


Тема 3. МОДЕЛІ ОБЧИСЛЕНЬ
Алан Тьюринг висловив припущення (відоме як Теза Черча - Тьюринга), що будьякий алгоритм в інтуїтивному розумінні цього слова може бути представлений еквівалентної машиною Тьюринга. Уточнення уявлення про обчислюваності на основі поняття машини Тьюринга (і інших аналогічних їй понять) відкрило можливості для суворого докази алгоритмічної нерозв'язності різних масових проблем (тобто проблем про знаходження єдиного методу рішення деякого класу задач, умови яких можуть змінюватись у відомих межах). Найпростішим прикладом алгоритмічно нерозв'язною масової проблеми є так звана проблема застосовності алгоритму (також називається проблемою зупинки). Вона полягає в наступному: потрібно знайти загальний метод, який дозволяв би для довільної машини Тьюринга (заданої за допомогою своєї програми) і довільного початкового стану стрічки цієї машини визначити, чи завершиться робота машини за кінцеве число кроків, або ж буде тривати необмежено довго.
Протягом першого десятиліття історії теорії алгоритмів нерозв'язні масові проблеми були виявлені лише всередині самої цієї теорії (сюди відноситься описана вище проблема придатності), а також всередині математичної логіки (проблема виводимості в класичному численні предикатів). Тому вважалося, що теорія алгоритмів є узбіччя математики, не має значення для таких її класичних розділів, як алгебра або аналіз. Становище змінилося після того, як А. А. Марков і Е. Л. Пост в 1947 встановили алгоритмічну нерозв'язність відомої в алгебрі проблеми рівності для конечнопорожденних і конечноопределенних напівгруп (т. зв. проблеми Туе). Згодом була встановлена алгоритмічна нерозв'язність і багатьох інших "чисто математичних" масових проблем. Одним з найбільш відомих результатів у цій галузі є доведена Ю.В.Матіясевічем алгоритмічна нерозв'язність десята проблеми Гільберта.
До моделей обчислень належать:
∙Машина Тьюринга
∙Лямбда-числення - розглядається пара - λ-вираз і його аргумент, - а
обчисленням вважається застосування, або аппліцірованіе першого члена пари до другого. Це дозволяє відокремити функцію і те, до чого вона застосовується. У більш загальному випадку обчисленням вважаються ланцюжка, що починаються з вихідного λ- вирази, за яким следут кінцева послідовність λ-виразів, кожне з яких виходить з попереднього застосуванням β-редукції, тобто правила підстановки.
∙Комбінаторна логіка - трактування обчислення схожа з λ-обчисленням, але
єі важливі відмінності (наприклад, комбінатор нерухомої точки Y має нормальну форму в
комбінаторної логіки, а в λ-численні - не має). Комбінаторна логіка була спочатку розроблена для вивчення природи парадоксів і для побудови концептуально ясних підстав математики, причому уявлення про змінну виключалося зовсім, що допомагало прояснити роль і місце змінних в математиці.
∙Реєстрові машини (англ.)
∙RAM-машина (англ.) - абстрактна обчислювальна машина, що моделює комп'ютер з довільним доступом до пам'яті. Саме ця модель обчислень найбільш часто використовується при аналізі алгоритмів.
12

Тема 4. ПОНЯТТЯ СТРУКТУР ДАНИХ
Загальна характеристика структур даних
Структури даних і алгоритми служать тими матеріалами, з яких будуються програми. Більше того, сам комп'ютер складається зі структур даних і алгоритмів. Вбудовані структури даних представлені тими регістрами і словами пам'яті, де зберігаються двійкові величини. Закладені в конструкцію апаратури алгоритми - це втілені в електронних логічних ланцюгах жорсткі правила, за якими занесені в пам'ять дані інтерпретуються як команди, що підлягають виконанню. Тому в основі роботи будь-якого комп'ютера лежить вміння оперувати тільки з одним видом даних - з окремими бітами, або двійковими цифрами. Працює ж з цими даними комп'ютер тільки відповідно до незмінного набору алгоритмів, які визначаються системою команд центрального процесора.
Завдання, які вирішуються за допомогою комп'ютера, рідко виражаються мовою бітів. Як правило, дані мають форму чисел, літер, текстів, символів і більш складних структур типу послідовностей, списків і дерев. Ще різноманітнішими є алгоритми, що застосовуються для вирішення різних завдань; фактично алгоритмів не менше ніж обчислювальних задач.
