

Критерії бувають однобічні і двосторонні
У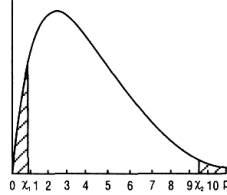
 випадку, коли H1 сформульована у
виді θ ≠ θ0, використовується
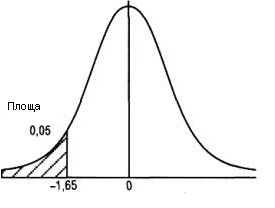
двосторонній критерій (рис. 7).
випадку, коли H1 сформульована у
виді θ ≠ θ0, використовується
двосторонній критерій (рис. 7).
Рис.7. Приклад критичної області для двостороннього і однобічного критерію
Якщо ж ми формулюємо Н1, у виді θ < θ0 (чи θ > θ0), то в цьому випадку використовується однобічний критерій (рис. 7).
Перевірка гіпотез звичайно проходить наступні етапи.
-
Визначення статистичної моделі. Тут висувають деякий набір передумов щодо закону розподілу випадкової величини і його параметрів. Наприклад, закон розподілу нормальний, величини незалежні й ін.
-
Формулюють Н0 і Н1.
-
Вибирають критерій (критеріальну статистику), що підходить до висунутої статистичної моделі.
-
Вибирають рівень значущості залежно від необхідної надійності висновків.
-
Визначають критичну область для перевірки Н0.
-
Розраховують значення обраного статистичного критерію для наявних даних.
-
Розраховане значення критерію порівнюють із критичним. і потім вирішують прийняти чи відхилити Н0.
Перевірка статистичних гіпотез здійснюється з допомогою різних статистичних критеріїв: параметричних або непараметричних. При виборі критерію, крім інших умов, необхідно враховувати чи вибіркові сукупності є зв’язаними чи незалежними. Прикладами перших сукупностей є вибірки з попарно зв’язаними варіантами (кількість гемоглобіну в крові пацієнтів до і після лікування, різні фізіологічні показники спортсменів до і після старту). Сукупності другого роду не зв’язані між собою і можуть мати різні обсяги (результати дослідження крові в декількох груп хворих з різними стадіями захворювання, результати дослідження піддослідної та контрольної груп тварин)
При виборі критерію необхідно завжди виходити з прикладної постановки задачі і природи даних.
Комп’ютерне розв’язування задач
У програмному забезпеченні "Star Office Spreadsheets" передбачена можливість вирішення багатьох важливих задач медичної біостатистики. При цьому забезпечується висока точність обчислень, можливість роботи з великими об’ємами статистичних даних.
Умовно відзначимо два рівні використання "Star Office Spreadsheets":
1. використання вмонтованих у "Star Office Spreadsheets" спеціальних функцій по статистиці;
2. використання вмонтованого у "Star Office Spreadsheets" пакету "STAT".
У "Star Office Spreadsheets" існує 78 функцій для проведення статистичних розрахунків. Щоб познайомитися з набором цих функцій, необхідно у вікні “"Star Office Spreadsheets" вибрати в меню опцію “Вставка”, а в меню, що з’явилося, вибрати опцію “Функція”. Далі у вікні меню, яке з’явилося, вибрати опцію “Статистичні”.
Основні статистичні функції електронних таблиць Star Office Spreadsheet
1. AVERAGE(число1;число2; ...) – повертає середнє вибіркове значення для вказаного варіаційного ряду, при цьому
(число1, число2,...) — від 1 до 30 числових аргументів, що відповідають вибірці з генеральної сукупності. Замість аргументів, розділених крапкою з комою, можна також використовувати масив або посилання на масив, наприклад A1:A10.
2. VAR(число1;число2;
...) – оцінює дисперсію по вибірці, при
цьому використовується формула
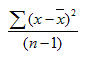
3. STDEV(число1;число2; ...) – повертає середнє квадратичне відхилення вибірки
4. MAX(число1;число2; ...) – повертає найбільше значення вибірки
5. MIN(число1;число2; ...) – повертає найменше значення вибірки
6. MEDIAN(число1;число2; ...) – визначає медіану вибірки
7. MODE(число1;число2; ...) – визначає моду вибірки
8. DEVSQ(число1;число2;
...) – обчислює суму квадратів відхилень
значень вибірки від середнього вибіркового
значення
![]() .
.
9. CONFIDENCE(;STDEV;n) – функція обчислення довірчих границь, при цьому
- рівень значущості (=1-, де - довірча ймовірність);
STDEV - середнє квадратичне відхилення вибірки;
n – об’єм вибірки.
