


Тема 30. КЛАСИЧНІ АЛГОРИТМИ ПОШУКУ ДАНИХ ЗА ЗАДАНИМИ КРИТЕРІЯМИ
Серед пошукових алгоритмів найчастіше використовується послідовний пошук та
бінарний пошук.
В послідовному алгоритмі, як видно з назви, пошук починається з першого елементу даних і виконується послідовно, поки не буде знайдений цільовий елемент. Результатом пошуку буде номер цільового елементу в масиві, або 0, якщо елемент не знайдено. Якщо цільовий елемент знайдено, то пошук припиняється, а решта елементів масиву не аналізуються.
Як і сортування методом «бульбашки», послідовний пошук для великих об’ємів даних досить неефективний. При застосуванні послідовного пошуку інколи доводиться переглядати всі елементи масиву.
Для великих об’ємів даних бінарний пошук набагато ефективніший, ніж послідовний. Однак для виконання бінарного пошуку дані повинні бути відсортовані у визначеному порядку, в той час як послідовний пошук не потребує попереднього сортування даних.
Щоб краще зрозуміти принцип бінарного пошуку, можна пригадати гру під назвою «вгадай число». В цій грі один партнер визначає число в деякому діапазоні, наприклад від 1 до 100, а інший партнер повинен його відгадати. Намагаючись вгадати задумане число другий партнер називає деяке пробне число з діапазону. Після цього перший партнер повідомляє, чи є воно більшим або меншим ніж задумане число. Таким чином звужується діапазон пошуку, доки він не стане нульовим або число випадково буде вгаданим раніше. Фактично цей процес і є бінарним пошуком.
На кожному кроці бінарного пошуку діапазон можливих елементів розбивається навпіл, доки не досягне єдиного потрібного елементу, або не виявиться, що такого елементу немає.
Програмний код бінарного пошуку в масиві data, який містить N елементів, відсортованих за зростанням, має наступний вигляд:
target:=<цільове значення>; first:=1;
last:=N;
found:=false;
while (first<=last) and not(found) do begin
middle:=(first+last) div 2;
if target<data[middle] then last:=middle-1 if target>data[middle] then first:=middle+1 if target<data[middle] then found:=true; end;
if found then <цільовий елемент знайдений в позиції з індексом middle> else <цільовий елемент не знайдений>
end;
Пошукові алгоритми не обмежуються лише знаходженням одного цільового елементу. В реальних умовах критерії пошуку значно різноманітніші.
Елементів, які дорівнюють цільовому, може бути більше, ніж один. В цьому разі метою пошуку є індекси всіх елементів, які співпадають з цільовим.
У випадку, коли елементи масиву представляють собою структури даних (наприклад, дані типу «запис»), а пошук цільового елементу здійснюється в одному з полів цієї структури, то його метою можуть виявитися не індекси елементів, які містять цільовий елемент, а значення
108

інших полів елементів з цими індексами. В такому разі процес пошуку називається фільтрацією даних за заданим критерієм.
Наприклад, у реєстрі студентів коледжу, який містить їх прізвища, дати народження, адреси та найменування груп, в котрих вони навчаються, можна здійснити пошук даних про студентів заданої групи. В даному випадку метою пошуку є не порядкові номери записів, які відповідають заданому критерію, а дані інших полів цих записів. Такі задачі частіше зустрічаються на практиці, ніж просто пошук місцезнаходження даних в однорідних масивах. Фрагмент реалізації пошукового алгоритму може мати такий вигляд:
program FindStyd; type
Trst = record namestyd: string[30]; datnarod: string[10]; adresa: string[50]; grypa: string[5]; end;
var rst: array[1..1000] of Trst; krst: integer;
grp: string[5]; i: integer;
begin
<Введення даних реєстру студентів> write(‘Vvestu nazvy grypu ’);
readln(grp);
for i:=1 to krst do
if rst[i].grypa=grp then
writln(rst[i]. namestyd:30,’ ‘,rst[i].datnarod:10,’ ‘,rst[i]. adresa);
end.