Для точного опису абстрактних структур даних і алгоритмів програм використовуються такі системи формальних позначень, що називаються мовами програмування, в яких сенс всякого речення визначається точно і однозначно. Серед засобів, що надаються майже всіма мовами програмування, є можливість посилатися на елемент даних, користуючись присвоєним йому ім'ям, або, інакше, ідентифікатором. Одні іменовані величини є константами, які зберігають постійне значення в тій частині програми, де вони визначені, інші - змінними, яким за допомогою оператора в програмі може бути присвоєно будь-яке нове значення. Але до тих пір, поки програма не почала виконуватися, їх значення не визначено.
Ім'я константи або змінної допомагає програмісту, але комп'ютеру воно ні про що не говорить. Компілятор, що транслює текст програми в двійковий код, пов'язує кожен ідентифікатор з певною адресою пам'яті. Але для того, щоб компілятор зміг це виконати, потрібно повідомити про "тип" кожної іменованої величини. Людина, яка вирішує якусь задачу "вручну", володіє інтуїтивною здатністю швидко розібратися в типах даних і тих операціях, що для кожного типу справедливі. Так, наприклад, не можна видобути квадратний корінь з слова або написати число з великої літери. Одна з причин, що дозволяють легко провести таке розпізнавання, полягає в тому, що слова, числа та інші позначення виглядають по-різному. Однак для комп'ютера всі типи даних зводяться в кінцевому рахунку до послідовності бітів, тому різницю в типах слід робити явною.
Типи даних, прийняті в мовах програмування, включають натуральні й цілі числа та дійсні числа (у вигляді наближених десяткових дробів), літери, рядки тощо.
У деяких мовах програмування тип кожної константи або змінної визначається компілятором по запису присвоюється значення; наявність десяткового дробу, наприклад, може служити ознакою дійсного числа. В інших мовах потрібно, щоб програміст явно задав тип кожної змінної, і це надає одну важливу перевагу. Хоча при виконанні програми значення змінної може багаторазово змінюватися, тип її мінятися не повинен ніколи. Це означає, що компілятор може перевірити операції, що виконуються над цією змінною, і переконатися в тому, що всі вони узгоджуються з описом типу змінної. Така перевірка може бути проведена шляхом аналізу всього тексту програми, і в цьому випадку вона охопить усі можливі дії, які визначаються даною програмою.
В залежності від призначення мови програмування захист типів, що здійснюється на етапі компіляції, може бути більш-менш жорстким. Так, наприклад, мова PASCAL, що спочатку була перш за все інструментом для ілюстрування структур даних і алгоритмів, зберігає від свого
13

первісного призначення вельми суворий захист типів. PASCAL-компілятор в більшості випадків розцінює змішання в одному виразі даних різних типів або застосування до типу даних невластивих йому операцій як фатальну помилку. Навпаки, мова C, призначена насамперед для системного програмування, є мовою з дуже слабким захистом типів. C-компілятори в таких випадках лише видають попередження. Відсутність жорсткого захисту типів дає системному програмісту, який розробляє програму на мові C, додаткові можливості, але такий програміст сам відповідає за правильність своїх дій.
Структура даних відноситься, по суті, до "просторового" поняття: її можна звести до схеми організації інформації в пам'яті комп'ютера. Алгоритм же є відповідним процедурних елементом в структурі програми - він служить рецептом розрахунку.
Перші алгоритми були придумані для вирішення чисельних задач типу множення чисел, знаходження найбільшого загального дільника, обчислення тригонометричних функцій тощо. Сьогодні в рівній мірі є важливими й нечисельні алгоритми, вони розроблені для таких завдань, як, наприклад, пошук в тексті заданого слова, планування подій, сортування даних в зазначеному порядку тощо. Нечисельні алгоритми оперують з даними, які не обов'язково є числами, більше того, не потрібні ніякі глибокі математичні поняття, щоб їх конструювати або розуміти. З цього, однак, зовсім не випливає, що у вивченні таких алгоритмів математики немає місця, навпаки, точні, математичні методи необхідні при пошуку найкращих рішень нечисельних завдань при доказі правильності цих рішень.
Структури даних, що застосовуються в алгоритмах, можуть бути надзвичайно складними. В результаті вибір правильного представлення даних часто служить ключем до вдалого програмування і може більшою мірою позначатися на продуктивності програми, ніж деталі використовуваного алгоритму. Навряд чи коли-небудь з'явиться загальна теорія вибору структур даних. Найкраще, що можна зробити, - це розібратися в усіх базових "цеглинах" і в зібраних з них структурах. Здатність докласти ці знання до конструювання великих систем - це перш за все справа інженерного майстерності та практики.
Інформація та її представлення в пам'яті комп’ютера
Починаючи вивчення структур даних або інформаційних структур, необхідно ясно встановити, що розуміється під інформацією, як інформація передається і як вона фізично розміщується в пам'яті комп’ютера.
Можна сказати, що рішення кожної задачі за допомогою комп’ютера включає запис інформації в пам'ять, вилучення інформації з пам'яті і маніпулювання інформацією. Чи можна виміряти інформацію?
