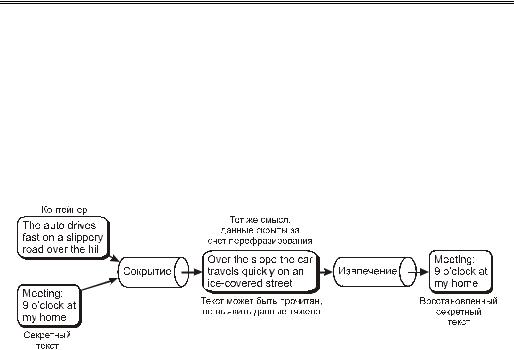
Методы и средства защиты информации
.pdfКлассификацияметодов сокрытияинформации 471
Рис. 20.2. Классификация методов сокрытия информации
По способу отбора контейнера, как уже указывалось, различают методы
суррогатной стеганографии, селективной стеганографии и конструирующей стеганографии.
Вметодах суррогатной ( безальтернативной) стеганографии отсутствует возможность выбора контейнера и для сокрытия сообщения выбирается первый попавшийся контейнер, зачастую не совсем подходящий к встраиваемому сообщению. В этом случае, биты контейнера заменяются битами скрываемого сообщения таким образом, чтобы это изменение не было заметным. Основным недостатком метода является то, он позволяет скрывать лишь незначительное количество данных.
Вметодах селективной стеганографии предполагается, что спрятанное сообщение должно воспроизводить специальные статистические характеристики шума контейнера. Для этого генерируют большое число альтернативных контейнеров, чтобы затем выбрать наиболее подходящий из них для конкретного сообщения. Частным случаем такого подхода является вычисление некоторой хеш-функция для каждого контейнера. При этом для сокрытия сообщения выбирается тот контейнер, хеш-функции которого совпадает со значением хешфункции сообщения (т.е. стеганограммой является выбранный контейнер).
Вметодах конструирующей стеганографии контейнер генерируется самой стегосистемой. Здесь может быть несколько вариантов реализации. Так, например, шум контейнера может моделироваться скрываемым сообщением. Это

472 Глава 20. Стеганография
реализуется с помощью процедур, которые не только кодируют скрываемое сообщение под шум, но и сохраняют модель первоначального шума. В предельном случае по модели шума может строиться целое сообщение. Примерами могут служить метод, который реализован в программе MandelSteg, где в качестве контейнера для встраивания сообщения генерируется фрактал Мандельброта,
или же аппарат функций имитации (mumic function).
По способу доступа к скрываемой информации различают методы для по- токовых ( непрерывных) контейнеров и методы для контейнеров с произволь- ным доступом (ограниченной длины).
Методы, использующие потоковые контейнеры, работают с потоками не-
прерывных данных (например, интернет-телефония). В этом случае скрываемые биты необходимо в режиме реального времени включать в информационный поток. О потоковом контейнере нельзя предварительно сказать, когда он начнется, когда закончится и насколько продолжительным он будет. Более того, объективно нет возможности узнать заранее, какими будут последующие шумовые биты. Существует целый ряд трудностей, которые необходимо преодолеть корреспондентам при использовании потоковых контейнеров. Наибольшую проблему при этом составляет синхронизация начала скрытого сообщения.
Методы, которые используются для контейнеров с произвольным досту-
пом, предназначены для работы с файлами фиксированной длины ( текстовая информация, программы, графические или звуковые файлы). В этом случае заранее известны размеры файла и его содержимое. Скрываемые биты могут быть равномерно выбраны с помощью подходящей псевдослучайной функции. Недостаток таких контейнеров состоит в том, они обладают намного меньшими размерами, чем потоковые, а также то, что расстояниямежду скрываемымибитами равномерно распределенымежду наиболее коротким и наиболее длинным заданными расстояниями, в то время как истинный шум будет иметь экспоненциальное распределениедлин интервала. Преимуществоподобных контейнеровсостоит в том, то они могут быть заранее оценены с точки зрения эффективности выбранногостеганографическогопреобразования.
