

3.2 Пример использования Minitab for Windows для построения уравнений регрессии
Пример выполнения задания 1.
1 Ввести данные в Minitab for Windows
2 Для запуска процедуры анализа регрессии выбрать команду StartRegressionRegression
3 На экране раскроется диалоговое окно Regression (регрессия), представленное на рис. 2.
а) в поле Response в качестве зависимой переменной выбрать величину C1 (объемы продаж)
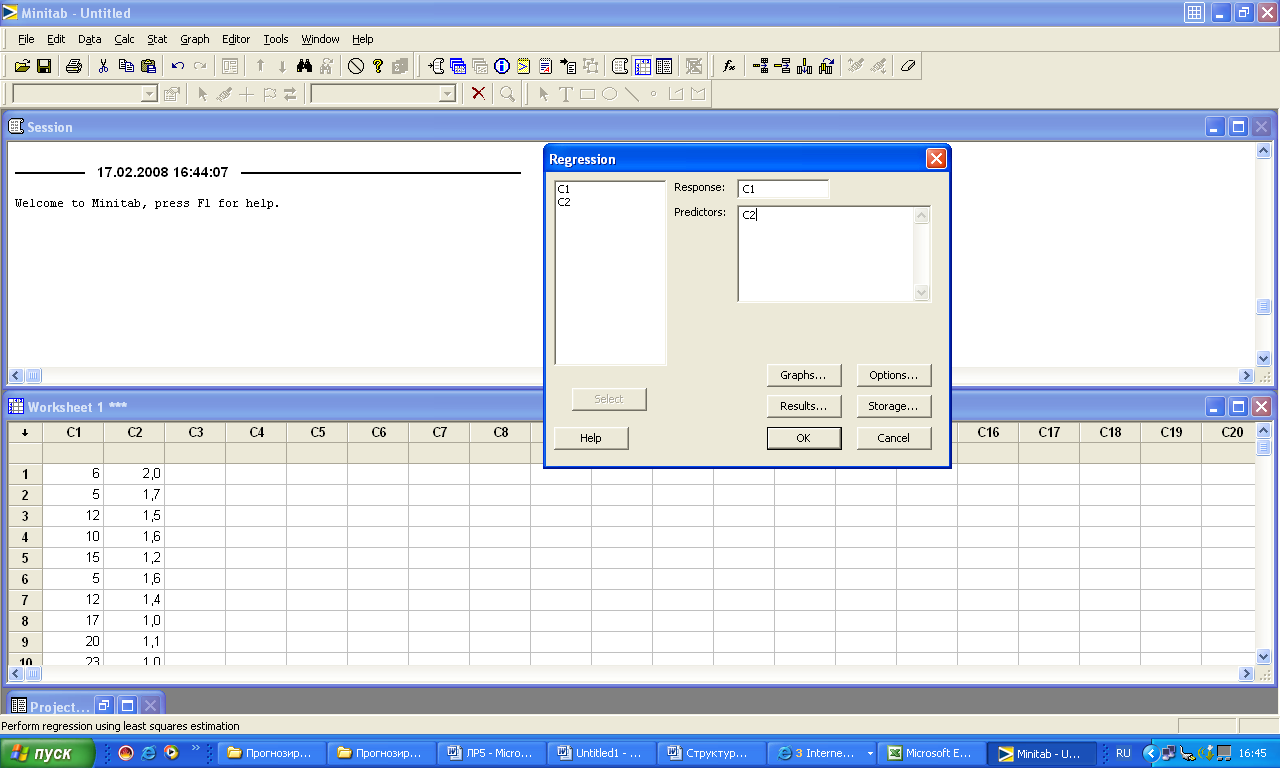
Рис. 2. Диалоговое окно Regression приложения Minitab
б) в поле Predictors в качестве независимой переменной выбрать величину C2 (цена)
в) для продолжения работы щелкнуть на кнопке Storage
4 На экране раскроется диалоговое окно Regression - Storage (Регрессия - сохранение), показанное на рис. 3.

