

Интернет технологии / 2014_inet_lec_3
.pdf21
Курс «Интернет-технологии». Лекция 3 — Поиск информации…

Основные термины веб-поиска
1.Индексация — процесс составления или приписывания указателя (индекса) — служебной структуры данных, необходимой для последующего поиска.
2.Индекс цитирования — число упоминаний (цитирований) информации, в традиционной библиографической науке рассчитывается за промежуток времени, например, за год.
3.Иллюзия свежести — эффект кажущейся свежести, достигаемый поисковыми системами в интернете за счет более регулярного обхода тех документов, которые чаще находятся пользователями.
4.Кластеризация документов — одна из задач информационного поиска, целью которой является автоматическое выявление групп семантически похожих документов среди заданного фиксированного множества документов.
5.Клоакинг — техника поискового спама, состоящая в распознании робота поисковой системы и генерации для него специального содержания, принципиально отличающегося от содержания, выдаваемого пользователю.
22
Курс «Интернет-технологии». Лекция 3 — Поиск информации…

Основные термины веб-поиска
6.Поиск по смыслу — алгоритм информационного поиска, способный находить документы, не содержащие слов запроса.
7.Прямой поиск — поиск непосредственно по тексту документов, без предварительной обработки (без индексирования).
8.Ранжирование — это процесс выстраивания найденных по запросу пользователя страниц в порядке наибольшего соответствия искомому запросу.
9.Релевантность — соответствие документа запросу.
10.Регулярное выражение — способ записи поискового предписания, позволяющий определять пожелания к искомому слову, его возможные написания, ошибки и так далее. В широком смысле — язык, позволяющий
задавать запросы неограниченной сложности.
23
Курс «Интернет-технологии». Лекция 3 — Поиск информации…

Феномен Интернета
В Интернете информации куда больше, чем можно найти с помощью традиционных информационно-поисковых систем. Кроме видимой для поисковых систем части веб-пространства, существует огромное количество веб-страниц, которые ими не охватываются.
Как правило, эти веб-страницы доступны в Сети, однако выйти на них трудно, а порой невозможно, если не знать точного адреса.
Эти ресурсы — «скрытый» (deep) Web, (определение ввел Джилл Эллсворт
в 1994 году, обозначив им источники, недоступные для обычных поисковых систем). Сегодня такие ресурсы называют также «невидимым» (invisible) Web.
Доступные сегодня посредством традиционных информационно-поисковых систем веб-страницы — это лишь видимая крупица. Непознанных, скрытых
24
ресурсов Сети в сотни (!) раз больше.
Курс «Интернет-технологии». Лекция 3 — Поиск информации…