По типу организации контейнеры, подобно помехозащищенным кодам, мо-
гут быть систематическими и несистематическими. В систематически орга-
низованных контейнерах можно указать конкретные места стеганограммы, где находятся информационные биты самого контейнера, а где — шумовые биты, предназначенные для скрываемой информации ( как, например, в широко распространенном методе наименьшего значащего бита). При несистематической организации контейнера такого разделения сделать нельзя. В этом случае для выделения скрытой информации необходимо обрабатывать содержимое всей стеганограммы.
По используемым принципам стеганометоды можно разбить на два класса:
цифровые методы и структурные методы. Если цифровые методы стегано-

Текстовые стеганографы 473
графии, используя избыточность информационной среды, в основном, манипулируют с цифровым представлением элементов среды, куда внедряются скрываемые данные ( например, в пиксели, в различные коэффициенты косинускосинусных преобразований, преобразований Фурье, Уолша-Радемахера или Лапласа), то структурные методы стеганографии для сокрытия данных используют семантически значимые структурные элементы информационной среды.
Основным направлением компьютерной стеганографии является использование свойств избыточности информационной среды. Следует учесть, что при сокрытии информации происходит искажение некоторых статистических свойств среды или нарушение ее структуры, которые необходимо учитывать для уменьшения демаскирующих признаков.
Вособую группу можно также выделить методы, которые используют специальные свойства форматов представления файлов:
∙зарезервированные для расширения поля компьютерных форматов файлов, которые обычно заполняются нулями и не учитываются программой;
∙специальное форматирование данных ( смещение слов, предложений, абзацев или выбор определенных позиций букв);
∙использование незадействованных мест на магнитных носителях;
∙удаление идентифицирующих заголовков для файла.
Восновном, для таких методов характерны низкая степень скрытности, низкая пропускная способность и слабая производительность.
По предназначению различают стеганографические методы собственно для скрытой передачи или скрытого хранения данных и методы для сокрытия данных в цифровых объектах с целью защиты самих цифровых объектов.
По типу информационной среды выделяются стеганографические методы для текстовой среды, для аудио среды, а также для изображений (стоп-кадров) и видео среды.
Ниже более подробно будут описаны известные стеганографические методы для разных типов информационной среды.
Текстовые стеганографы
Современные стеганографические средства обычно работают в информационных средах, имеющих большую избыточность. В отличие от информации, которая содержит много шумовых данных ( например, звук и изображение), письменный текст содержит малое количество избыточной информации, которую можно использовать для сокрытия данных.
Методы лингвистической стеганографии — сокрытия секретных сообщений в тексте — известны еще со средневековья. В основном такие методы используют либо естественную избыточность языка, либо форматы представления


Текстовые стеганографы 475
скрытые таким образом данные не всегда могут быть восстановлены с печатной копии документа.
М |
ы |
|
р |
е |
д |
к |
о |
|
д |
о |
|
к |
о |
н |
ц |
а |
|
п |
о - |
|
|
|
н |
и |
м |
а |
е |
м |
, |
|
ч |
т |
о |
|
м |
ы |
|
д |
е |
й |
с |
т - |
|
|
|
в |
и |
т |
е |
л |
ь |
н |
о |
|
х |
о |
т |
и |
м |
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
М |
ы |
|
р |
е |
д |
к |
о |
|
д |
о |
|
к |
о |
н |
ц |
а |
|
п |
о - |
|
|
|
н |
и |
м |
а |
е |
м |
, |
|
ч |
т |
о |
|
м |
ы |
|
д |
е |
й |
с |
т - |
|
|
|
в |
и |
т |
е |
л |
ь |
н |
о |
|
х |
о |
т |
и |
м |
. |
|
|
|
|
|
|
|
|
Рис. 20.3. Пример сокрытия данных пробелами в конце текстовых строк
Еще один метод сокрытия данных с помощью пробелов манипулирует с текстами, которые выровнены с обеих сторон. В этом методе данные кодируются путем управляемого выбора мест для размещения дополнительных символов пробела. Один символ между словами интерпретируется как 0, а два — как 1. Метод позволяет встраивать несколько бит скрытой информации в каждую строку текста (рис. 20.4).