Puc. 3. Диалоговое окно Regression - Storage приложения Minitab
а) чтобы сохранить значения остатков в столбце СЗ, в группе Diagnostic Measures (Диагностические значения) установить флажок опции Residuals (Остатки),
б) чтобы сохранить прогнозируемые значения Y в столбце С4, в группе Characteristics of Estimated Equation (Характеристики оцениваемого уравнения) установить флажок опции Fits
в) щелкнуть на кнопке ОК, и на экран будут выведены результаты, представленные в листинге (рис. 4).
Ниже объясняется используемая в приложении Minitab терминология, даются необходимые определения и описываются выполняемые вычисления. Все эти пояснения относятся к содержимому листинга, представленного на рис. 4.
-
Coef - коэффициент регрессии, равный -17,481. Эта величина показывает изменение Y (продажи), если X (цены) изменяется на единицу (
 ).
Если цена увеличивается на одну гривну,
оценка объема продаж уменьшается на
17,481 единиц.
).
Если цена увеличивается на одну гривну,
оценка объема продаж уменьшается на
17,481 единиц.
|
Regression Analysis: C1 versus C2
The regression equation is C1 = 36,9 - 17,5 C2
Predictor Coef SE Coef T P Constant 36,884 3,462 10,65 0,000 C2 -17,481 2,368 -7,38 0,000
S = 2,42943 R-Sq = 81,9% R-Sq(adj) = 80,4%
Analysis of Variance Source DF SS MS F P Regression 1 321,53 321,53 54,48 0,000 Residual Error 12 70,83 5,90 Total 13 392,36 |
Рис.4. Листинг результатов регрессионного анализа
-
SE Coef - стандартная ошибка коэффициента регрессии, равная 3,462. Это значение является стандартным отклонением выборочного распределения значения коэффициента регрессии.
-
Т - вычисленное t-значение, равное -7,38. Вычисленное t-значение используется для оценки, насколько заметно коэффициент регрессии
 ,
генеральной совокупности отличается
от нуля. Так как t
= -7,38, то регрессионная зависимость
имеет место уже на уровне значимости
1% (табличное значение при n-2=13
степеней свободы
,
генеральной совокупности отличается
от нуля. Так как t
= -7,38, то регрессионная зависимость
имеет место уже на уровне значимости
1% (табличное значение при n-2=13
степеней свободы
 )
) -
Constant - свободный член уравнения регрессионной прямой, равный 36,884. Это то значение, в котором регрессионная прямая пересекает ось Y(60). Отсюда следует, что общее уравнение регрессии имеет следующий вид:
C1 = 36,9 - 17,5 C2
-
S - стандартная ошибка оценки (
 ),
равная 2,42943. Она показывает, что обычно
значения Y
отклоняются от прямой регрессии на
2,42943 единиц.
),
равная 2,42943. Она показывает, что обычно
значения Y
отклоняются от прямой регрессии на
2,42943 единиц. -
Р - значение, равное 0,000, определяет вероятность того, что вычисленный коэффициент регрессии будет получен при выполнении гипотезы
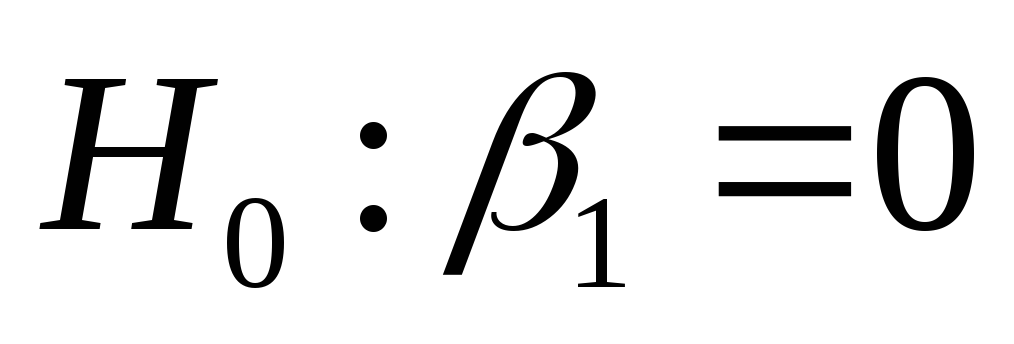 .