Открытый Web:
> 20 млрд документов; > 100 млн сайтов.
Рост:
~ 10 млн документов в месяц; ~ 1 млн сайтов в месяц.
Скрытый Web:
20-50 млрд документов.
А как может выглядеть структура веб-пространства?
25
Курс «Интернет-технологии». Лекция 3 — Поиск информации…
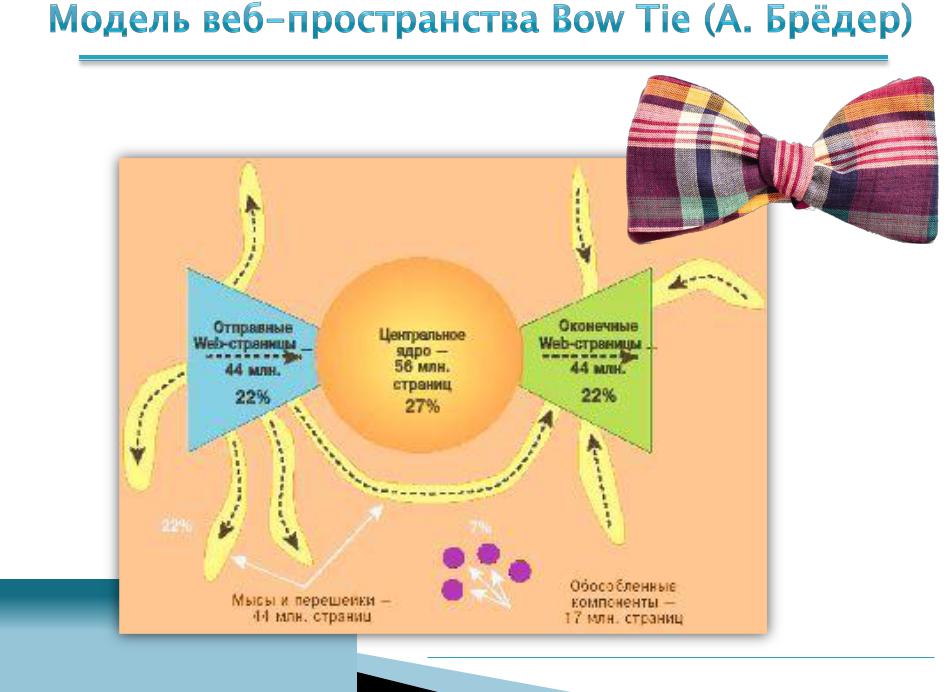
Институт поиска и анализа текстов (США) на базе исследования 200 млн страниц, 1999 год.
27% Ядро
22% IN
22% OUT
22% «отростки»
7 % «острова»
26
Курс «Интернет-технологии». Лекция 3 — Поиск информации…
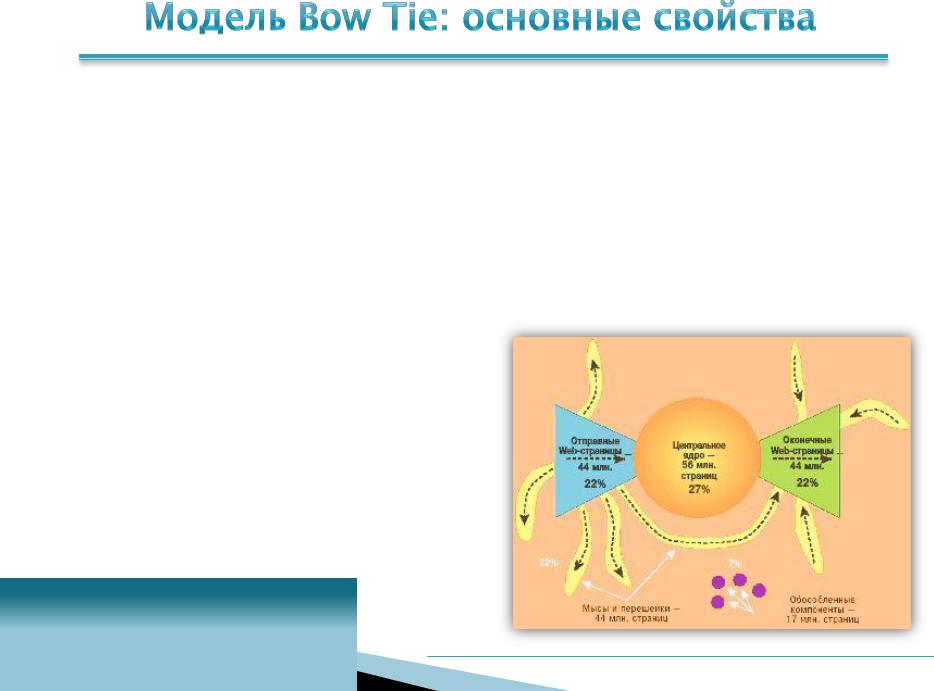
1.Пропорции основных категорий веб-страниц в течение времени остаются неизменными, несмотря на значительное увеличение общего объема веб-ресурсов.
2.Модель Bow Tie примерно одинакова для различных подмножеств веб-пространства, т. е. обладает фрактальными свойствами.
3.С большой вероятностью случайно выбранные веб-страницы окажутся никак не связанными.
27
Курс «Интернет-технологии». Лекция 3 — Поиск информации…