Метою пошуку можуть бути всі елементи однорідного масиву даних, значення яких знаходиться в деякому заданому діапазоні або перевищують (не перевищують) значення цільового елементу. Очевидно, що й в цьому разі результатом пошуку буде не місцезнаходження таких даних, а їх значення. Наприклад, дата початку опалювального сезону визначається на підставі даних про середньодобову температуру повітря. Якщо вона не перевищує певного значення, сезон розпочинається.
Критерії пошуку можуть бути більш складними. Наприклад, в реєстрі студентів коледжу може здійснюватися пошук даних про студентів заданої групи, яким вже виповнилося 18 років на задану дату. Пошукові алгоритми в таких задачах значно ускладнюються, а в їх основі лежать послідовні методи пошуку.
Процеси сортування та пошуку є предметом аналізу спеціальних комп’ютерних дисциплін. Цій темі присвячено багато досить товстих книжок, в більшості яких приділяється увага швидкодії алгоритмів.
109

Тема 31. КЛАСИФІКАЦІЯ КРИТЕРІЇВ ПОШУКУ ДАНИХ У МАСИВАХ
Критеріями пошуку даних у числових масивах є:
1.екстремальні значення (мінімальне та максимальне);
2.ключове значення (key);
3.граничне значення (gran);
4.діапазон значень (d1, d2)
Значення критеріїв 2-4 визначаються користувачем.
Для критерія 3 крім самого граничного значення користувач повинен визначити:
∙чи включається саме значення до результату пошуку;
∙лівою чи правою границею є це значення.
Діапазон значень критерію 4 може бути не тільки інтервалом, а й напівінтервалом, або відрізком. Крім того користувач повинен визначити де саме шукаються дані: в діапазоні або, навпаки, за його межами.
Предметом пошуку можуть бути не тільки самі значення, а й їх індекси в масивах. Далі наведені програмна реалізація деяких алгоритмів пошуку мовою Pascal.
program Yrok14;
//Пошук даних в одновимірних масивах {$APPTYPE CONSOLE}
uses SysUtils,
UnitYrok14 in 'UnitYrok14.pas';
var AA, BB, IKey, IGran, IMax, IMin: TMas; action, typegran, incl: char; i,n,x,y,m1,m2,min,max: integer;
gincl, gleft, gright: boolean; begin
writeln('Find in array'); writeln('============='); repeat
write('Enter Number of Elements from Array (<=100) '); readln(n); writeln('Array: ');
randomize; for i:=1 to n do
begin AA[i]:=random(100); write(AA[i]:4);
end;
writeln;
writeln('1.FindKey'); writeln('2.Extrem '); writeln('3.FindGran'); writeln('4.FindDiap'); writeln('5.Exit');
write('Enrer Number Action '); readln(action); case action of
'1': begin
110
writeln('FindKey'); write('key='); readln(x); FindKey(n, AA, x, m1, IKey);
writeln('Indexes of KeyElements: '); for i:=1 to m1 do write(IKey[i]); writeln;
end; '2': begin
writeln(' Extrem ');
Extrem(n, AA, min, max, m1, m2, IMin, IMax); writeln('min=',min,' max=',max); writeln('Indexes of MinElements: ');
for i:=1 to m1 do write(IMin[i]:4); writeln;
writeln('Indexes of MaxElements: '); for i:=1 to m2 do write(IMax[i]:4); writeln;
end; '3': begin
writeln(' FindGran '); write('gran='); readln(x);