Поскольку величина Р исключительно
мала, можно сделать заключение, что
вычисленная величина углового
коэффициента регрессии значима.
.
Поскольку величина Р исключительно
мала, можно сделать заключение, что
вычисленная величина углового
коэффициента регрессии значима. -
R-Sq - значение
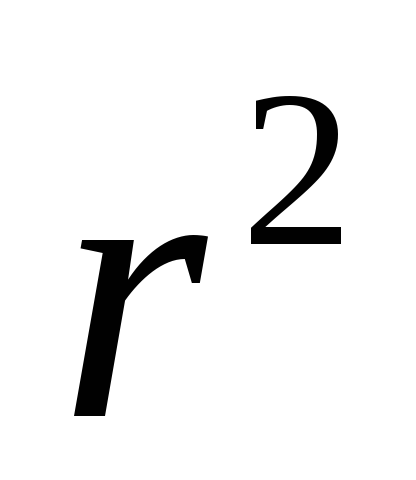 ,
равное 81,9% . Вычисленная прямая регрессии
объясняет 81,9% изменчивости объема
продаж.
,
равное 81,9% . Вычисленная прямая регрессии
объясняет 81,9% изменчивости объема
продаж. -
R-Sq(adj) - скорректированное значение
 ,
равное 80,4%. Значение
,
равное 80,4%. Значение
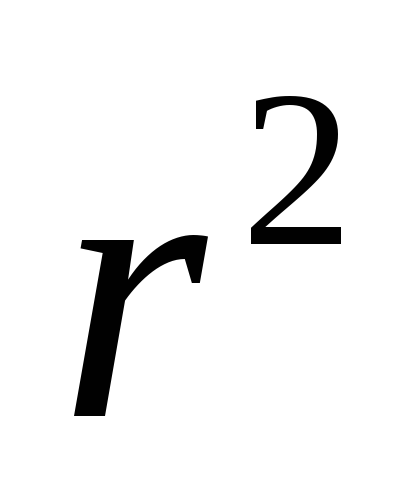 корректируется для соответствующих
степеней свободы.
корректируется для соответствующих
степеней свободы. -
SS - сумма квадратов ошибок (Residual Error) (SSE), равная 70,83.
-
Total - общая сумма квадратов ошибок (SST), равная 392,36.
-
F - анализ дисперсии и отношение F, равное 54,48. Значение отношения F в этой таблице ANOVA проверяет нулевую гипотезу о том, что регрессионная зависимость незначима, т.е. верна гипотеза
 .
Большое значение F позволяет отклонить
эту гипотезу, предполагая значимость
регрессии для имеющихся данных. Величина
F становится больше, когда увеличивается
доля общей суммы квадратов отклонений,
объясняемая регрессией. В этом случае
табличное значение F (df = 1, а = 0,01) равно
9,07. Поэтому гипотеза о незначимости
регрессии отклоняется на уровне
значимости 1%, поскольку F=54,48>9,07.
.
Большое значение F позволяет отклонить
эту гипотезу, предполагая значимость
регрессии для имеющихся данных. Величина
F становится больше, когда увеличивается
доля общей суммы квадратов отклонений,
объясняемая регрессией. В этом случае
табличное значение F (df = 1, а = 0,01) равно
9,07. Поэтому гипотеза о незначимости
регрессии отклоняется на уровне
значимости 1%, поскольку F=54,48>9,07.
5 Чтобы получить графики остатков, выбрать команду Starts Regressions Residual plots.
6 На экране раскроется диалоговое окно Residual Plots (Графики остатков).
а) в поле Fits ввести значение FITS1 или С4
б)в поле Residuals ввести значение RESI1 или СЗ
в) в поле Title ввести значение Residual Plots for С1
г) щелкнуть на кнопке ОК, и на экран будут выведены графики, показанные на рис. 5

Рис.5 Графики остатков
Гистограмма центрирована относительно нулевого значения. Хотя данная гистограмма и симметрична, все же она не выглядит очень хорошо сглаженной. Однако для всего небольшого количества наблюдений гистограмму, подобную приведенной на рис. 5, не следует расценивать как нетипичную для нормально распределенных данных. Поэтому предположение о нормальности в данном случае вполне естественн0.
