

Теоретичний матеріал
Передача інформації
Передача інформації на відстань зазвичай здійснюється за класичною схемою Шеннона (рис.1).

Рис.1. Передача інформації
Інформацію передають у вигляді повідомлень від джерела до адресата.
Повідомлення - це закодована за допомогою будь-яких символів інформація, призначена для передавання.
Повідомлення за допомогою передавача перетворюється (кодується) в послідовність сигналів. Ці сигнали передається каналом зв'язку до приймача, де відбувається декодування сигналів в повідомлення. Передача інформації каналами зв’язку часто супроводжується впливом завад, які викликають спотворення чи втрату інформації.
Не існує взаємно-однозначної відповідності між інформацією і повідомленням: одну і ту саму інформацію можна передати за допомогою різних повідомлень. І навпаки, одне і те саме повідомлення може нести різну інформацію залежно від того, як інтерпретують (тлумачать) повідомлення різні люди чи одні й ті самі люди за різних обставин, щодо якого предмета (властивостей) досліджується той чи інший об'єкт (явище природи) деяким суб'єктом (людиною).
Так, наприклад, слова «хороша погода» можуть означати і сонячну погоду, і дощову, і теплий літній день, і морозний зимовий. Слова «найкраща пора року» для одних людей можуть означати весну, для інших осінь, ще для інших — літо або зиму.
Оскільки кожна людина в одному і тому самому повідомленні бачить свою інформацію, по своєму його тлумачить, то краще говорити про носії повідомлень, а не про носії інформації, оскільки інформація в одному і тому самому повідомленні може бути різна.
Зростаючі потоки даних, необхідність зберігання їх у великих обсягах сприяли розробці і застосуванню носіїв повідомлень, що забезпечують можливість довготривалого їх зберігання в компактній формі. Носій – фізичне середовище, в якому зберігаються повідомлення. Прикладами носіїв повідомлень є медичні картки, рентгенівські плівки, електромагнітні хвилі, тощо.
Технічне та програмне забезпечення комунікацій
Телекомунікації - це передавання і приймання такої інформації як звук, зображення, дані та текст на великі відстані електромагнітними системами: кабельними каналами; оптоволоконними каналами; радіоканалами та іншими каналам зв'язку.
Телекомунікаційна мережа - це сукупність технічних і програмних засобів, за допомогою яких здійснюються телекомунікації.
До телекомунікаційних мереж відносяться:
1. Комп'ютерні мережі (мережі передавання даних).
2. Телефонні мережі (передавання голосової інформації).
3. Радіомережі (передача голосової інформації - широкомовні послуги).
4. Телевізійні мережі (передавання голосу і зображення - широкомовні послуги).
Обчислювальні мережі створюються з метою доступу до загальносистемних ресурсів (інформаційних, програмних і апаратних), розподілених (децентралізованих) у цій мережі. За територіальною ознакою розрізняють мережі локальні і територіальні (регіональні та глобальні).
Комп'ютерна мережа – це сукупність комп'ютерів, які можуть здійснювати інформаційну взаємодію один з одним за допомогою комунікаційного устаткування і програмного забезпечення.
Комп'ютерні мережі зв'язують комп'ютери, кожен з яких може працювати і автономно. Для класифікації комп'ютерних мереж використовуються різні ознаки, але найчастіше їх поділяють за територіальними ознаками, тобто відповідно до величини території, яку покриває мережа.
До локальних мереж (Local Area Networks, LAN) відносять мережі комп'ютерів, зосереджених на невеликій території і об'єднаних між собою високошвидкісним каналом передачі цифрових даних. У загальному випадку локальна мережа є комунікаційною системою, що належить одній організації, призначена для спільного використання мережених пристроїв (принтери, сканери, плотери і т.д.) та обміну інформацією.
Усі комп’ютери в мережі можна поділити на два типи: робочі станції та сервери.
Робочі станції – це комп’ютери, за якими безпосередньо працюють користувачі.
Сервери – це спеціально виділені машини, призначені для обслуговування робочих станцій користувачів (клієнтів). Сервер здійснює обробку та зберігання основної інформації, що знаходиться в комп’ютерній мережі. Сервер надає ресурси необхідні багатьом користувачам: бази даних, файли, пам'ять та ін., а також визначає умови використання спільних ресурсів – наприклад, тільки їх перегляд, читання чи можливість зміни. У зв’язку з рiзноманiтнiстю використовуваної інформації та видів її обробки існують різні типи серверів: поштові, файлові принт-сервери та ін. Найпоширенішим є файловий сервер - комп’ютер, який підключений до обчислювальної мережі i використовується для зберігання файлів даних, до яких звертаються робочі станції. З точки зору користувача файловий сервер розглядається як центральний архів, в якому зберігається спільна для всіх робочих станцій інформація.
Комп'ютер, будь то сервер або робоча станція, підключається до мережі за допомогою мережевої плати (мережевого адаптера, мережевої карти). Мережева плата вставляється в гніздо материнської плати, хоча бувають і зовнішні мережеві адаптери, що підключаються до комп'ютера через паралельний порт. В даний час, особливо в персональних комп'ютерах, мережеві плати досить часто інтегровані в материнські плати для зручності і здешевлення всього комп'ютера в цілому. Дані, взяті з одного ПК за допомогою мережевої плати, перетворюються у відповідний формат і посилаються по з'єднувальному кабелю до мережевої плати іншого комп'ютера, яка приймає дані, перетворює їх у формат, зрозумілий для ПК, і передає в оперативну пам'ять. Усі ці дії відбуваються під керівництвом відповідного програмного забезпечення - мережевої операційної системи.
