

- •Credits
- •About the Authors
- •About the Reviewers
- •www.PacktPub.com
- •Table of Contents
- •Preface
- •Introduction
- •Installing Groovy on Windows
- •Installing Groovy on Linux and OS X
- •Executing Groovy code from the command line
- •Using Groovy as a command-line text file editor
- •Running Groovy with invokedynamic support
- •Building Groovy from source
- •Managing multiple Groovy installations on Linux
- •Using groovysh to try out Groovy commands
- •Starting groovyConsole to execute Groovy snippets
- •Configuring Groovy in Eclipse
- •Configuring Groovy in IntelliJ IDEA
- •Introduction
- •Using Java classes from Groovy
- •Embedding Groovy into Java
- •Compiling Groovy code
- •Generating documentation for Groovy code
- •Introduction
- •Searching strings with regular expressions
- •Writing less verbose Java Beans with Groovy Beans
- •Inheriting constructors in Groovy classes
- •Defining code as data in Groovy
- •Defining data structures as code in Groovy
- •Implementing multiple inheritance in Groovy
- •Defining type-checking rules for dynamic code
- •Adding automatic logging to Groovy classes
- •Introduction
- •Reading from a file
- •Reading a text file line by line
- •Processing every word in a text file
- •Writing to a file
- •Replacing tabs with spaces in a text file
- •Deleting a file or directory
- •Walking through a directory recursively
- •Searching for files
- •Changing file attributes on Windows
- •Reading data from a ZIP file
- •Reading an Excel file
- •Extracting data from a PDF
- •Introduction
- •Reading XML using XmlSlurper
- •Reading XML using XmlParser
- •Reading XML content with namespaces
- •Searching in XML with GPath
- •Searching in XML with XPath
- •Constructing XML content
- •Modifying XML content
- •Sorting XML nodes
- •Serializing Groovy Beans to XML
- •Introduction
- •Parsing JSON messages with JsonSlurper
- •Constructing JSON messages with JsonBuilder
- •Modifying JSON messages
- •Validating JSON messages
- •Converting JSON message to XML
- •Converting JSON message to Groovy Bean
- •Using JSON to configure your scripts
- •Introduction
- •Creating a database table
- •Connecting to an SQL database
- •Modifying data in an SQL database
- •Calling a stored procedure
- •Reading BLOB/CLOB from a database
- •Building a simple ORM framework
- •Using Groovy to access Redis
- •Using Groovy to access MongoDB
- •Using Groovy to access Apache Cassandra
- •Introduction
- •Downloading content from the Internet
- •Executing an HTTP GET request
- •Executing an HTTP POST request
- •Constructing and modifying complex URLs
- •Issuing a REST request and parsing a response
- •Issuing a SOAP request and parsing a response
- •Consuming RSS and Atom feeds
- •Using basic authentication for web service security
- •Using OAuth for web service security
- •Introduction
- •Querying methods and properties
- •Dynamically extending classes with new methods
- •Overriding methods dynamically
- •Adding performance logging to methods
- •Adding transparent imports to a script
- •DSL for executing commands over SSH
- •DSL for generating reports from logfiles
- •Introduction
- •Processing collections concurrently
- •Downloading files concurrently
- •Splitting a large task into smaller parallel jobs
- •Running tasks in parallel and asynchronously
- •Using actors to build message-based concurrency
- •Using STM to atomically update fields
- •Using dataflow variables for lazy evaluation
- •Index
Chapter 10
The divide and conquer algorithm is approximately 25 percent to 50 percent faster than the same single threaded algorithm. It is necessary to fiddle around with the maximum number of threads and the optimal threshold (the size of each chunk) to achieve the best throughput. Results may vary depending on the hardware and the size of the token list.
This recipe should serve as a basis for better understanding when this algorithm can be put into practice.
See also
ff http://en.wikipedia.org/wiki/Divide_and_conquer_algorithm ff http://gpars.codehaus.org/ForkJoin
ff http://gpars.org/guide/guide/dataParallelism. html#dataParallelism_fork-join
ff https://code.google.com/p/guava-libraries/
Running tasks in parallel and asynchronously
One of the recurring problems that a developer has to face when working on integrating with external systems, is how to deal with sluggish response time.
