые подсистеме снабжения. И производственная подсистема, и подсистема снабжения формируют данные, которые должны передаваться в главную бухгалтерию.
-
Реплицированные (дублированные) данные:
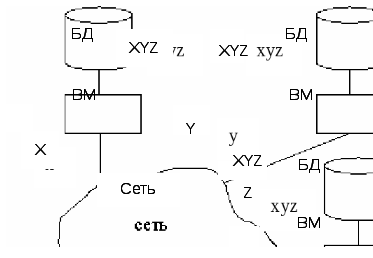
Рис.2.7. Системы с дублированными данными
В системе с реплицированными данными идентичные копии данных хранятся в разных местах, потому что дублирование памяти позволяет избежать передачи больших объёмов данных, и это оказывается дешевле. Такая организация имеет смысл только в тех случаях, когда объём обновлений невелик. Достоинство: при дублировании очень высокая надежность. Недостаток: приходится часто обновлять информацию, копировать. 6. Гетерогенные системы:

Рис.2.8. Гетерогенные системы
На рис.2.8 приведена гетерогенная система. Она состоит из независимых вычислительных систем, установленных различными организациями для решения своих специфических задач.
7. Комбинированные формы распределённых данных

Рис.2.8. Комбинированные системы
РОД ставит много новых проблем: Какие функции должны быть централизованы, а какие децентрализованы? Где должны храниться данные? Какая конфигурация больших машин, малых машин и интеллектуальных терминалов окажется наилучшей для обслуживания заказчика?
2.4. Однородные и неоднородные системы БД
Распределённые системы часто строятся путём «интеграции» разнородных аппаратных и программных средств. Следовательно, должен быть сделан выбор между однородной и неоднородной вычислительной системой. В случае однородных СУБД нет проблем ни с моделями данных, ни с языками запросов, ни с другими средствами. Всё это совпадает с тем, что поддерживается несколько СУБД. Для неоднородных СУБД вопросы усложняются. Использования неоднородных СУБД обычно является следствием формирования РБД из ряда существовавших ранее автономных баз данных. Стоящая перед разработчиками цель – достичь прозрачного доступа, что представляет собой нечто большее, чем простое обеспечение доступа к удалённым СУБД и их базам данных.
Прозрачность может быть реализована двумя методами:
1. Дать пользователю интерфейс, предоставляемой данной локальной СУБД. То есть, имеющаяся схема должна быть расширена для включения данных, имеющихся в других узлах. Сетевая СУБД должна обеспечить в каждом узле возможность обращения к данным любого другого узла независимо от модели данных. Схемы других узлов должны преобразовываться в схему данного узла. Таких преобразований будет n(n-1), где n – число узлов. При большом числе n такая схема будет слишком сложной.
2. Использование единого для всей сети стандартного пользовательского интерфейса (единого протокола). В этом случае все пользователи используют общий интерфейс. Должна существовать единая схема сетевой БД. Каждому типу локальной СУБД должен соответствовать свой тип преобразования схемы. При этом используется лишь n типов преобразований. Недостаток – пользователь должен изучить новую систему – сетевую СУБД.
В настоящее время для взаимодействия с различными СУБД используются специальные средства:
-
ODBC (Open Date Base Connectivity) – разработка фирмы Microsoft.
-
BDE (Borland Database Engine) – фирма Borland.
-
CGI (Common Gateway Interface) – сценарий в рамках Интернета.
Дифференциальные файлы (ДФ)
ДФ в БД аналогичны списку опечаток в книге. Вместо того, чтобы печатать новое издание книги, всякий раз, когда требуется внести изменения в текст, составляется список исправлений с указанием страниц. При достаточно большом списке опечаток производится реорганизация, т.е. создаётся новая книга. Обновление больших баз данных ставит аналогичную задачу. Вместо того, чтобы каждый раз модифицировать БД при каждой транзакции удобнее использовать файл изменений (ДФ). Предварительное обращение к ДФ при операциях выборки является эффективным средством к самому последнему состоянию БД. Когда ДФ достигнет достаточно больших размеров, проводится реорганизация.
2.5. Стратегия размещения данных в РБД по узлам сети
Достоинства и недостатки.
Стратегия распределения данных по узлам сети ЭВМ могут классифицироваться в зависимости от количества узлов, содержащих данные, и наличия дублирования информации, а также архитектурой системы и программным обеспечением СУБД. Рассмотрим четыре альтернативные стратегии распределения данных:
-
Централизация (единственная копия базы данных, расположенная в одном узле).
Достоинства. Все операции под контролем центрального узла.
Недостатки. - Затраты на связь и временные задержки.
-
Ограничения при параллельной обработке.
-
Ограничения объема.
-
Ограничения доступа к данным и надежности.
-
Расчленение (единственная копия БД, непересекающиеся подмножества распределены по различным узлам).
Достоинства. – Увеличение объема памяти.
-
Снижение стоимости связи.
-
Время отклика меньше по сравнению с централизованной БД.
-
Выше доступность и надежность.
-
Локализация ссылок (так как, данные располагаются в узлах таким образом, что запрашиваются пользователями только этих узлов).
-
Дублирование (несколько копий БД, в каждом узле располагается полная копия всех данных).
Достоинство. - Надежность, доступность и эффективность выборки.
-
Простота восстановления.
Недостаток. - Большие затраты в объеме памяти.
- Необходимость синхронизации для согласования копий.
-
Смешанная (несколько копий подмножеств БД, в каждом узле может содержаться произвольный фрагмент БД).
Достоинство. Гибкость. Например, архивные данные могут хранится в одном месте, а критические данные могут дублироваться для повышения надежности).
Недостаток. – Необходимо хранить информацию о том, где находятся данные в сети.
- Необходимость согласования произвольного количества хранимых фрагментов данных.
Принципы построения РБД.
Распределенные архитектуры БД принято подразделять по типам на
-
Системы недублирующего разбиения (при большом объеме часто меняющихся данных)
-
Системы частичного дублирования (при небольшом объеме часто меняющихся данных)
-
Системы полного дублирования (при небольшом объеме редко меняющихся данных)