При проектуванні мереж насамперед необхідно вибрати спосіб організації фізичних зв'язків, тобто топологію. Під топологією (конфігурацією, структурою) комп’ютерної мережі звичайно розуміється фізичне розташування комп’ютерів у мережі, спосіб з’єднання їх лініями зв’язку. особливості поширення сигналів мережею.
Вибір топології електричних зв'язків істотно впливає на багато характеристик мережі. Наприклад, наявність резервних зв'язків підвищує надійність мережі і робить можливим балансування завантаження окремих каналів. Характер зв’язків визначає ступінь відмовостійкості мережі, необхідну складність мережної апаратури, найбільш підходящий метод керування обміном, можливі типи середовищ передачі (каналів зв’язку), припустимий розмір мережі (довжина ліній зв’язку й кількість абонентів) і т.д. Простота приєднання нових вузлів, властива деяким топологіям, дозволяє легко розширювати мережу. З економічних міркувань часто вибирають топології, для яких характерна мінімальна сумарна довжина ліній зв'язку.
Розрізняють три найбільш розповсюджені мережні топології: шинна, кільцева і зіркоподібна. Решта способів є комбінаціями базових.
В мережах з шинною топологією (рис.2.) робочі станції з допомогою мережевих адаптерів підключаються до магістралі (шини). Аналогічним чином до загальної магістралі підключаються й інші мережеві пристрої. На кінцях кабелю знаходяться термінатори, для запобігання поверненню сигналу. В процесі роботи мережі інформація від передаючої робочої станції поступає на адаптери всіх робочих станцій, але сприймається вона тільки адаптером тієї робочої станції, якій вона адресована.
Подібна лінійна топологія характеризується простотою організації i можливістю підключення нових робочих станцій без додаткового обладнання. Такій мережі не страшні відмови окремих комп’ютерів, тому що всі інші комп’ютери мережі можуть нормально продовжувати обмін. Однак при такому з’єднанні комп’ютери можуть передавати повідомлення тільки по черзі, тому що лінія зв’язку єдина. У противному випадку передана інформація буде спотворюватися внаслідок накладення (конфлікту, колізії). Таким чином, у шині реалізується режим напівдуплексного (half duplex) обміну (в обох напрямках, але по черзі, а не одночасно). Ще одним недоліком є те, що будь-який дефект кабелю чи якого-небудь із численних роз’ємів повністю паралізує роботу всієї мережі.
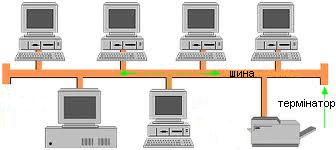
Рис.2. Шинна топологія
Кільцева мережа (рис.3) характеризується наявністю замкненого однонаправленого каналу передачі даних у вигляді кільця або петлі. Кожний комп’ютер з’єднаний лініями зв’язку тільки із двома іншими: від одного він тільки одержує повідомлення, а іншому тільки передає. У цьому випадку повідомлення передається послідовно між адаптерами робочих станцій доти, поки не буде прийнята одержувачем i потім видалена з мережі. Переважно за видалення iнформацiї з мережі вiдповiдає її відправник. Важлива особливість кільця полягає в тому, що кожен комп'ютер ретранслює (відновлює, підсилює) сигнал, тобто виступає в ролі репітера. Загасання сигналу в усьому кільці не має ніякого значення, важливо тільки загасання між сусідніми комп'ютерами кільця. Управління роботою кільцевої мережі може здійснюватися централізовано з допомогою спеціальної монiторної станції або децентралізовано за рахунок розподілу функцій управління мiж всіма робочими станціями. Недоліком кільцевої топології є те, що відмова однієї ланки кільця може вивести з ладу всю локальну мережу. З метою підвищення надiйностi кільцевих структур використовують спецiальнi безрозривнi комутатори, якi дозволяють автоматично відключати неробочі комп’ютери або окремі сегменти мережі.
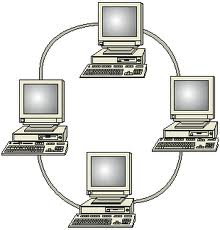
Рис.3. Кільцева топологія.
Зіркоподібна мережа (рис. 4) характеризується наявністю центрального вузла комутації — мережного сервера, до якого (або через який) надсилаються всі повідомлення (активна зірка), або концентратора (hub) (пасивна зірка).
У випадку активної зірки весь обмін інформацією йде винятково через центральний комп’ютер, на який у такий спосіб лягає найбільше навантаження, тому саме центральний комп’ютер є найпотужнішим, і саме на нього покладають всі функції по керуванню обміном
У випадку пасивної зірки робоча станція, якій треба відправити дані, відправляє їх на концентратор, а той визначає адресата і відправляє йому інформацію. В певний момент часу тільки одна машина в мережі може пересилати дані, якщо на концентратор одночасно приходять два пакети, то вони обидва не приймаються і відправник чекатиме випадковий проміжок часу щоб відновити передачу даних.