10. ТТЕSТ(массив1;массив2;значення;тип) - повертає вірогідність, відповідну критерію Стьюдента, використовується, щоб визначити, наскільки вірогідно, що дві вибірки узяті з генеральних сукупностей, мають одне і те ж середнє вибіркове значення, при цьому
массив1 — перша вибірка.
массив2 — друга вибірка.
значення — число розподілу, яке дорівнює 1, коли функція ТТЕСТ використовує односторонній розподіл, і дорівнює 2, коли функція ТТЕСТ використовує двосторонній розподіл.
Тип — вид виконуваного t-тесту.
1 - парний двовибірковий t-тест для середніх значень (розраховує t-критерій Стьюдента для середніх значень двох вибірок без припущення про дисперсії. Використовується, коли є природна парність спостережень у вибірках, наприклад, генеральна сукупність тестується двічі)
2 - двовибірковий t-тест для рівних дисперсій. (розраховує t-критерій Стьюдента для середніх значень двох вибірок при рівних дисперсіях)
3 - Двовибірковий t-тест для нерівних дисперсій (розраховує t-критерій Стьюдента для середніх значень двох вибірок при нерівних дисперсіях).
Завдання:
-
Сформуйте таблицю значень випадкової величини (кількість вуглекислоти СО2 в альвеолярному повітрі) в електронних таблицях Spreadsheet (рис 4).
-
Використовуючи вбудовані функції обчисліть
-
кількість елементів вибірки
-
середнє вибіркове значення;
-
дисперсію вибірки;
-
середнє квадратичне відхилення вибірки;
-
найбільше значення вибірки;
-
найменше значення вибірки;
-
медіану вибірки;
-
моду вибірки.
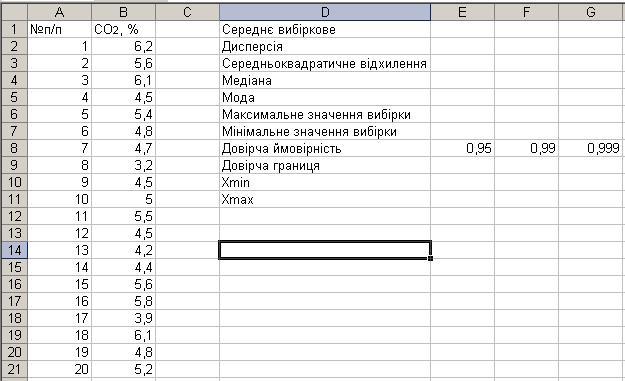
Рис.4. Результати спостережень.
-
Визначте довірчий інтервал для вказаних на рис.4 довірчих ймовірностей:
-
використовуючи функцію CONFIDENCE обчисліть довірчі границі x;
-
визначте мінімальне значення довірчого інтервалу
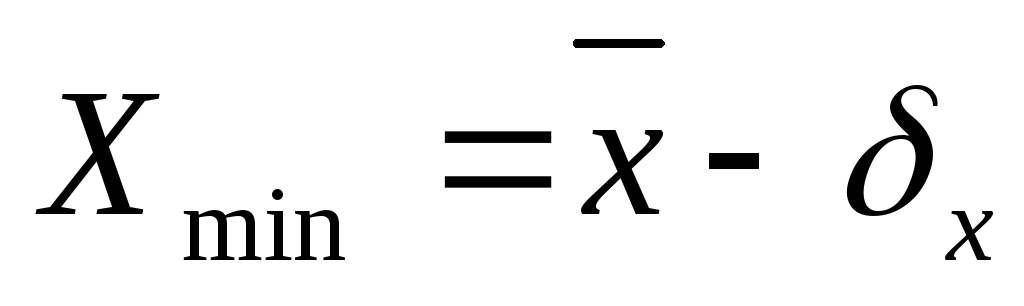
-
визначте максимальне значення довірчого інтервалу

-
У таблиці наведено дані двох незалежних вибірок розміру пухлини карциноми Герена на четвертий день захворювання і отриманих внаслідок дослідження впливу магнітними полями низької частоти на новоутворення
|
Номер досліду |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
|
Номер вибірки |
1 |
0,027 |
0,036 |
0,1 |
0,12 |
0,32 |
0,45 |
0,049 |
0,105 |
|
2 |
0,075 |
0,4 |
0,08 |
0,105 |
0,075 |
0,12 |
0,06 |
0,075 |
|
Визначте, наскільки ймовірно, що дві вибірки взяті з генеральних сукупностей, мають одне і те ж середнє вибіркове значення, використовуючи функцію ТТEST.
5. Вага 3-х місячних немовлят, які народилися у різних містах, підпорядкована нормальному закону із середнім вибірковим значенням 5 кг і середньоквадратичним відхиленням 0.1. Знайти ймовірність того, що навмання взяте немовля цього ж віку:
а) важить менше 4.8 кг;
б) важить більше 5.1 кг;
в) вага немовляти є у межах від 4.8 до 5.1 кг.