Very often, a slow response time from a system, out of our control, ends up negatively affecting the user experience of a web application that feeds on the data coming from the slow system.
The first line of defense against such services is adding a caching layer. A cache helps to mitigate the effects of unreliable external systems, but it is not always the definitive cure.
Depending on the business domain, a cache may have a large ratio of cache miss (occurs when a specific data is not found in the cache). Furthermore, on large systems caches can take time to warm up.
So, the second weapon in a developer arsenal against sleepy services, is using asynchronous calls. An asynchronous call is a non-blocking call to a method. A separate thread runs the method and returns the result whenever it is ready. In the meanwhile, the caller of the method
receives a future (see http://en.wikipedia.org/wiki/Futures_and_promises), from which it will be able to retrieve the results. A future is an object that is returned immediately after calling an asynchronous method to escape blocking. Once the caller gets hold of a future, it can continue executing other code until the results from the original call are available.
349
www.it-ebooks.info
Concurrent Programming in Groovy
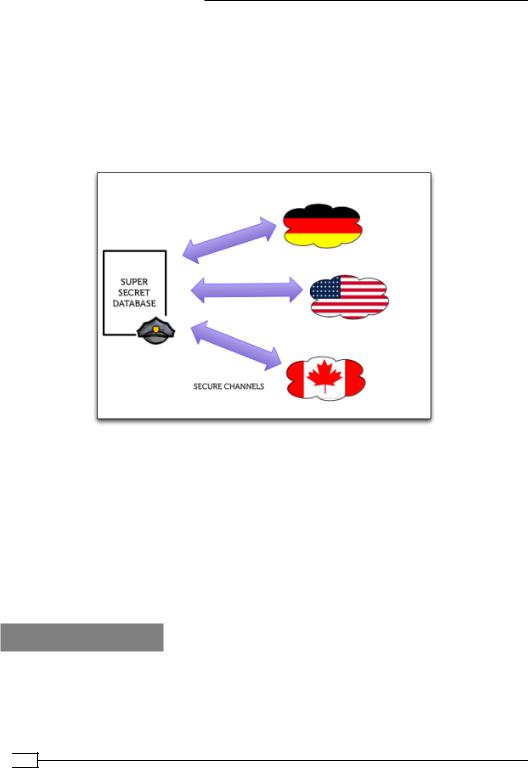
For this recipe, let's imagine that we are building a super-secret international criminal database. Our system is able to fetch the criminal records of citizens of any country. In order to do so, it must be able to interface with the criminal database of each and every country it needs data from.
The system is used by the cops to track international criminals who are active in more than one nation.
From a design point of view, our system would look as follows:
Fancy! Each country exposes a REST based interface to access the criminal records. Unfortunately, some countries such as the United States, have a very large amount of criminal data and each request takes up to 10 seconds to complete. Some other countries didn't invest much in the system, and they deployed their service on very slow and old hardware, causing the response times to be erratic and inconstant.
One fundamental functionality of this system is being able to collect data from multiple countries and present the user with a unified view of the data coming from each nation.
Implementing an asynchronous call pattern allows for retrieving and showing data as soon as they are ready, without blocking and waiting for the slowest invocation to return.
Getting ready
Before we begin to write the asynchronous call framework, we need to create three RESTbased web services to simulate a latency in the response. A quick way to create the REST service in Groovy (or Java) is to use the Ratpack framework. Ratpack is a mini framework inspired by Ruby's Sinatra. It will allow us to quickly start a web service with three endpoints. Each endpoint will reply with a random response time.