Головною перевага даної топології є вища надійність. Вихід з ладу однієї робочої станції не відображається на роботі всієї мережі. Пошкодження кабелю стосується лише того комп’ютера, до якого цей кабель приєднаний, і тільки несправність концентратора може вивести з ладу всю мережу. Крім того, концентратор може відігравати роль інтелектуального фільтра інформації, що поступає від різних станцій у мережу, і при необхідності блокувати заборонені адміністратором передачі. До недоліків топології типу зірка відноситься вища вартість мережевого обладнання. Крім того, кількість робочих станцій у мережі обмежуються кількістю портів концентратора.
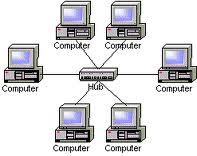
Рис.4 Зіркоподібна топологія
Глобальні мережі (Wide Area Networks, WAN) об'єднують комп'ютери, що територіально розосередилися, які можуть знаходитися в різних містах і країнах. Оскільки прокладка високоякісних ліній зв'язку на великі відстані обходиться дуже дорого, в глобальних мережах часто використовуються вже існуючі лінії зв'язку, спочатку призначені зовсім для інших цілей. Наприклад, багато глобальних мереж будується на основі телефонних і телеграфних каналів загального призначення. Через низькі швидкості таких ліній зв'язку в глобальних мережах (десятки кілобіт в секунду) набір послуг, що надаються звичайно обмежується передачею файлів, переважно не в оперативному, а в фоновому режимі, з використанням електронної пошти.
Термінальні мережі зазвичай пов'язують потужні комп'ютери (мейнфрейми) з терміналами (пристроями вводу-виводу інформації). Прикладом термінальних пристроїв і мереж може служити мережа банкоматів або кас продажу квитків.
Основна відмінність локальних мереж від глобальних полягає в якості використаних ліній зв'язку і в тому, що в локальних мережах існує тільки один шлях передавання даних між комп'ютерами, а в глобальних мережах їх багато (у глобальних мережах існує надмірність каналів зв'язку). Оскільки лінії зв'язку в локальних мережах якісніші, то швидкість передавання інформації в локальних мережах набагато вища, ніж в глобальних.
Останнім часом здійснюється постійне проникнення технологій локальних мереж у глобальні й навпаки, що значно підвищує якість мереж і розширює спектр послуг, що надаються. Таким чином, відмінності між локальними і глобальними мережами поступово зникають.
Тенденція зближення (конвергенція) характерна не лише для локальних і глобальних обчислювальних мереж, але і для телекомунікаційних мереж інших типів, до яких відносяться радіо, телефонні і телевізійні мережі. Телекомунікаційні мережі складаються з наступних компонентів: мережі доступу, магістралі, інформаційні центри.
Комп'ютерну мережу можна подати як багатоверству модель, яка складається з:
-
комп'ютерів;
-
комунікаційного устаткування;
-
операційних систем.
-
мережевих додатків
У комп'ютерних мережах використовуються різні типи і класи комп'ютерів. Комп'ютери та їх характеристики визначають можливості комп'ютерних мереж.
До комунікаційного устаткування відносяться: модеми, мережеві плати, мережеві кабелі та апаратура мереж. До апаратури відносяться: приймачі або трансивери (traceivers), репітери (repeaters), концентратори (hubs), мости (bridges), комутатори, маршрутизатори (routers), шлюзи (gateways).
Ефективність роботи всієї мережі залежить від того, які концепції управління локальними і розподіленими ресурсами покладено в основу мережевої операційної системи. При проектуванні мережі важливо враховувати, наскільки просто операційна система може взаємодіяти з іншими операційними системами мережі, наскільки вона забезпечує безпеку і захищеність даних, до якої міри вона дозволяє нарощувати число користувачів, чи можна перенести її на комп'ютер іншого типу і багато іншого.
До мережевих додатків належать мережеві бази даних, поштові системи, ресурси архівування даних, системи автоматизації колективної роботи та ін.
Для забезпечення взаємодії програмно-апаратних комплексів у комп'ютерних мережах було прийнято єдині правила або стандарт, який визначає алгоритм передавання інформації в мережах. Як стандарт були прийняті мережеві протоколи, які визначають взаємодію устаткування в мережах.
Стандарт (протокол) передавання даних — це програмні правила взаємодії функціональних елементів комп'ютерної мережі, тобто правила обміну інформацією між комп'ютерами й периферійним устаткуванням, об'єднаним у мережу, які визначають тип, фізичні сигнали, їх послідовність в часі, алгоритми прийому, контролю і передачі повідомлень, а також склад службової інформації самих повідомлень.
Оскільки взаємодія устаткування в мережі не може бути описана одним єдиним мережевим протоколом, то було застосовано багаторівневий підхід до опрацювання засобів мережевої взаємодії. У результаті було розроблено семирівневу модель взаємодії відкритих систем - OSI.
Ця модель розділяє засоби взаємодії на сім функціональних рівнів: прикладний, представницький (рівень представлення даних), сеансовий, транспортний, мережевий, канальний і фізичний.