1.Среднее расстояние между страницами
с односторонними связями – 16 переходов по ссылкам.
2.Среднее расстояние между страницами с двусторонними
связями – 7-8 переходов по ссылкам.
3.Никакие поисковые машины не могут найти «острова», если на них не ведут гиперссылки.
Недостаток модели: недооценка количества «островов».
По оценке компании BrightPlanet в 2000 году
число скрытых ресурсов в интернете было в сотни раз больше, чем доступных через поисковые системы!
28
Курс «Интернет-технологии». Лекция 3 — Поиск информации…

Состав скрытого Web:
1.Динамически генерируемые страницы.
2.Информация из баз данных.
3.Файлы нераспознаваемых форматов.
4.Сайты, защищенные паролем.
5.Прочее…
Крупнейший каталог скрытых ресурсов: www.completeplanet.com
Содержит более 100 тыс. ссылок
Другие известные каталоги: www.bighub.com www.invisible-web.net
Сайты, защищенные паролем и берущие плату за доступ, по некоторым оценкам, составляют всего 10% скрытого Web.
Пример: Система БД Dialog : www.dialog.com
Содержит 900 баз данных, 700 тыс. пользователей, которые просматривают более 17 млн документов в час!
Услугами Dialog пользуются в более чем 100 странах
29
Курс «Интернет-технологии». Лекция 3 — Поиск информации…
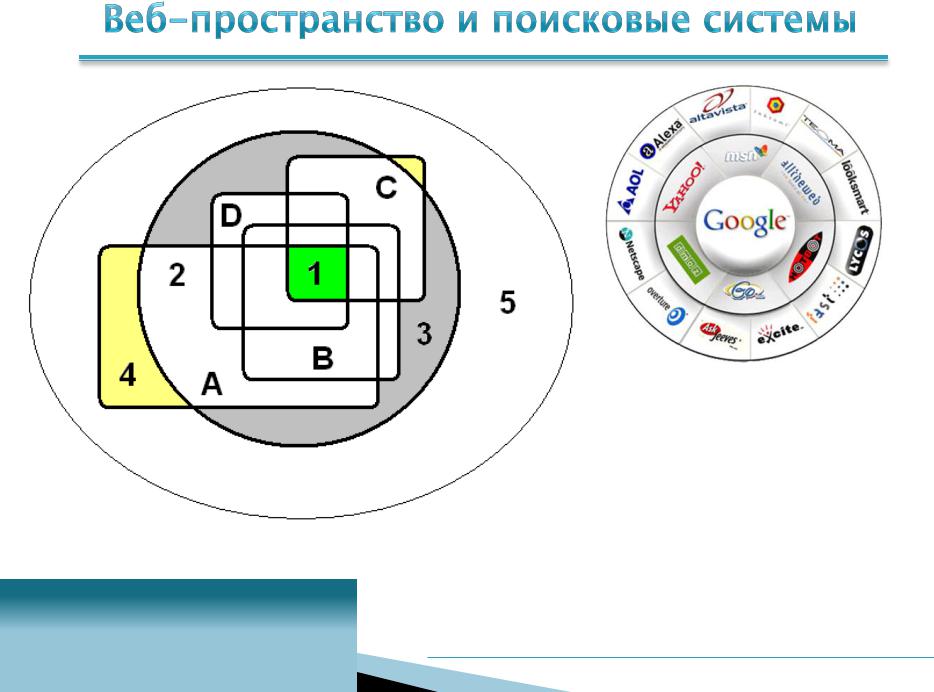
|
1 |
– часть ядра, |
|
охватываемая всеми |
|
|
поисковыми системами |
|
|
2 – видимое ядро |
|
|
3 |
– невидимое ядро |
A, B, C, D – области, охватываемые |
4 |
– доступный системе А |
поисковыми системами (10-30%) |
скрытый Web |
|
|
5 |
– полностью скрытый Web |
30
Курс «Интернет-технологии». Лекция 3 — Поиск информации…