 350
350
www.it-ebooks.info

Chapter 10
Create a new folder named ratpack and add two Groovy scripts to it. The app.groovy file will contain the minimal Ratpack application:
@GrabResolver(
name = 'Sonatype OSS Snapshots', root =
'https://oss.sonatype.org/content/repositories/snapshots', m2Compatible = true
)
@Grab('org.ratpack-framework:ratpack-groovy:0.7.0-SNAPSHOT') import static org.ratpackframework.groovy.Ratpack.ratpack ratpack {
}
And the ratpack.groovy file will contain configuration for different endpoints we are going to serve:
get('/') {
text 'Welcome to the world criminal database'
}
get('/us') { Thread.sleep(rnd(10000L)) render 'us.json'
}
get('/canada') { Thread.sleep(rnd(5000L)) render 'can.json'
}
get('/germany') { Thread.sleep(rnd(7000L)) render 'de.json'
}
static rnd(long maxMilliseconds) { def rnd = new Random().nextInt()
Math.abs(rnd % maxMilliseconds + 1000)
}
351
www.it-ebooks.info
Concurrent Programming in Groovy
To complete the setup, create an additional folder named templates and add three files to it:
ff Data for Germany in de.json:
{
"country": "germany"
}
ff Data for Canada in can.json:
{
"country": "canada"
}
ff And data for United States in us.json:
{
"country": "united states"
}
Not very exciting JSON content, but we just need to simulate some request/response here.
Open a command prompt and launch the web service, typing groovy app.groovy. The Groovy process should reply with:
> groovy app.groovy
May 02, 2013 9:15:04 PM o.r.b.i.NettyRatpackServer startUp INFO: Ratpack started for http://0:0:0:0:0:0:0:0:5050
In order to test the service, open a browser and navigate to http://localhost:5050/de. The content of the de.json file should appear on the page after some delay forced by the sleep function.
How to do it...
Now that our testing infrastructure is in place, we can write the code to invoke the three web services asynchronously.
1.In a new file, let's create a class named CriminalDataService:
@Grab( group='org.codehaus.groovy.modules.http-builder', module='http-builder',
version='0.6'
)
import static groovyx.net.http.Method.* import static groovyx.net.http.ContentType.* import groovyx.net.http.HTTPBuilder
 352
352
www.it-ebooks.info

Chapter 10
import groovyx.gpars.GParsPool
class CriminalDataService {
// Database logic.
...
}
// Client code.
...
2.Add one function and one closure to the class:
List getData(List countries) { def response = [] GParsPool.withPool {
countries.each { country ->
response << this.&fetchData.callAsync(country)
}
}
response
}
def fetchData(String country) {
def http = new HTTPBuilder('http://localhost:5050') def jsonData
def start = System.currentTimeMillis() http.request( GET, JSON ) {
uri.path = "/${country}" response.success = { resp, json ->
jsonData = json
}
}
def timeSpent = System.currentTimeMillis() - start jsonData.put('fetch-time', timeSpent)
jsonData
}
3.Finally, following is the "client" code, calling the class:
CriminalDataService cda = new CriminalDataService()
def data = cda.getData(['germany', 'us', 'canada']) assert 3 == data.size()
353
www.it-ebooks.info
Concurrent Programming in Groovy
data.each {
println "data received: ${it.get()}"
}
def timeSpent = System.currentTimeMillis() - start println "Total execution time: ${timeSpent}ms"
4.The script should show an output similar to the following:
data received: [fetch-time:1750, country:germany]
data received: [fetch-time:8775, country:united states] data received: [fetch-time:1562, country:canada]
Total execution time: 8878ms
How it works...
The getData method displayed in step 2, accepts a List containing the country monikers we want to query for criminal records. For each element in the list, we execute a call to the fetchData closure. However, the call is not a standard one. You may have noticed that the method name (fetchData) is followed by callAsync. The callAsync method is automatically added to the closure by the GPars.withPool block. It calls the closure in
a separate thread, immediately returning a java.util.concurrent.Future, which will be populated with the "real" result when the routine completes.
The fetchData method uses the HTTPBuilder to execute a REST request against the Ratpack REST endpoint. The entire recipe Issuing a REST request and parsing a response in Chapter 8, Working with Web Services in Groovy is dedicated to the REST operations.
The client code demonstrated in step 3, loops on the returned array. Each element of the array is a Future, to extract the actual result, the client calls the get method on the Future. Note that the get method blocks until the Future returns the result or an exception.
See also
ff http://gpars.codehaus.org/
ff https://github.com/ratpack/ratpack
ff http://docs.oracle.com/javase/7/docs/api/java/util/concurrent/ Future.html
 354
354
www.it-ebooks.info