Набір протоколів, достатній для організації взаємодії устаткування в мережі, називається стеком комунікаційних протоколів. Найбільш популярним є стек - TCP/IP. Цей стек використовується для зв'язку комп'ютерів в мережі Інтернет і в корпоративних мережах.
Протоколи реалізуються автономними і мережевими операційними системами (комунікаційними засобами, які входять до ОС), а також пристроями телекомунікаційного устаткування (мостами, комутаторами, маршрутизаторами, шлюзами).
До мережевих застосувань відносяться різні поштові прикладні програми (Outlook Express, The Bat, Eudora та інші), браузери - програми для проглядання веб-сторінок (Internet Explorer, Opera, Mozzila Firefox та інші), прикладні програми для створення сайтів (Macromedia HomeSite Plus, WebCoder, Macromedia Dreamweaver, Microsoft FrontPage) та інші.
Глобальна інформаційна мережа Інтернет
Глобальна інформаційна мережа Інтернет – це об'єднання транснаціональних комп'ютерних мереж з різними типами і класами комп'ютерів та мережевого устаткування, що працюють за різними протоколами і передають інформацію за різними каналами зв'язку (рис.5).
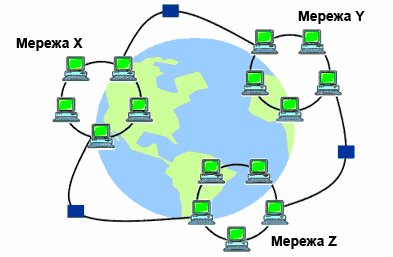
Рис.5. Структура Інтернет
Інтернет - це потужний засіб телекомунікації, зберігання та надання інформації, ведення електронного бізнесу та дистанційного (інтерактивного або он-лайн) навчання.
Інформація в Інтернет зберігається на серверах (хостах). Сервери мають свої адреси і керуються спеціалізованими програмами. Вони дозволяють пересилати пошту і файли, проводити пошук в базах даних і виконувати інші завдання. У більш загальному значенні під хостом розуміють будь-який комп’ютер, сервер під’єднаний до мережі.
Сервери, об'єднані високошвидкісними магістралями, складають базову частину мережі Інтернет.
Передача інформації в Інтернет забезпечується завдяки тому, що кожен комп'ютер в мережі має унікальну адресу (IP-адреса), а мережеві протоколи забезпечують взаємодію різнотипних комп'ютерів, що працюють під управлінням різних операційних систем.
Адресація в Internet
Кожен комп’ютер, під’єднаний до Internet, має свою унікальну адресу, яка називається IP-адресою. IP-адреси відповідно до версії 4 (IPv4) — це 32-бітові числа, що розбиваються на октети (восьми бітові числа), які записують у вигляді послідовності з чотирьох чисел, розділених крапками, наприклад 124.44.186.11. Кожне число може бути в інтервалі від 0 до 255, що відповідає інформаційному обсязі в 1 байт або 8 біт. Таким чином, IP-адреса – це 4 байти або 32 біта.
Перші три частини адреси позначають належність до певного класу мереж, а остання є унікальною для окремого комп’ютера. Коли формується мережа, їй присвоюється номер, який визначає кількість комп’ютерів у межах цієї мережі. IP-адреси окремим комп’ютерам призначають із заданого таким чином діапазону.
Існує 5 класів IP – адрес – A, B, C, D, E. Приналежність IP – адреси до того або іншого класу, визначається значенням першого октету.
|
Клас |
Перше число в адресі |
Можлива кількість мереж
|
Можлива кількість комп’ютерів в однієї мережі
|
Вид адреси
|
|
A |
0-127 |
126 |
16 777 216 |
sss.xxx.xxx.xxx |
|
B |
128-191 |
16 382 |
65 536 |
sss.sss.xxx.xxx |
|
C |
192-223 |
2 097 150 |
256 |
sss.sss.sss.xxx |
|
D |
224-239 |
|
застосовують для багатоадресних розсилань |
де sss- номер мережі, xxx - номер хосту |
|
E |
240-255 |
|
зареєстровані для експериментальних цілей |
|
IP–адреси перших трьох класів призначені для адресації окремих вузлів і окремих мереж. Такі адреси складаються з двох частин – номер мережі і номер вузла. Адреси різних класів відрізняються розрядністю їх номерів, що визначає можливий їх діапазон значень. Адреси класу D використовуються в службових цілях в для одночасної передачі даних по багатьом адресах, а діапазон адрес E зарезервований для майбутнього використання.
IPv6 (Internet Protocol version 6) — нова версія IP-протоколу — IP версії 6. Розробка протоколу IPv6 почалася 1992 року, а з 2003 р. його підтримку забезпечують виробники більшості телекомунікаційного устаткування (корпоративного рівня). IPv6 — новий крок у розвитку Інтернету. Цей протокол розроблено з урахуванням вимог до Глобальної мережі, що зростають. При нинішніх темпах розвитку мережі за умови використання старого протоколу IPv4 адреси закінчаться до 2012 року.
Протокол IPv6 виділяє на адресу 16 байтів (128 біт). Це відповідає 2128 чи приблизно 3.4×1038 адрес
IP-адреси бувають статичними і динамічними. Для сервера, на якому зберігається інформація, необхідна постійна (статична) IP-адреса, інакше дані не будуть знайдені. Для користувача, що входить в Інтернет на декілька годин, IP-адреса може бути виділена динамічно з деякої кількості вільних номерів.
