

Хеш таблицы.
Для хеш таблиц требования к памяти немного снижается, но время поиска остается U(1). При хешировании ключ к->h(k). Отображает пространство ключей, адреса — это номера. h:U-> {0,1…,m-1}. Цель хеш функции состоит в уменьшении диапазона индексов массива: Вместо u значений обходимся m значений, но 2 или более ключей отобразиться в одной ячейке, будет конфликт.
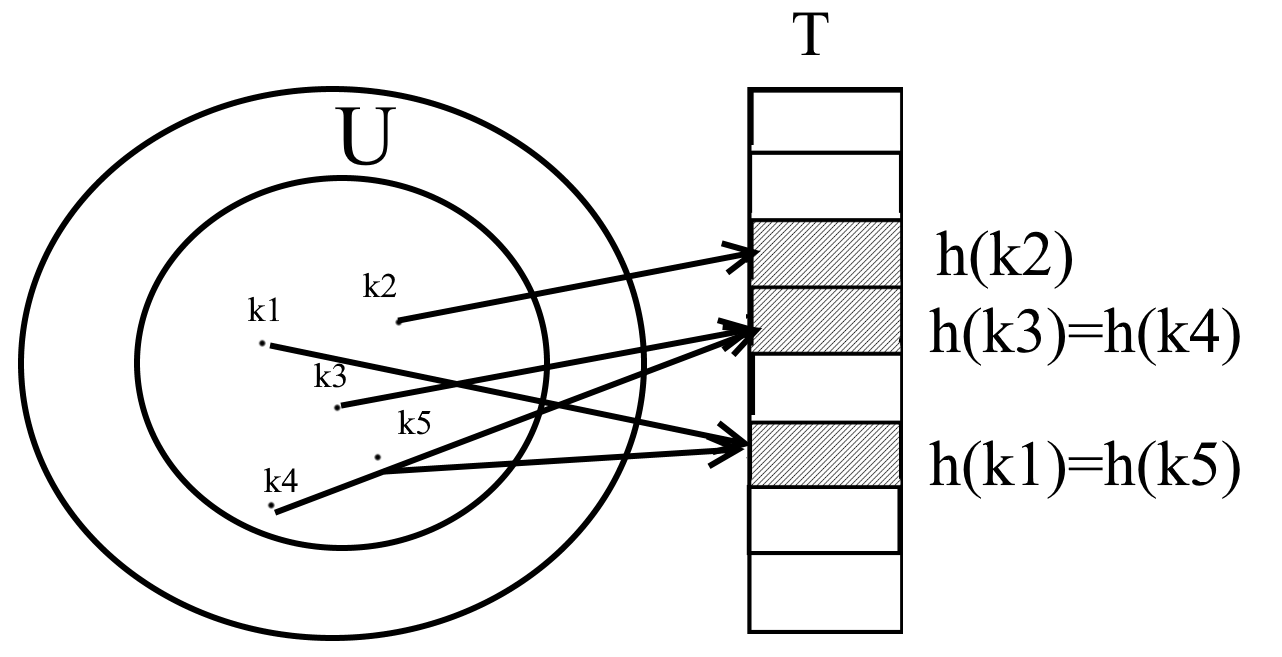
При организации хеш таблиц стараются ликвидировать все коллизии. Можем попытаться это сделать путем выбора функции h. Основная идея сделать h случайной функцией. Хеш функция избавиться от конфликтов не позволит, но хотя бы минимизировать число. h должны быть однозначной. Всегда нужен метод разрешения коллизии.
Решения коллизий при помощи цепочек (цепные списки)
При использовании этого метода объединяем все ключи хеширование в одну и ту же ячейку связанные в цепной список.
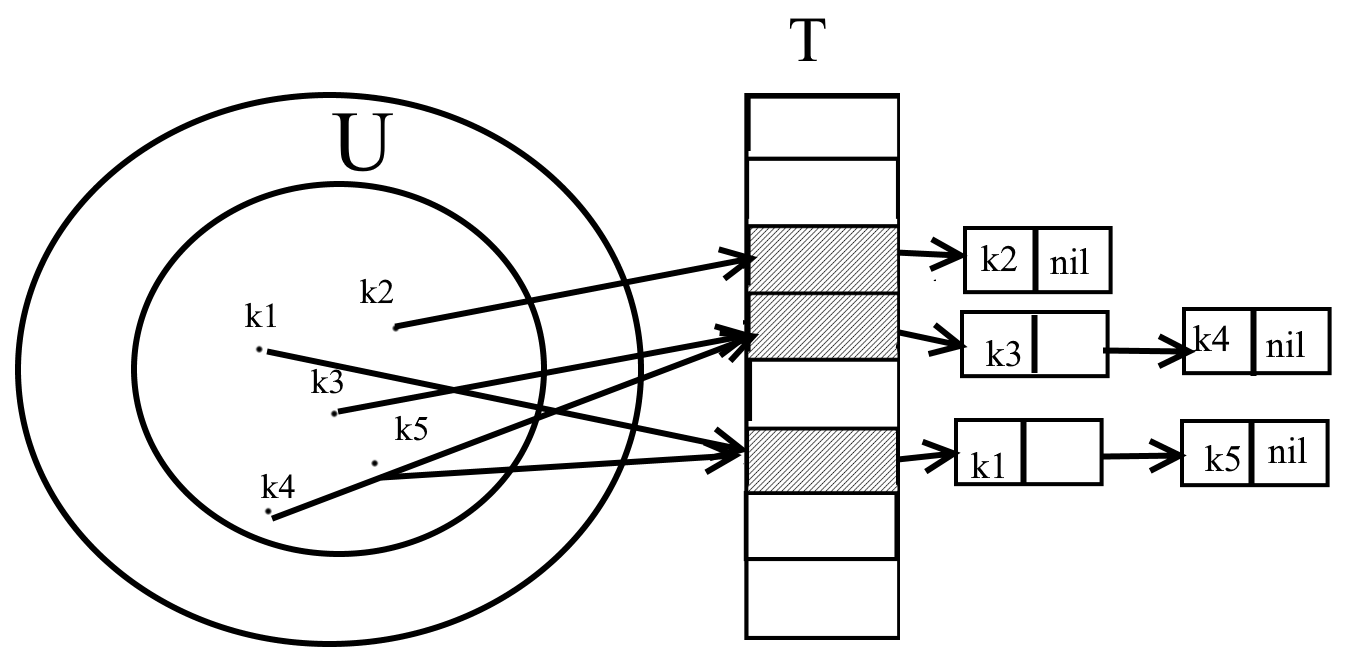
Инициализируем Nil’ами.
В ячейках j таблицы T содержит указатель на заголовок списка всех элементов, хеш значение ключа которых равно j. Если таких элементов нет, ячейка содержит nil.
Словарные операции:
Поиск
Вставка
Удаление
K – ключ, x – объект с полным набором информации включая ключ.
Hash_search (T,k) поиск элемента с ключом в списке T[h(k)]
Hash_insert (T,x) если списки представляют собой стеки, то вставки в голову списка. Вставить х в заголовок списка T[h(x,k)]
Hash_delete (T,x) удаление х из списка T[h(x,k)]
Время работы поиска пропорционально длине списка, но предпочтительнее организация двусвязного списка (в каждом элементе 2 ссылке на следящий и предыдущий). Эффективнее отработает delete. Наихудший случай, когда все отображается в одну и ту же ячейку, тогда хеш таблица вырождается в связанный список длины n. Это бессмысленно.
Хеш функции
Качественная хеш функция должна удовлетворять простого равномерного хеширования:
Для каждого ключа равно вероятно размещение в любую из m ячеек, независимо от хеширования остальных ключей.
Пр. рассмотрим таблицу символов компилятора, где ключами служат символьные строки, идентификатора программы. Часто в одной программе строят похожие. Хорошая хеш функция должна минимизировать шансы попадания этих идентификаторов в одну ячейку таблицы T. Хорошо если хек функция никак не коррелирует (взаимодействует) с данными. Остаток от деления это неплохая хеш фикция k mod p.
Для большинства хек функций пространство множество целых неотрицательных чисел. Если ключи не являются не отрицательны, то их кодируют в целые числа. Например, строка символов может записана как целое число в соответствующей системе счисления.
P pt=112*128+116=11452 p1 p2 (112,116)
Первая хеш функция – метод деления. ? состоит в отображении ключа к в одну из ячеек путем получения остатка от деления k на размер хеш таблицы. k mod m m=12 k=100 H(k)= 100 mod 12=4 Очень быстрая т.к. требуется одна операция. Стараются избегать некоторых значений m, m<>2^p ,p иначе значение представляется p младших битах числа к. Часто выбирают число далекое в степени 2.
N=2000 1 байт = 8 бит
Нас устраивает проверка ?. тогда выбирают m=n/3=2000/3 И не являющейся степенью 2ки. h(k)=k mod 701.