У випадку нормального розподілу випадкової величини використовуємо функцію NORMDIST(number, mean, STDEV, c),
де number – значення, для якого будується розподіл;
mean – середнє вибіркове значення розподілу m;
STDEV – середньоквадратичне відхилення σ;
c – логічне значення,
c=0, якщо розглядається щільність розподілу
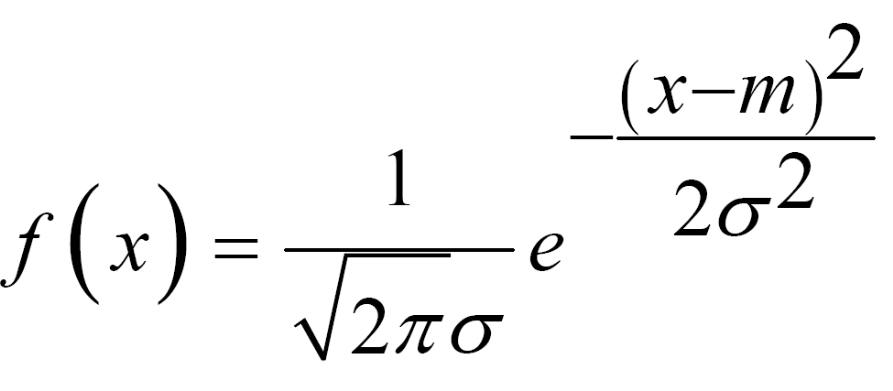 ,
,
с=1, якщо розглядається функція розподілу

За умовою задачі “середнє вибіркове значення” - m=5 і “середньоквадратичне відхилення” - σ=0.1. Будуємо таблицю (рис. 5).
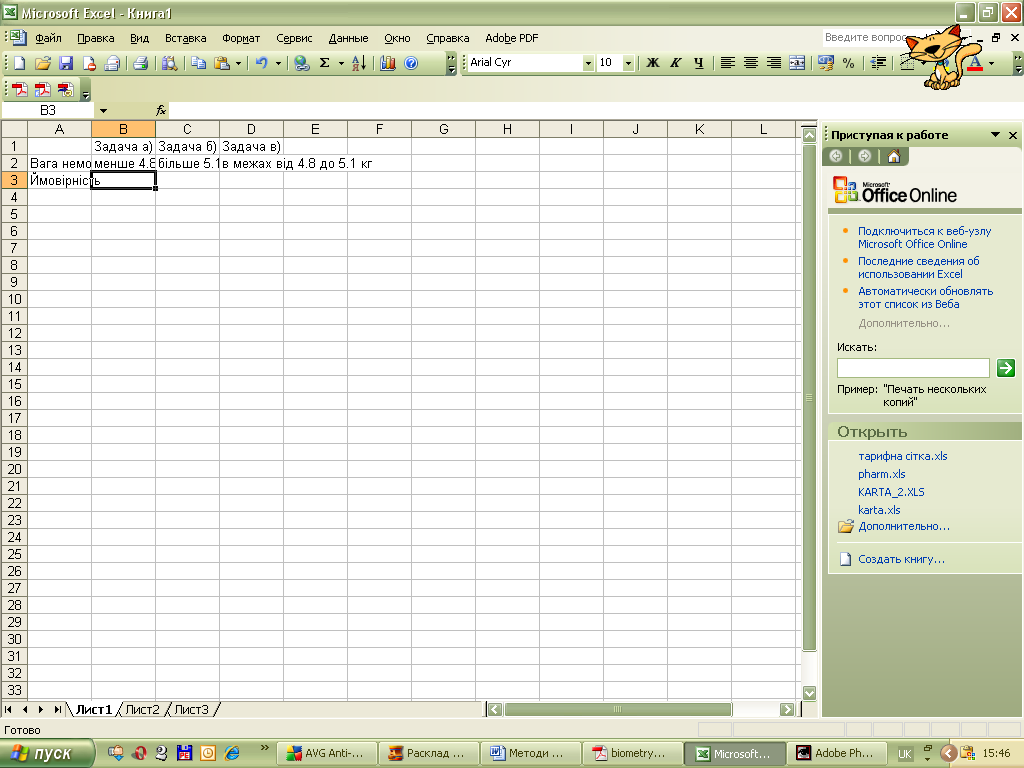
Рис. 5
Далі розглядаємо такі випадки:
а) для підрахунку ймовірності Р(X<4.8) події, що навмання взяте немовля важить менше 4.8 кг, використаємо функцію NORMDIST(4.8; 5; 0.1; 1). Для цього активізуємо комірку В3. Вибираємо команди: “INSERT”(«Вставка»), “FUNCTION”(Функція»), “STATISTICAL”(Статистичний») і NORMDIST. У вікні меню функції NORMDIST, що з’явилося, набираємо параметри задачі. Результат Р(X<4.8)=0.02275 можна прочитати у меню функції. Після натиснення клавіші ”ОК” він автоматично заноситься у комірку В3
б) Для підрахунку ймовірності Р(X>5.1) події, що навмання взяте немовля важить більше 5.1 кг, використаємо співвідношення: Р(X>5.1)=1 - Р(X<5.1).