IP-адреса називається динамічною, якщо вона виділяється автоматично при підключенні до мережі і використовується протягом обмеженого проміжку часу, переважно до завершення сеансу під’єднання.
Для адміністрування (керування) мережею така система адресації зручна, а ось для користувачів - ні. Не зручно постійно пам'ятати набори цифр, їх можна легко переплутати, крім того, вони можуть змінюватися. Тому поряд з ІР- адресацією була введена доменна система імен (DNS). Кожен рівень в такій системі називається доменом. Типове ім'я домену складається з декількох частин, розташованих в певному порядку і розділених крапками. Домени відділяються один від одного крапками, наприклад: fizmat.tnpu.edu.ua
Доменна структура Інтернет є ієрархічною. Найвищий (кореневий) рівень не має назви. Далі йде обмежена кількість доменів верхнього рівня, в яких може бути практично необмежена кількість доменів 2-го рівня і т. д.
Домен верхнього рівня розташовується в імені правіше, а домен нижнього рівня - лівіше. В імені може бути довільна кількість доменів, але більше п'яти зустрічається рідко. Кожен наступний домен в імені (якщо дивитися зліва направо) є підмножиною наступного. Домени Internet вкладаються один в одного. Наприклад, комп’ютер meduniv.lviv.ua перебуває водночас у домені медичного університету - meduniv.lviv.ua , у домені Львова - lviv.ua і в домені України - ua (рис.6).
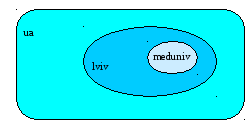
Рис.6. Структура доменного імені
Доменна система утворення адрес гарантує, що у всьому Internet більше не знайдеться іншого комп'ютера з такою ж адресою. Уведене доменне ім’я автоматично перетворюється на зрозумілу комп’ютеру цифрову IP-адресу. За це відповідає DNS-служба, яка кожному доменному імені ставить у відповідність IP-адресу.
Для доменів нижніх рівнів можна використовувати будь-які адреси, але для доменів самого верхнього рівня існує угода.
Імена доменів верхнього рівня (Top Level Domains, TLDs) стандартизовані. Їх можна поділити на два типи: загальні (родові) домени (generic Top Level Domains, gTLDs) та національні домени (country code Top Level Domains, ссTLDs).
Найпоширенішими є родові домени, які визначають прикладний напрямок мережі:
.com — комерційні організації,
.edu — університети та інші навчальні заклади,
.gov — урядові установи,
.int — міжнародні організації,
.mil — військові організації (армія, флот і т.д.),
.net — провайдери послуг Internet
.org — некомерційні організації, які не входять до вищеназваних категорій.
З 1997 року було впроваджено нові домени верхнього рівня, серед яких:
-
.aero
—
авіатранспорт,
.arts
—
культура і розваги,
.biz
—
бізнес,
.coop
—
кооперативи,
.firm
—
бізнес,
.info
—
Інформаційні послуги,
.museum
—
музеї,
.name
—
приватні особи,
.nom
—
персональні,
.pro
—
сертифіковані професіонали (юристи, економісти і т.п.)
.rec
—
відпочинок і розваги,
.shop
—
магазини,
.web
—
WWW-діяльність,
store
—
для торгівлі.
Імена національних доменів верхнього рівня завжди подаються як двобуквене скорочення назви країни, зазвичай, згідно зі стандартом ISO-3166-1 (звідси їх позначення — ccTLDs, country-code Top Level Domains, домени верхнього рівня з кодами країн).
Приклади:
.uа — Україна,
.uk — Великобританія,
.us — США,
.ca — Канада,
.eu — Європейський Союз,
.fr- Франція,
.jp – Японія,
.іt – Італія,
.ru - Росія.
За призначенням домени поділяють на публічні (спільного користування) — такі, що адмініструються в інтересах певної спільноти, та приватні, що адмініструються певною фізичної або юридичною особою у своїх власних інтересах. Так, домен .ua адмініструється в інтересах української Інтернет-спільноти — спільноти всіх громадян і/або резидентів України, фізичних та юридичних осіб, органів державної влади та управління України, органів місцевого самоврядування, які використовують мережу Інтернет та Інтернет-технології, незалежно від мети та способів такого використання.
У публічному домені можуть бути як публічні, так і приватні піддомени згідно з правилами публічного домену попереднього рівня, а у приватному домені публічні доменні імена неможливі.
Організацією доменної системи імен займається міжнародний консорціум з присвоєння доменних імен (ICANN, www.icann.org), який делегує права щодо присвоєння імен фірмам – членам консорціуму.
Сімейство мережевих протоколів TCP/IP
В основному в Інтернет використовується сімейство мережевих протоколів TCP/IP (Transmission Control Protocol/Internet Protocol).
Основою сімейства протоколів TCP/IP є мережевий рівень, представлений протоколом IP, а також різними протоколами маршрутизації. Цей рівень забезпечує можливість з'єднання i вибір маршруту між двома кінцевими системами, підключеними до різних мереж, які можуть знаходитися в різних географічних пунктах. Оскільки дві кінцеві системи, бажаючі організувати взаємодію, можуть бути розділені значною географічною віддаллю i безліччю інших підмереж, мережевий рівень забезпечить маршрутизацію пакетів від одного віддаленого вузла до іншого.