У теоретико-інформаційному сенсі інформація розглядається як міра розв’язання невизначеності. Для вимірювання невизначеності системи обрана спеціальна одиниця, яка називається бітом. Біт є мірою невизначеності (або інформації), пов'язаної з наявністю лише двох можливих станів, таких, як, наприклад, істинно-хибно або так-ні. Біт використовується для вимірювання як невизначеності, так і інформації. Це цілком зрозуміло, оскільки кількість отриманої інформації дорівнює кількості невизначеності, усунутої в результаті отримання інформації.
Класифікація структур даних
Незалежно від змісту і складності будь-які дані в пам'яті комп’ютера представляються послідовністю двійкових розрядів, або бітів, а їх значеннями є відповідні двійкові числа. Дані, що розглядаються в вигляді послідовності бітів, мають дуже просту організацію або, іншими словами, слабо структуровані. Для людини описувати і досліджувати скільки-небудь складні дані в термінах послідовностей бітів дуже незручно. Більш великі й змістовні, ніж біт, "будівельні блоки" для організації довільних даних отримуються на основі поняття "структури даного".
Під СТРУКТУРОЮ ДАНИХ в загальному випадку розуміють множину елементів даних і множину зв'язків між ними. Таке визначення охоплює всі можливі підходи до структуризації
14
даних, але в кожній конкретній задачі використовуються ті чи інші його аспекти. Тому вводиться додаткова класифікація структур даних, напрямки якої відповідають різним аспектам їх розгляду.
Класифікацію за структур даних можна здійснити за кількома ознаками.
Поняття "ФІЗИЧНА структура даних" відображає спосіб фізичного представлення даних в пам'яті машини і називається ще структурою зберігання, внутрішньою структурою або структурою пам'яті.
Розгляд структури даних без урахування її представлення в пам'яті комп’ютера називається абстрактною або ЛОГІЧНОЮ структурою. У загальному випадку між логічною та відповідною їй фізичною структурами існує відмінність, ступінь якої залежить від самої структури та особливостей того середовища, в якій вона повинна бути відображена. Внаслідок цієї відмінності існують процедури, які здійснюють відображення логічної структури в фізичну і, навпаки, фізичної структури в логічну. Ці процедури забезпечують, крім того, доступ до фізичних структур і виконання над ними різних операцій, причому кожна операція розглядається стосовно до логічної чи фізичної структури даних.
Розрізняються ПРОСТІ (базові, примітивні) структури (типи) даних і ІНТЕГРОВАНІ (структуровані, композитні, складні). Простими називаються такі структури даних, які не можуть бути розбиті на складові частини, більші, ніж біти. З точки зору фізичної структури важливим є те обставина, що в даній машинної архітектурі, в даній системі програмування можна заздалегідь сказати, яким буде розмір даного простого типу і яка структура його розміщення в пам'яті. З логічної точки зору прості дані є неподільними одиницями. Інтегрованими називаються такі структури даних, складовими частинами яких є інші структури даних - прості або в свою чергу інтегровані. Інтегровані структури даних конструюються програмістом з використанням засобів інтеграції даних, що надаються мовами програмування.
В залежності від відсутності або наявності явно заданих зв'язків між елементами даних слід розрізняти НЕЗВ'ЯЗАНІ структури (вектори, масиви, рядки, стеки, черги) і ЗВ'ЯЗАНІ структури (зв'язані списки).
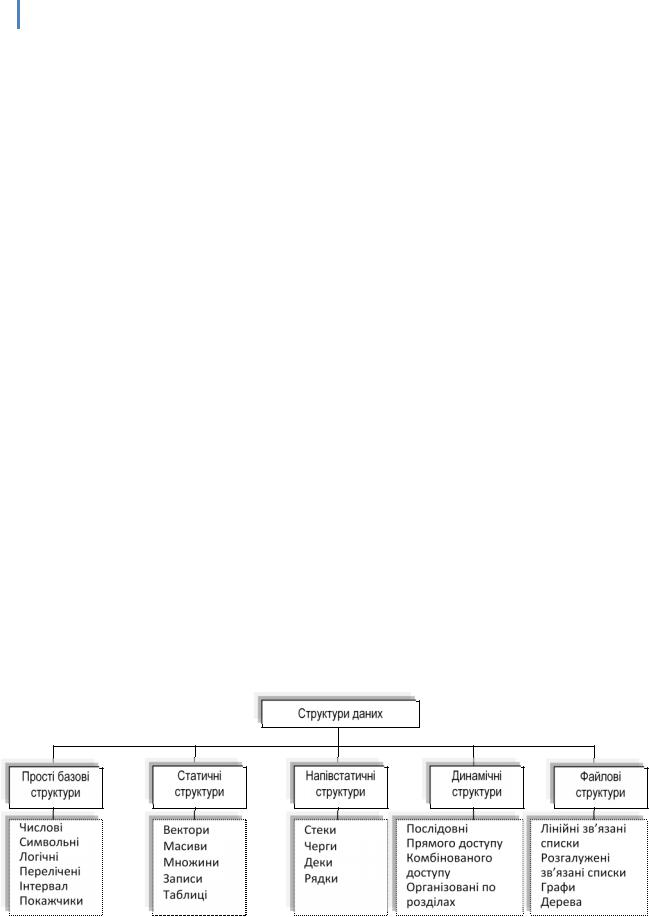
Досить важлива ознака структури даних - її мінливість - зміна числа елементів і (або) зв'язків між елементами структури. У визначенні мінливості структури не відображений факт зміни значень елементів даних, оскільки в цьому випадку всі структури даних мали б властивість мінливості. За ознакою мінливості розрізняють структури СТАТИЧНІ, НАПІВСТАТИЧНІ, ДИНАМІЧНІ. Класифікація структур даних за ознакою мінливості наведена на рис. 1.1. Файлові структури відповідають структурам даних для зовнішньої пам'яті.