Второй график на рис. 5 также выглядит достаточно хорошо. График остатков, расположенных напротив оцениваемых величин, не "изгибается", как в случае, например, когда серия положительных остатков следует после серии отрицательных, после чего опять идет серия положительных остатков. В такой ситуации следует предположить наличие нелинейной взаимосвязи между значениями Y и X. Также нормальным является то, что график не характеризуется конической формой, что указывало бы на непостоянную (возрастающую) изменчивость в данных.
В исследуемых данных величина Y представляет недельные объемы продаж, однако недели были выбраны случайно и не являются упорядоченными во времени. Следовательно, построение графика остатков по времени или вычисление коэффициентов автокорреляции остатков в данном случае неуместно.
Таким образом, модель прямолинейной регрессии адекватно описывает взаимосвязь между объемами продаж молока и его ценой.
6 Для определения прогнозного объема продаж воспользоваться теоретическими положениями, изложенными в п.2.3.
Пример выполнения задания 2
1 Ввести в рабочий лист приложения Minitab исходные данные.
2 Чтобы получить диаграмму рассеивания, выбрать команду Graph Plot.
3 На экране раскроется диалоговое окно Plot.
а) в группе Graph Variables выбрать значения С1 (Объемы продаж) в качестве переменной Y и С2 (Расходы на рекламу) - в качестве переменной Х.
б) щелкнуть на кнопке ОК, и на экран будет выведен график, показанный на рис. 6.

Рис. 6 Диаграмма рассеивания
По графику видно, что после достижения некоторого уровня объемы продаж возрастают с меньшей скоростью.
4 Для получения модели прогноза, выбрать команду StatRegressionFitted Line Plot.
5 На экран будет выведено диалоговое окно Fitted Line Plot (график прямой регрессии).
а) в качестве зависимой переменной (Y) в поле Responce выбрать значение С1
б) в качестве независимой переменной (X) в поле Predictor выбрать значение С2
в) установить переключатель выбора модели в одно из возможных положений - Linear (линейная), Quadratic (квадратичная) или Cubic (кубическая). Для определенности предположим, что переключатель был установлен в положение Linear
г) щелкнуть на кнопке ОК. На экран будет выведен график, представленный на рис. 7.
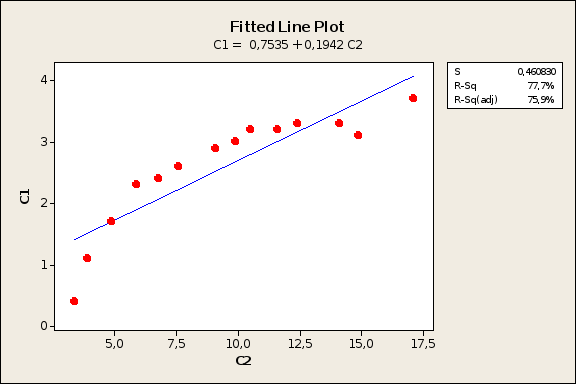
Рис.7. Прямая регрессии
6 Теперь, чтобы преобразовать значения переменной X в натуральные логарифмы X, выбрать команду CalcCalculator.
7 На экран будет выведено диалоговое окно Calculator (калькулятор).
а) в поле Store results in variable ввести значение СЗ
б) чтобы выполнить требуемое преобразование, в списке Functions (функции) выбрать значение Natural log
в) щелкнуть на кнопке Select (выбрать), и под ней будет выведено значение LOGE (number). Аналогичное значение появится также в поле Expression.
г) поскольку преобразуемой переменной являются Расходы на рекламу, значения которой находятся в столбце С2, в поле Expression значение number будет заменено на С2
д) щелкнуть на кнопке ОК, и значения натурального логарифма X появятся в столбце СЗ
8 Для полученных значений построить уравнение регрессии и провести его анализ.
9
Аналогично провести преобразования
![]() .
Из всех рассмотренных моделей выбрать
адекватную.
.
Из всех рассмотренных моделей выбрать
адекватную.