У сучасних комп’ютерних мережах використовується пакетна передача даних (packet switching and forwarding). Пакет – невеликий фрагмент даних, які передаються. У протоколі TCP/IP пакет, крім власне даних, містить номер пакета, адресу походження та адресу хоста, до якого він має бути доставлений мережею, а також багато інших службових параметрів. Пакетна передача даних підвищує надійність та швидкодію мережі. Вузли мережі (маршрутизатори) доправляють пакет тим з можливих маршрутів, який на даний час є оптимальним.
Маршрутизатор - це пристрій, який збирає інформацію про топологію міжмережевих з'єднань і на її основі пересилає пакети в мережу призначення. Щоб передати повідомлення від відправника, що знаходиться в одній мережі, одержувачу, що знаходиться в іншій мережі, треба здійснити деяку кількість транзитних передач між мережами, кожний раз вибираючи відповідний маршрут. Таким чином, маршрут являє собою послідовність маршрутизаторів, через які проходить пакет. Проблема вибору найкращого шляху називається маршрутизацією, і її розв'язання є однією з головних задач мережевого рівня. Ця проблема ускладнюється тим, що найкороткий шлях не завжди найкращий. Часто критерієм при виборі маршруту є час передачі даних по цьому маршруту, який залежить від пропускної спроможності каналів зв'язку і інтенсивності трафіка. Деякі алгоритми маршрутизації намагаються пристосуватися до зміни навантаження, в той час як інші приймають рішення на основі середніх показників за тривалий час. Вибір маршруту може здійснюватися і за іншими критеріями, наприклад надійність передачі.
Визначення розміру пакету, параметри передачі, контроль цілісності здійснюється на транспортному рівні TCP. Завданням ТСР є доставка всієї інформації комп'ютеру одержувача, контроль послідовності інформації, що передається, повторна відправка не доставлених пакетів у випадку збоїв роботи мережі. Крім того, якщо повідомлення велике, щоб відправити його в одному пакеті, ТСР ділить i відправляє його декількома блоками. Пакети доставляються незалежно один від одного і збираються у вузлі-одержувачі. ТСР здійснює контроль за складанням початкового повідомлення із цих блоків на комп’ютері одержувача.
Служби мережі Інтернет
Служби (сервіси) – це види послуг, що надаються серверами мережі Інтернет. В історії Інтернет існували різні види сервісів, одні з яких сьогодні вже не використовуються, інші поступово втрачають свою популярність, тоді як треті переживають свій розквіт. Розглянемо ті з сервісів, що не втратили своєї актуальності на даний момент:
WWW (World Wide Web) – всесвітня павутина - Веб – служба пошуку і перегляду гіпертекстових документів, що включають у себе графіку, звук і відео. WWW працює за принципом клієнт-сервер: існує велика кількість серверів, які за запитом клієнта надають йому гіпермедійний документ (Web-сторінку) — документ, що складається із частин з різними формами представлення інформації (текст, звук, графіка, тривимірні об’єкти, тощо), в якому кожен елемент може бути посиланням на інший документ чи його частину. Гіпертекстове посилання – це виділений фрагмент тексту (або ілюстрація), з яким пов’язана мережева адреса іншої Web-сторінки. Кожен інформаційний ресурс у глобальній мережі Інтернет однозначно адресується, і документ, який зчитується в даний момент, може посилатися як на документи (і взагалі ресурси Інтернет), що знаходяться на тому ж сервері, що і цей документ, так і на документи, які знаходяться на інших комп’ютерах Інтернет, причому користувач не помічає цього і працює з усім інформаційним простором Інтернет як з єдиним цілим. Посилання WWW вказують не тільки на документи, специфічні для самої WWW, але й на інші сервіси та інформаційні ресурси Інтернет. Більшість програм-клієнтів WWW (браузерів) не просто розуміють такі посилання, а є програмами-клієнтами відповідних сервісів: FTP, Gopher, новин мережі Usenet, електронної пошти та інших. Програмні засоби WWW є універсальними для різних сервісів Інтернет, а інформаційна система WWW відіграє інтегруючу роль.
Гіпермедійні документи, які використовують в WWW для представлення інформації, переважно мають формат HTML (hyper text markup language, мова гіпертекстової розмітки). Цей формат не описує те, як документ повинен виглядати, а його структуру і зв’язки. Зовнішній вигляд документа на екрані користувача визначається навігатором — в залежності від того чи користувач працює за графічним чи текстовим терміналом документ на екрані матиме різний вигляд, але його структура залишиться незмінною, оскільки вона задана форматом html. Імена файлів у форматі html, зазвичай, закінчуються на html (або мають розширення htm у випадку, якщо сервер працює під Windows).
Протокол, за яким взаємодіють клієнт та сервер WWW називається HTTP (hypertext transfer protocol, протокол передавання гіпертексту). Перегляд гіпермедійних документів і переміщення гіперпосиланнями здійснюється за допомогою програм-браузерів (наприклад, Internet Explorer, Mozilla Firefox, Opera та ін..)