Рис. 20.4. Пример сокрытия битового сообщения 0110≡100011010110
Поскольку текст часто выравнивается по ширине листа, не каждый промежуток между словами может использоваться для кодирования скрытых данных. Для того чтобы определить, в каком из промежутков между словами спрятана информация, а какие промежутки являются частью оригинального текста, используется следующий метод декодирования. Битовая строка, которая извлекается из стеганограммы, разбивается на пары. Пара бит 01 интерпретируется как 1; пара 10 — как 0; а биты 00 и 11 являются пустыми, т.е. такими, которые не несут никакой информации. Например, битовое сообщение 1000101101 сокращается до 001, а строка 110011 — будет пустой.
Рассмотренные методы работают успешно до тех пор, пока тексты представлены в коде ASCII. Существуют также стеганографические методы, которые интерпретируют текст как двоичное изображение. В данных методах скрываемая информация кодируется изменением расстояния между последовательными строками текста или словами. Сокрытие данных происходит путем выбора местоположения строк в документе, которые сдвигаются вверх или вниз в соответствии с битами скрываемых данных. При этом некоторые строки оставляют для синхронизации на месте ( например, каждую вторую). В этом случае один сек-

476 Глава 20. Стеганография
ретный бит сообщения кодируется сдвигом одной строки. Если строка сдвинута, то значение секретного бита равно 1, иначе — 0.
Извлечение скрытого сообщения проводится путем анализа расстояний между центрами строк, которые расположены рядом. Обозначим через R+ — расстояние между центрами сдвинутой строки и предыдущей неизмененной строки (синхрострока), R– — расстояние между центрами сдвинутой линии и последующей синхростроки, а через Х+ и Х– — соответствующие расстояния в исходном документе. Тогда, если расстояние между строками было увеличено, то
R+ + |
R– > |
X+ + |
X– |
R+ – |
R– |
X+ – |
X– |
Аналогично, если расстояние было уменьшено, то
R+ + |
R– < |
X+ + |
X– |
R+ – |
R– |
X+ – |
X– |
Отметим, что данный метод нечувствителен к изменению масштаба документа, что обеспечивает ему хорошую устойчивость к большинству искажений, которые могут иметь место при активных атаках.
Другая возможная схема сокрытия путем сдвига слов отформатированного текста показана на рис. 20.5. В соответствии с этой схемой изменяется горизонтальная позиция начала слов. Теоретически, можно использовать изменение каждого промежутка между словами. Для того чтобы обеспечить сохранение первоначального выравниваниятекста, необходимо соблюдать единственноеограничение: сумма всех сдвигов в одной строке должна равнятьсянулю.
Рис. 20.5. Пример сокрытия данных в промежутках между словами (для наглядности указаны вертикальные линии)
Существуют более тонкие методы сокрытия информации в текстовой среде. В некоторых текстовых редакторах реализованы опции, которые проводят автоматическое форматирование текста в соответствии с определенными критериями. Например, редактор ТЕХ использует сложный алгоритм вычисления конца строки или страницы. Фактически вычисляются некоторые специальные параметры, по которым определяется место перехода с одной строки или страницы на другую. Один из таких параметров оценивает количество пробелов, которые необходимо вставить, чтобы сохранить заданный стиль документа; другой — оценивает эстетический вид документа при выборе переноса и т.д. В результате


Текстовые стеганографы 479
Таким образом, если p(t, A) — вероятность появления некоторой строки t в файле А, то функция f преобразует файл А в файл В так, что для всех строк t длиной меньше n выполняется соотношение |p(t, f(A)) –p(t, B)| < ε.