2 метод – умножения. Построение функции здесь идет в 2 этапа. Сначала умножаем 0<A<1 k*A-[k*a] ( от полного произведения отниму целую часть) =(k*A)mod1 Затем умножаем полученное на m и берем целую часть trunk(m*(k*a)mod1)) тогда m перестает быть критичным, тогда цепляются за степень двойки m=2^p. Хорошо если A константа золотого сечения.
L1/L=L2/L1
L^2=l*l2 l1^2-l1l2-l2^2=0 [:l2^2] (l1/l2)^2-l1/l2-1=0 l1/l2=x
X1=0,382 x2=0,618 – наилучшее
W битов к А ограничим s/2w s – целое число из диапазона A<S<S^w S=A*2^w результат представляет собой 2^w битовое число r1*2^2+r0
Старшие p битов числа r0 - искомое pбитовое хеш значение.
(4) Wб
К
S=A*2^w r1 r0 h(k)
Третий способ – универсальное кеширование.
Любая фиксированная хеш функция уязвима. Значит случайный выбор хеш функции. Независящий от ключей с которой ей нужно работать. Это подход универсального хеш. Здесь осуществляется случайный выбор хеш ф-й из некоторого класса ф-й в начале работе программы. Рандомизация гарантирует, что одни и те же входные данные не могут давать наихудшие поведения алгоритмов.
Пусть H конечное множество хеш функций, которая отображает пространство ключей U H:U-> {0,..,m01} H называется универсальным, если для каждой пары различных ключей существуют хеш функции ? и их количество, для которых возникает коллизия не превышает все пространство H/m.
При случайном выборе хеш функции из H коллизия между различными ключами k,l не превышает вероятности совпадения 2х случайно выбранных хеш значений из множества от 0 до m-1 и она равна 1/m
Построение универстального ?
Нечем построение с выбора пятого числа p достаточно большого чтобы все возможные ключи находились в диапазоне от 0 до P-1 . p:0 to (p-1) Zp:{0,1,..,(p-1)} Zp*:{1,2,..,(p-1)}
Из предположения что пространство ключей больше чем пространство чем хеш таблицы следует p>m. Теперь определим хеш функцию. (5)
Ha,b=((a*k+b)mod m
Пр. p=17 h3;4(8)=(3*8+4)mod 17 mod6=11 mod 6=5
Попали в 5 список этой ячейки. Имеем семейство функции Hp,m это семейство состоит и множество функций, где {ha,b:a э Zp*, э zp} ha,b:Zp->Zm
Этот класс функций обладает тем свойством что размер m выходного диапазона произволен.
а (p-1) способами, b p способами. p(p-1) функций получили.
Открытая адресация
При использовании этого метода все данные хранятся в хеш таблице. Каждая запись таблицы содержит либо элемент либо nil. При поиске в такой таблице мы будет систематически проверять ячейки таблицы до тех пор, пока не найдем искомый элемент, или убедимся в его отсутствии. ?. хеш таблица может оказаться заполненной ?. Преимущество отказ от указателей. При возникновении коллизии здесь вместо исследования цепных списков будем по определенному алгоритму строить трассу исследования. Т.е. вычислять последовательность проверяемых ячеек хеш таблицы. Вместо фиксированных последовательность исследуемых ячеек данном зависит от? Расширяем хеш функцию включая второй аргумент номер исследования начинается с 0.
H:U*{0,1,..,m-1}->{0,1,..,m-1}
В этом методе требуется, чтобы для каждого ключа последовательность исследований {h(k,0),h(k,1),…,h(k,m-1))} {0,1,..,(m-1)}
Запишем схемы вставки и поиска.
Hash_insert
(T,k)