E-mail – електронна пошта – служба передачі електронних повідомлень. Електронна пошта — типовий сервіс відкладеного зчитування (off-line). Робота зі службою починається з того, що користувач заводить на поштовому сервері скриньку, яка має певну адресу. Знаючи цю адресу інший користувач може підключитися до поштового сервера і надіслати адресату повідомлення. Після відправлення повідомлення, як правило, у вигляді звичайного тексту, адресат отримує його на свій комп'ютер через деякий період часу, і знайомиться з ним, коли йому буде зручно. Функціонування електронної пошти побудоване на принципі клієнт-сервер, стандартному для більшості мережевих сервісів. Існує багато різних програм-клієнтів електронної пошти, які можуть відрізнятися окремими функціями, можливостями та інтерфейсом, зокрема й такі, що працюють на сервері (в режимі on-line). Проте, загальні функції у більшості пакетів однакові. До них можна віднести: підготовка тексту, імпорт файлів-додатків, відправка листа, перегляд і збереження кореспонденції, знищення кореспонденції, підготовка відповіді, коментування і пересилка інформації, експорт файлів-додатків.
Користувач може працювати з сервером електронної пошти через:
-
спеціалізовані програми - клієнти електронної пошти (Microsoft Outlook, Pegasus Mail, Eudora, The Bat, Thunderbird та інші).
-
Web-інтерфейс web-браузера (без інсталяції спеціалізованих програм), використовуючи безкоштовні «поштові скриньки», які пропонуються більшістю пошукових систем (Google, Yahoo, Мета та ін.)
Кожен підхід має свої переваги та недоліки. Спеціалізовані клієнти як The Bat чи Thunderbird зручні для персонального комп’ютера з періодичним підключенням до Інтернету. Натомість працювати з електронною поштою через Web-інтерфейс застосовуючи веб-браузер Ви можете з будь-якого комп’ютера, наприклад Інтернет-кафе.
Для доступу та маніпулювання повідомленнями електронної пошти на сервері використовується протоколи ІMAP (Internet Message Access Protocol - Протокол Доступу до Інтернет Повідомлень) та POP (Post Office Protocol - Поштовий Офісний Протокол). Для пересилання електронної пошти до поштового сервера або з клієнта-комп'ютера, або між поштовими серверами використовується протокол SMTP (Simple Mail Transfer Protocol -Простий Протокол Пересилання Пошти).
Список розсилання (mailing list, mail-list) — сервіс Інтернет, що надає можливість об'єднати певну кількість людей в єдину закриту групу розсилання. Це практично єдиний сервіс, який не має власного протоколу та програми-клієнта і працює винятково через електронну пошту. При цьому e-mail адреси учасників приховані, а спілкування між ними відбувається через єдину e-mail адресу. Кожному, хто бажає стати учасником списку розсилання чи від'єднатись від нього, достатньо написати листа на адресу списку.
Ідея роботи списку розсилання полягає в тому, що існує деяка адреса електронної пошти, яка насправді є загальною адресою багатьох людей-передплатників цього списку розсилання. Користувач посилає лист за цією адресою і його отримують люди, які передплатили цей список розсилання. При цьому авторові не потрібно знати адреси усіх зацікавлених осіб. Новий учасник такого списку може відразу включатися у дискусію, не збираючи адреси всіх інших учасників. Також відпадає потреба щоразу складати перелік адрес, на які має прийти лист.
Списки розсилання можуть бути використані з метою:
-
одностороннього розсилання новин (як правило від однієї адреси усім іншим);
-
дискусії між учасниками.
IP-телефонія — це технологія, що дозволяє використовувати будь-яку IP-мережу як засіб організації та ведення телефонних розмов, передавання відеозображень та факсів у режимі реального часу.
При відправленні або отриманні електронної пошти відбувається передавання "пакету" інформації через мережу Інтернет. Аналогічним чином працює й IP-телефонія. Створення "пакетів" — перетворення аналогових (зокрема, звукових) сигналів у цифрові, їх стискання, передавання мережею Інтернет і зворотне перетворення в аналогові відбувається завдяки існуванню протоколу передавання даних через Інтернет (IP — Internet Protocol), звідси і назва "IP-телефонія".
FTP – служба передавання файлів. Протокол передавання файлів FTP (File Transfer Protocol) - дає можливість абоненту обмінюватися двійковими і текстовими файлами з будь-яким комп’ютером мережі, що підтримує протокол FTP. Установивши зв’язок із віддаленим комп’ютером, користувач може скопіювати файл із віддаленого комп'ютера на свій або скопіювати файл зі свого комп'ютера на віддалений. При цьому не має великого значення, якого типу будуть ці комп’ютери і в якій операційній системі вони працюють.
ICQ – служба для спілкування в реальному часі за допомогою клавіатури.
TELNET – віддалений доступ. З допомогою програми TELNET можливий віддалений доступ до комп’ютера через Інтернет і робота з ним. Щоб отримати доступ до віддаленого комп’ютера необхідно ввести ім’я користувача і пароль. Можливості роботи з віддаленим комп’ютером визначається рівнем доступу, який задається адміністратором мережі.