Для цього активізуємо комірку С3. Далі набираємо функцію
=1 - NORMDIST(5.1; 5; 0.1; 1).
Після натиснення клавіші “Enter”, результат Р(X>5.1)=0.158655 автоматично заноситься у комірку С3.
в) Для підрахунку ймовірності Р(4.8<X<5.1) події, що вага навмання взятого немовляти є у межах від 4.8 до 5.1 кг, використаємо співвідношення:
Р(4.8<X<5.1) =Р(X<5.1) - Р(X<4.8).
Для цього активізуємо комірку D3. Потім набираємо функцію
= NORMDIST(5.1; 5; 0.1; 1) – NORMDIST(4.8; 5; 0.1; 1).
Після натиснення клавіші “Enter”, результат Р(4.8<X<5.1) =0.8186 автоматично заноситься у комірку D3.
-
Використовуючи функцію BINOMDIST(x; trials; sp; c),
де “x” – кількість успішних випробувань m;
“trials” – число незалежних випробувань n;
“sp” – ймовірність успіху кожного випробування p;
“c” – логічне значення, що визначає форму функції:
c=0, якщо
![]() (ймовірність
події, яка полягає в тому, що, в серії з
n випробувань отримаємо рівно m
успіхів),
(ймовірність
події, яка полягає в тому, що, в серії з
n випробувань отримаємо рівно m
успіхів),
с=1, якщо
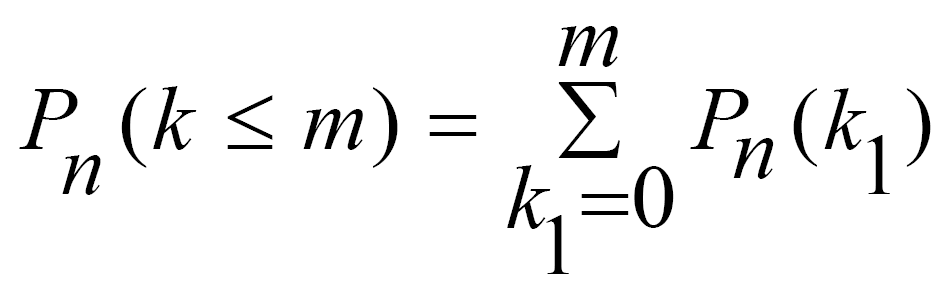 (ймовірність події, яка полягає в тому,
що в серії з n випробувань отримаємо не
більше m успіхів)
(ймовірність події, яка полягає в тому,
що в серії з n випробувань отримаємо не
більше m успіхів)
Після багаторічних спостережень виявилося, що ймовірність зараження обстежуваних пацієнтів у стоматолога вірусом гепатиту складає 0.4. Припустимо, що в певний день випадковим чином відібрано 25 пацієнтів, визначити ймовірність таких подій:
а) вірусом гепатиту будуть заражені рівно 10 пацієнтів;
б) не більше 10 пацієнтів;
в) не менше 10 пацієнтів;
г) від 10 до 15 пацієнтів.
Рекомендована література
-
В.Ю. Урбах. Статистический анализ в биологических и медицинских исследованиях. - М.: Высшая школа, 1975.
-
В.Е. Гмурман. Теория вероятностей и математическая статистика. - М.: Высшая школа, 1980.
-
Г.Ф. Лакин. Биометрия.-М.: Высшая школа, 1990.
-
А. Гончаров. Microsoft Excel 97 в примерах. - С.-Пб.: Питер, 1997.
-
О.І. Конділенко, М.І. Міщенко. Похибки вимірювань фізичних величин: Методичні рекомендації до лабораторного практикуму з курсу загальної фізики. - Житомир: ЖІТІ, 2000.-46 с.
-
Гихман Й.И., Скороход А.В., Ядренко М.Й. Курс теории вероятностей и математической статистики. – К.: Вища школа, 1979. – 407с.
-
Нейман Ю. Вводный курс теории вероятностей и математической статистики. – М.: Наука, 1980. – 448 с.