

11.Особливості оптимізації для процесораPentiumPro.
Розгортання циклів
Розгортання циклів є технікою компілятора, яка збільшує доступний паралелізм в програмному коді завдяки збільшенню лічильників циклу на числа, більші ніж одиниця.
Можливість передбачення переходу процесора Pentium Pro зменшує потребу для розгортання циклів джерела компілятора.
Часткові простої
Часткові простої відбуваються, коли довге читання слідує за коротким записом до того ж архітектурного регістра. Наприклад, припустимо, що 2-байтова команда addw, яка пише до регістра %ax, йде перед 4-байтовою командою addl, яка читає з регістра %eax.
Процесор Pentium Pro не має пристрою, який може прочитати два байти від addw в ROB і два байти від регістру, так що команда addl повинна стати в чергу на стадії RAT/Allocator, поки результати addw пишуться в регістр.
Невирівняні доступи
Процесори архітектури Intel, включаючи процесор Pentium Pro, не найкраще працюють, коли зчитування або запис виконуються до не вирівняних даних.
Тут невирівнювання даних означає, що процесору буде необхідно зробити більше ніж одне звертання до пам'яті, щоб мати доступ до даних. Це відбувається при доступі до багатобайтової змінної, чия область дії не може адресуватися цілком послідовними змінами лише до 3 нижчих адресних бітів. Невирівняні доступи зменшують продуктивність виконання коду. Величина покарання залежить від послідовностей зовнішнього коду.
Якщо не вирівнювання даних перетинає границю рядка кешу, що означає невирівнювання всередині 32-байтових зон, зменшення продуктивності зростає.
Програма для оптимізації асемблерного коду
Лістинг
#include <iostream>
#include <string>
#include <algorithm>
#define ADD "add"
#define MOV "mov"
#define INC "inc"
#define JMP "jmp"
using namespace std;
struct Com
{
string Command, Register;
int M;
};
int cmp( Com X, Com Y )
{
return X.M < Y.M;
}
int main()
{
int i, N, K1 = 1, K2 = 0;
cout << "Enter the number of commands: ";
cin >> N;
Com *A = new Com [N];
cout << endl << "Start typing the command" << endl;
for ( i = 0; i < N; ++i )
{
cout << "#" << i + 1 << ": ";
cin >> A[i].Command >> A[i].Register;
if ( A[i].Command == ADD || A[i].Command == MOV || A[i].Command == INC || A[i].Command == JMP )
{
A[i].M = K1;
++K1;
if ( !( K1 % 3 ) )
++K1;
}
else
{
A[i].M = K2;
K2 += 3;
}
}
sort( A, A + N, cmp );
cout << endl << "Optimized code" << endl;
for ( i = 0; i < N; ++i )
cout << A[i].Command << " " << A[i].Register << endl;
system("pause");
return 0;
}
Результати роботи програми
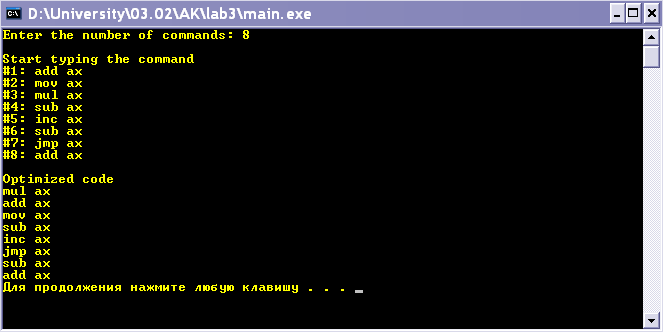
Висновок. На цій лабораторній роботі я ознайомився з особливостями архітектури Pentium Pro та Pentium ІІ. Створив програму, яка здійснює оптимізацію асемблерного коду.