

1.2. Анализ исходной программы
В этом разделе будет рассмотрен процесс анализа и проиллюстрировано его использование в некоторых языках форматирования текста. Детальнее об этом будет говориться в главах 2-4 и 6. При компиляции анализ состоит из трех фаз.
Линейный анализ, при котором поток символов исходной программы считывается слева направо и группируется в токены (token), представляющие собой последовательности символов с определенным совокупным значением.
-
Иерархический анализ, при котором символы или токены иерархически группируются во вложенные конструкции с совокупным значением.
-
Семантический анализ, позволяющий проверить, насколько корректно совместное размещение компонентов программы.
Лексический анализ
В компиляторах линейный анализ называется лексическим, или сканированием. Например, при лексическом анализе символы в инструкции присвоения
position := initial + rate * 60 будут сгруппированы в следующие токены.
-
Идентификатор position.
-
Символ присвоения : =.
-
Идентификатор initial.
-
Знак сложения.
-
Идентификатор rate.
-
Знак умножения.
-
Число 60.
Пробелы, разделяющие символы этих токенов, при лексическом анализе обычно отбрасываются.
Синтаксический анализ
Иерархический анализ называется разбором (parsing), или синтаксическим анализом, который включает группирование токенов исходной программы в грамматические фразы, используемые компилятором для синтеза вывода. Обычно грамматические фразы исходной программы представляются в виде дерева, пример которого показан на рис. 1.4.
В выражении initial+rate*60 фраза rate*60 является логической единицей, поскольку обычные соглашения о приоритете арифметических операций гласят, что умножение выполняется до сложения. Поскольку после выражения initial+rate следует знак умножения *, само по себе оно не группируется в единую фразу на рис. 1.4.
Иерархическая структура программы обычно выражается рекурсивными правилами. Например, при определении выражений можно придерживаться следующих правил.
-
Любой идентификатор (identifier) есть выражение (expression).
-
Любое число (number) есть выражение (expression).
-
Если expression1 и expression2 являются выражениями, то выражениями являются и expression1 + expression2
expression1 * expression2 (expression1).
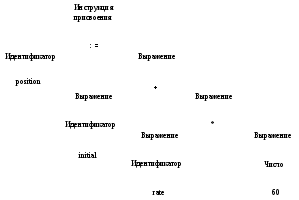
Рис. 1.4. Дерево разбора для выражения position: =initial+rate*60
Правила (1) и (2) являются базовыми (нерекурсивными), в то время как (3) определяет выражения с помощью операторов, применяемых к другим выражениям. Согласно правилу (1), initial и rate представляют собой выражения; правило (2) гласит, что 60 также является выражением. Таким образом, из (3) можно сначала сделать вывод, что rate*60 — выражение, а затем — что выражением является и initial+rate*60.
Точно так же многие языки программирования рекурсивно определяют инструкции языка правилами типа приведенных далее.
-
Если identifier1 является идентификатором, a expression2 — выражением, то identifier1 := expression2
есть инструкция.
-
Если expression1 — выражение, a statement2 — инструкция, то
while (expression1 ) do statement2
if ( expression1) then statement2
являются инструкциями2.
Разделение анализа на лексический и синтаксический достаточно произвольно. Обычно оно используется для упрощения анализа в целом. Одним из факторов, определяющих данное разделение, является использование рекурсии в правилах анализа. Лексические конструкции не требуют рекурсии, в то время как синтаксические редко обходятся без нее. Контекстно-свободные грамматики представляют собой формализацию рекурсивных правил, используемых при синтаксическом анализе. Данные грамматики рассматриваются в главе 2 и подробно изучаются в главе 4.
Например, рекурсия не нужна при распознавании идентификаторов, которые обычно представляют собой строки букв и цифр, начинающиеся с буквы. Распознать идентификатор можно с помощью простого последовательного сканирования входящего потока до тех пор, пока в нем не встретится символ, не являющийся символом идентификатора. После этого сканированные символы группируются в токен, представляющий идентификатор. Сгруппированные символы записываются в так называемую таблицу символов, удаляются из входного потока, и начинается сканирование следующего токена.
Однако такое линейное сканирование недостаточно для анализа выражений или инструкций. Например, мы не можем проверить соответствие скобок в выражениях или ключевых слов begin и end в инструкциях без наложения некоторой иерархической или вложенной структуры на вводимые данные.
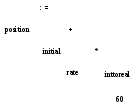