Рис. 1.1. Класифікація структур даних Важлива ознака структури даних - характер впорядкованості її елементів. За цією
ознакою структури можна поділити на ЛІНІЙНІ та НЕЛІНІЙНІ структури.
15

В залежності від характеру взаємного розташування елементів в пам'яті лінійні структури можна розділити на структури з послідовним розподілом елементів в пам'яті (вектори, рядки, масиви, стеки, черги) та структури з ДОВІЛГО ЗВ'ЯЗНИМ розподілом елементів в пам'яті (однозв'язні, двозв'язні списки). Приклад нелінійних структур - багатозв'язні списки, дерева, графи.
У мовах програмування поняття "структури даних" тісно пов'язане з поняттям "типи даних". Будь-які дані, тобто константи, змінні, значення функцій чи вирази, характеризуються своїми типами.
Інформація по кожному типу однозначно визначає:
1) структуру зберігання даних зазначеного типу, тобто виділення пам'яті і представлення даних в ній, з одного боку, і інтерпретування двійкового уявлення, з іншого;
2)множину допустимих значень, які може мати той чи інший об'єкт описуваного типу;
3)множину допустимих операцій, які можуть бути застосовні до об'єкта описуваного
типу.
Операції над структурами даних
Над будь-якими структурами даних можуть виконуватися чотири спільні операції: створення, знищення, вибір (доступ), обновлення.
Операція створення полягає у виділенні пам'яті для структури даних. Пам'ять може виділятися в процесі виконання програми або на етапі компіляції. У ряді мов (наприклад, в С) для структурованих даних, що конструюються програмістом, операція створення включає в себе також установку початкових значень параметрів створюваної структури.
Наприклад, в PASCAL (I: integer), в C (int I) в результаті опису типу буде виділена пам'ять для відповідних змінних. Для структур даних, оголошених в програмі, пам'ять виділяється автоматично засобами систем програмування або на етапі компіляції, або при активізації процедурного блоку, в якому оголошуються відповідні змінні. Програміст може і сам виділяти пам'ять для структур даних, використовуючи наявні в системі програмування процедури (функції) виділення (звільнення) пам'яті. В об'єктно-орієнтованих мовах програмування при розробці нового об'єкта для нього повинні бути визначені процедури створення та знищення.
Головне полягає в тому, що незалежно від використовуваної мови програмування, наявні в програмі структури даних не з'являються "з нічого", а явно або неявно оголошуються операторами створення структур. В результаті цього всім екземплярам структур в програмі виділяється пам'ять для їх розміщення.
Операція знищення структур даних протилежна за своєю дією операції створення. У мовах C, PASCAL структури даних, наявні усередині блоку, знищуються в процесі виконання програми при виході з цього блоку. Операція знищення допомагає ефективно використовувати пам'ять.
Операція вибору використовується програмістами для доступу до даних усередині самої структури. Форма операції доступу залежить від типу структури даних, до якої здійснюється звернення. Метод доступу - один з найбільш важливих властивостей структур, особливо в зв'язку з тим, що ця властивість має безпосереднє відношення до вибору конкретної структури даних.
Операція обновлення дозволяє змінити значення даних в структурі даних. Прикладом операції оновлення є операція присвоювання, або, більш складна форма - передача параметрів.
Вищевказані чотири операції обов'язкові для всіх структур і типів даних. Крім цих загальних операцій для кожної структури даних можуть бути визначені специфічні операції, що працюють тільки з даними даного типу (даної структури).
16