i=0
j=H(j,i)



Tj=nil
End
Tj=k

+

i=i+1


+ -
i<m
Вывод «таблица полная»


Type mas=array [1..50]
Procedure
Hash_search (T:mas; k:integer; j:integer);

i=0
j=H(k,i)




- +
Tj=k
Return j
End
i=i+1






+
(Tj=Nil) or (i>=m)
Return j=nil

Процедура удаления элемента из хеш таблицы сложная, т.к. при удалении ключа из ячейки i мы не можем ее заменить на значение nil, потому что эта ячейка может лежать на трассе исследования другого ключа. Сделав ее пустой, мы делаем невозможным поиск этого ключа. Помечать такие ячейки специальным значений. При ставке писать в ячейку можно, при поиске считать занятой.
Для вычисления последовательности исследования для открытого адреса используется 3 метода
Линейное
Квадратичное
Двойное хеширование
Пусть задана обычная хэш функция
h’:U->{0,1,..,m01}
Эту функцию h' будем называть вспомогательных метод линейных исследований для вычисления трасы исследований.
H(k,i)=(h’(k)+i)mod m i:=0,…,m-1
Для заданного ключа k T[h’(k)] Далее исследуем ячейку с номером T[h’(k)+1]
T[m-1] T[0] T[h’(k)-1]
В этом методе начальная ячейка однозначно определяет всю последовательность исследований целиком. Всего последовательностей m- размер хеш таблицы.
Линейное исследование легко реализуется, но с ним связна проблема первичной кластеризации.
Созданием длинных последовательностей занятых ячеек. Это увеличивает время поиска.
H(k,i)=(h’(k)+c1i+c2i^2) mod m
H’(k) вспомогательная хеш функция c1, c2 вспомогательные константы
Остальные исследовательные позиции смещены относительно ее величины описываются квадратичной зависимостью от номера исследования i. Метод работает лучше линейного исследования, но чтобы эта система охватила все ячейки хеш таблицы, необходим выбор специальных значений c1,c2 и таблицы m.
H1(k,0)=h2(k,0)
То одинаковы и послед исследования в целом для этих ключей.
? начальная ячейка определяет всю поссл трассы => m различных последовательностей. Имеется ключ k который надо найти в таблице T[0…(m-1)] h:U->{0,1,…,(m-1)] Тогда схема мб следующей
Вычисляем значение i=h(k) и присваиваем j=0
Исследуем ячейку T[k]=k и поиск прекращаем, если истина, или ячейка пуста
J=(j+1) mod m; i=(i+j) mod m