a) б)
Рис. 1.5. Семантический анализ добавляет преобразование из целого числа в действительное
Дерево разбора, показанное на рис. 1.4, описывает синтаксическую структуру поступающей информации. Более общее внутреннее представление этой синтаксической структуры представлено на рис. 1.5а. Синтаксическое дерево — это "сжатое" дерево разбора, в котором операторы размещены во внутренних узлах, а операнды оператора представлены дочерними ветвями узла, представляющего этот оператор. Построение подобных деревьев (рис. 1.5а) обсуждается в разделе 5.2. В главе 2, "Простой однопроходный компилятор", мы приступим к рассмотрению синтаксически управляемой трансляции (syntax-directed translation), а в главе 5, "Синтаксически управляемая трансляция", изучим ее подробнее. При синтаксически управляемой трансляции для построения вывода компилятор использует иерархическую структуру вводимой информации.
Семантический анализ
В процессе семантического анализа проверяется наличие семантических ошибок в исходной программе и накапливается информация о типах для следующей стадии — генерации кода. При семантическом анализе используются иерархические структуры, полученные во время синтаксического анализа для идентификации операторов и операндов выражений и инструкций.
Важным аспектом семантического анализа является проверка типов, когда компилятор проверяет, что каждый оператор имеет операнды допустимого спецификациями языка типа. Например, определение многих языков программирования требует, чтобы при использовании действительного числа в качестве индекса массива генерировалось сообщение об ошибке. В то же время спецификация языка может позволить определенное насильственное преобразование типов, например, когда бинарный арифметический оператор применяется к операндам целого и действительного типов. В этом случае компилятору может потребоваться преобразование целого числа в действительное. Проверка типов и семантический анализ обсуждаются в главе 6, "Проверка типов".
Пример 1.1
Битовое представление целого числа в компьютере, вообще говоря, отличается от битового представления действительного числа, даже если эти числа имеют одно и то же значение. Предположим, что все идентификаторы на рис. 1.5 объявлены как имеющие действительный тип, а 60 трактуется как целое число. При проверке типов на рис. 1.5а будет обнаружено, что оператор * применяется к действительному числу rate и целому 60. Обычно при этом осуществляется преобразование целого числа в действительное; на рис. 1.56 для этого создается дополнительный узел для оператора inttoreal, который неявно преобразует целое число в действительное. Однако, поскольку операнд оператора inttoreal представляет собой константу, компилятор может вместо этого сам заменить целую константу на эквивалентную действительную. □
Анализ в программах форматирования текста
В программах форматирования текста удобно рассматривать входную информацию как иерархию блоков (boxes). Эти блоки являются прямоугольными областями битовых образов, представляющих светлые и темные пиксели на выводящем устройстве.
Так, например, система TЕX ([260]) работает именно таким образом. Каждый символ,
который не является частью команды, представляет собой блок, содержащий битовый образ этого символа в определенном шрифте требуемого размера. Последовательные символы, не отделенные "разделителями" (пробелами или символами новой строки), группируются в слова, состоящие из последовательностей горизонтальных блоков, как схематически показано на рис. 1.6. Группирование символов в слова (или команды) представляет собой линейный, или лексический аспект анализа программы форматирования текста.
![]()
Рис. 1.6. Группировка символов и слов в блоки
В ТЕХ блоки могут быть построены из меньших блоков в различных горизонтальных и вертикальных сочетаниях. Например,
\hbox{ <список блоков> }
группирует список блоков, собранных по горизонтали. По вертикали блоки группируются с помощью команды \vbox. Таким образом, следующая конструкция в ТЕХ
\hbox{\vbox{! 1} \vbox{@ 2}}
представляет набор блоков, показанный на рис. 1.7. Определение иерархического расположения блоков, заданного входным потоком, является частью синтаксического анализа в ТЕХ.

Рис. 1.7. Иерархия блоков в ТЕС
Еще одним примером могут послужить математические препроцессоры EQN ([246]) и Т^Х, создающие математические выражения из операторов типа sub и sup для нижних и верхних индексов. Если EQN встречает входной текст вида
BOX sub box
он изменяет размеры блока box и присоединяет к блоку BOX справа внизу, как показано на рис. 1.8. Оператор sup приведет к блоку такого же размера, но размещенному справа вверху.
Рис. 1.8. Построение нижнего индекса в математическом тексте
Такие операторы могут использоваться рекурсивно, т.е. EQN-текст
a sub { i sup 2}
дает в результате аi . Группировка операторов sub и sup в токены представляет собой часть лексического анализа текста EQN. Однако для определения размера и размещения блоков требуется синтаксическая структура текста.