write('l-left, r-right: '); readln(typegran); write('GranInclude? (y/n) '); readln(incl);
if incl='y' then gincl:=true else gincl:=false; FindGran(n, AA, x, typegran, gincl, m1, BB,IGran); writeln('Array of FindElements: ');
for i:=1 to m1 do write(BB[i]:4); writeln;
writeln('Indexes of FindElements: '); for i:=1 to m1 do write(IGran[i]:4); writeln;
end; '4': begin
writeln(' FindDiap ');
write('d1='); readln(x); write('d2='); readln(y);
write('Find in interval? (y/n) : '); |
readln(incl); |
if incl='y' then gincl:=true else gincl:=false; |
|
write('LeftGranInclude? (y/n) '); |
readln(incl); |
if incl='y' then gleft:=true else gleft:=false; |
|
write('RightGranInclude? (y/n) '); |
readln(incl); |
if incl='y' then gright:=true else gright:=false; FindDiap(n, AA, x, y, gincl, gleft, gright, m1, BB, IGran); writeln('Array of FindElements: ');
for i:=1 to m1 do write(BB[i]:4); writeln;
writeln('Indexes of FindElements: '); for i:=1 to m1 do write(IGran[i]:4);
111

writeln;
end; '5': exit; end;
until action='5'; readln;
end
unit UnitYrok14;
//Пеалізація алноритмів пошуку даних в одновимірних масивах interface
type TMas=array[1..100] of integer;
function Compare(x,y: integer; cond: integer): boolean;
procedure FindKey(n: integer; A: TMas; key: integer; var k: integer; var Indexes: TMas); procedure Extrem(n: integer; A: TMas; var min, max, k1, k2: integer; var IndMin, IndMax:
TMas);
procedure FindGran(n: integer; A: TMas; gran: integer; napr: char; include: boolean; var k: integer; var B,Indexes: TMas);
procedure FindDiap(n: integer; A: TMas; d1,d2: integer;
include, include1,include2: boolean; var k: integer; var B,Indexes: TMas); implementation
//Результат порівняння двох зміниих
function Compare(x,y: integer; cond: integer): boolean; //x - значення, що порівнюється
//y - ліва та права границі діапазону
//cond - умова порівняння: 0-'=',1-'<',2-'>',3-'<=',4-'>=' var u : boolean;
begin u:=false; case cond of
0:if x=y then u:=true;
1:if x<y then u:=true;
2:if x>y then u:=true;
3:if x<=y then u:=true;
4:if x>=y then u:=true;
else writeln('CompareDataError') end;
Compare:=u;
end;
//Пошук за ключовим значенням
procedure FindKey(n: integer; A: TMas; key: integer; var k: integer; var Indexes: TMas); //n - кількість елементів масиву
//A - масив, у якому здійснюється пошук //key - ключове значення
//k - кількість елементів масиву, що співпадають з ключовим значенням //Indexes - масив індексів елементів, співпадають з ключовим значенням var i: integer;
112

begin k:=0;
for i:=1 to n do
if A[i]=key then begin k:=k+1; Indexes[k]:=i; end;
end;
//Пошук екстремальних значень та їх індексів
procedure Extrem(n: integer; A: TMas; var min, max, k1, k2: integer; var IndMin, IndMax:
TMas);
//n - кількість елементів масиву
//A - масив, у якому здійснюється пошук
//min, max - екстремальні (мінімальне та максималне) значення елементів масиву //k1, k2 - кількість екстремальних елементів масиву