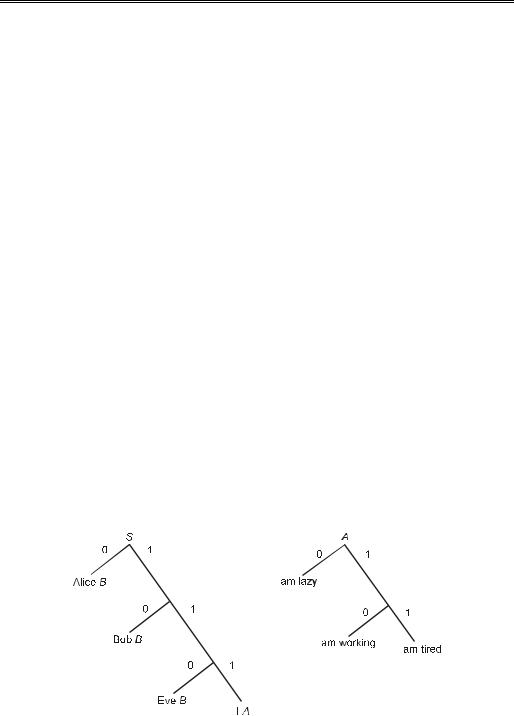
Можно предложить несколько типов функции имитации, которые, в зависимости от сложности, моделируются регулярной, контекстно-свободной или рекур- сивно-счетной грамматиками. Стеганографические преобразования первого типа описываются в терминах процедур сжатия информации; второго — контекстносвободными грамматиками, в которых скрываемые биты управляют непротиворечивыми продукциями; для описания функций третьего типа применяется аппарат машин Тьюринга.
Регулярные функции имитации можно смоделировать с помощью схемы кодирования по Хаффману. Известно, что любой язык обладает некоторыми статистическими свойствами. Этот факт используется многими методами сжатия данных. Если на алфавите Σ задано распределение вероятностей A, то можно
воспользоваться схемой кодирования по Хаффману для создания функции сжатия с минимальной избыточностью fA:Σ→{0,1}*, где символ * используется в смысле Σ*=i³0{x1…xi|x1,…,xiΣ}. Такую функцию можно построить на основе функции сжатия Хаффмана: G(x)=fB-1(fA(x)).
Таким образом, секретный файл можно сжать по схеме Хаффмана с распределением A, в результате чего получится файл двоичных строк, которые могут интерпретироваться как результат операции сжатия некоторого файла с распределением B. Этот файл может быть восстановлен с применением инверсной функции сжатия fB-1 к файлу двоичных строк и использоваться в дальнейшем как стеганограмма. Если функции fA и fB-1 являются взаимно однозначными, то и созданная функция имитации будет также взаимно однозначна. Доказано, что построенная таким образом функция подобия оптимальна в том смысле, что если функция сжатия Хаффмана fA является теоретически оптимальной и файл x состоит из случайных бит, то взаимно однозначная функция fA-1(X) имеет наилучшую статистическую эквивалентность к А.
Регулярные функции имитации создают стеганограммы, которые имеют заданное статистическое распределение символов, однако при этом игнорируется семантика полученного текста. Для человека такие тексты выглядят полной бессмыслицей с грамматическими ошибками и опечатками. Для генерирования более осмысленных текстов используются контекстно-свободные грамматики
(КСГ).
Контекстно-свободная грамматика определяется упорядоченной четверткой <V, Σ V, П, S V\Σ>, где V и Σ — соответственно множества переменных и
терминальных символов, П — набор продукций (правил вывода), а S — начальный символ. Продукции подобны правилам подстановки, они преобразуют переменную в строку, состоящую из терминальных или переменных символов. Если с помощью правил вывода из стартового символа можно получить последовательность терминальных символов, то говорят, что последовательность получе-