//IndMin, IndMax - масивb індексів екстремальних елементів масиву var i: integer;
begin
min:=A[1]; max:=A[1]; for i:=2 to n do
begin
if A[i]<min then min:=A[i]; if A[i]>max then max:=A[i]; end;
FindKey(n, A, min, k1, IndMin); FindKey(n, A, max, k2, IndMax); end;
//Пошук елементів масиву, що задовільняють граничному значенню procedure FindGran(n: integer; A: TMas; gran: integer; napr: char;
include: boolean; var k: integer; var B,Indexes: TMas); //n - кількість елементів масиву
//A - масив, у якому здійснюється пошук //gran - граничне значення елементів масиву //napr - 'l'-ліва границя, 'r'-права границя
//include - ознака включення до результату пошуку граничного значення: true-так,
false-ні
//k - кількість елементів масиву, що задовільняють умовам пошуку //B - масив елементів масиву, що задовільняють умовам пошуку
//Indexes - масив індексів елементів масиву, що задовільняють умовам пошуку var i,c: integer;
begin c:=-1;
//Визначення умов порівняння для функції Compare на основі значень вхідних даних if (napr='l') and (not include) then c:=2;
if (napr='r') and (not include) then c:=1;
if (napr='l') and (include) |
then c:=4; |
if (napr='r') and (include) |
then c:=3; |
113

for i:=1 to n do
if Compare(A[i],gran,c) then begin
k:=k+1;
B[k]:=A[i];
Indexes[k]:=i;
end;
end;
//Пошук елементів масиву в заданому діапазоні procedure FindDiap(n: integer; A: TMas; d1,d2: integer;
include, include1,include2: boolean; var k: integer; var B,Indexes: TMas); //n - кількість елементів масиву
//A - масив, у якому здійснюється пошук //d1,d2 - граничні значення діапазону
//include - ознака пошуку: true-в діапазоні, false-за межами діапазону
//include1,include2 - ознаки включення до результату пошуку граничних значень: trueтак, false-ні
//k - кількість елементів масиву, що задовільняють умовам пошуку //B - масив елементів масиву, що задовільняють умовам пошуку
//Indexes - масив індексів елементів масиву, що задовільняють умовам пошуку var i,c1,c2: integer; yy: boolean;
begin
c1:=-1; c2:=-1;
//Визначення умов порівняння для функції Compare на основі значень вхідних даних
if (include) |
and (not include1) then c1:=2; |
if (include) |
and (include1) then c1:=4; |
if (not include) and (not include1) then c1:=1;
if (not include) and (include1) |
then c1:=3; |
|
if (include) |
and (not include2) then c2:=1; |
|
if (include) |
and (include2) |
then c2:=3; |
if (not include) and (not include2) then c2:=2; if (not include) and (include2) then c2:=4; for i:=1 to n do
begin
if include //контроль виконання умов критерію пошуку
then yy:=(Compare(A[i],d1,c1)) and (Compare(A[i],d2,c2)) //в інтервалі
else yy:=(Compare(A[i],d1,c1)) or (Compare(A[i],d2,c2)); //за межами інтервалу if yy
then begin k:=k+1; B[k]:=A[i]; Indexes[k]:=i; end;
end;
end;
end.
114
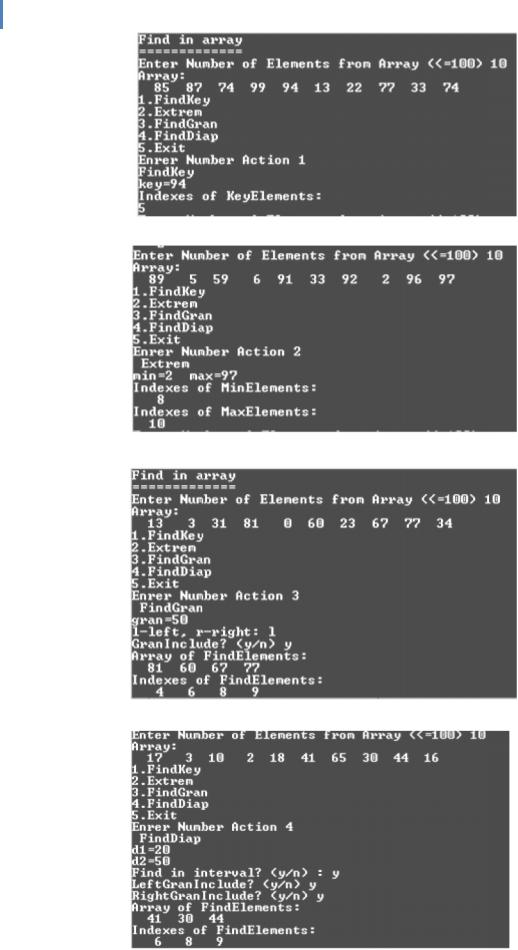
Рис.1. Результат пошуку за ключовим значенн ям
Рис.2. Результат пошуку екстремальних значень
Рис.3. Результат пошуку за граничною умово ю
Рис.4. Результат пошуку в діапазоні
115