Універсальний вказівник ресурсу
IP-адреса або відповідне йому доменне ім'я дозволяють однозначно ідентифікувати комп'ютер у мережі Internet, але справа в тому, що на комп'ютері може бути міститися безліч різної інформації в різних форматах, наприклад, у вигляді файлів, електронних повідомлень, сторінок і т.п. Для того, щоб можна було безпомилково отримувати потрібну інформацію й у потрібному форматі використовується рядок символів, що називають універсальний вказівник ресурсу або URL (Universal Resource Locator). Цей рядок однозначно визначає розміщення будь-якого ресурсу в мережі Internet. Саме такий рядок відображається в полі «Адреса» web-браузера.

Універсальний вказівник ресурсу складається з:
<протокол>://<сервер>[:<порт>][/<шлях>][/<файл>[#<розділ>]]
-
Протокол – це набір правил, за якими відбувається обмін інформацією. Наприклад, протокол http – протокол передачі гіпертексту, ftp – протокол передавання файлів.
-
Доменне ім'я або IP-адреса, що дозволяє однозначно ідентифікувати комп'ютер (сервер) у мережі Internet, що містить потрібну інформацію.
-
Шлях складається з імен папок, розділених символом / (слеш), послідовно в які можна «добратися» до потрібної інформації. Наприклад, products/medic/library, тут шукана інформація знаходиться в папці library, що знаходиться в папці medic, що у свою чергу розташовується в середині папки products.
-
Ім'я файлу – файл, що містить потрібну інформацію.
В квадратних дужках вказано необов'язкові елементи URL-адреси:
-
Порт – номер порту по якому клієнт звертається до сервера для встановлення з'єднання, вказується тільки в тому випадку якщо відбувається звернення до нестандартного порту. Порт – логічний канал, яким передаються дані. Кожний протокол має свій порт (наприклад, для протоколу HTTP виділено порт із номером 80, для протоколу FTP – 21, SMTP - 25).
-
Розділ – місце в документі, починаючи з якого він відображається у вікні браузера.
Якщо URL складається лише з двох частин – протоколу й адреси сервера, то буде завантажено домашню (початкову) сторінку.
Пошук інформації
Для того, щоб здійснити доступ до будь-якого ресурсу Web потрібно знати, де він розміщений, тобто треба знати URL ресурсу. Цей URL треба знати наперед або його знайти. Універсальним засобом, який забезпечує пошук потрібних ресурсів, є пошукові системи (сервери).
За способом організації інформації інформаційно-пошукові системи поділяються на 2 види: словникові і тематичні (рубрикатори).
Тематичні пошукові системи (рубрикатори, веб-каталоги) –– це інформаційно-довідкові системи, в яких зберігаються впорядковані за темами посилання на інші сайти (наприклад Open Directory (www.dmoz.org), у якій містяться посилання як на англомовні ресурси, так і на ресурси, подані іншими мовами, зокрема українською – рис.7). Відбір та впорядковування посилань здійснюється вручну редакторами на основі інформації, зібраної на серверах Інтернету. У них використовується ієрархічна (деревоподібна) організація інформації. Каталоги організовуються за темами, і, як правило, містять гіперпосилання для повернення на верхній рівень веб-сайту каталогу, Користувачі каталогів починають пошук, вибираючи загальну тему чи відповідну тематичну категорію, а потім крок за кроком звужують межі пошуку.
Основною перевагою такого засобу пошуку є чітка відповідність змісту сайтів тематиці відповідного розділу. Недоліком є неповне охоплення існуючих у мережі ресурсів, оскільки відслідкувати весь обсяг інформації, наявної в Інтернеті, практично нереально навіть для значної кількості персоналу, які обслуговують сервер. Якщо в одному тематичному каталозі не одержано задовільних результатів, слід звернуться до іншого. Результати пошуку в тематичних каталогах часто бувають дуже різними, оскільки веб-сайти, що включаються до кожної тематичної категорії, обираються вручну людьми, а не машинами.
Список тем, за якими відсортовані посилання на сайти, у каталогах дуже великий. Кожен каталог має свою систему класифікації, проте загальний принцип організації в них приблизно однаковий. Більшість каталогів також мають систему пошуку. Пошук здійснюється у коротких описах сайтів та назвах категорій, а не у вмісті веб-сторінок, як у пошукових системах. Використовувати веб-каталоги доцільно для пошуку інформації на якусь загальну тему.
Рис. 7. Тематична пошукова система Open Directory
Як правило, основною частиною пошукової системи є Пошукова машина (пошуковий движок) - комплекс програм, що забезпечує функціональність пошукової системи. Основними критеріями якості роботи пошукової машини є релевантність (ступінь відповідності запиту і знайденого, тобто доречність результату), повнота бази, облік морфології мови. Індексація інформації здійснюється спеціальними пошуковими роботами.
Словникові пошукові системи (індексні пошукові системи, пошукові сервери) – це могутні автоматичні програмно-апаратні комплекси, перед якими ставиться завдання якнайкраще охопити інформаційний Web-простір і подати його користувачам у зручному вигляді.
Першою пошуковою системою для Всесвітньої павутини був «Wandex», вже не існуючий індекс, який створював «World Wide Web Wanderer» — робот, розроблений Метью Грейєм (англ. Matthew Gray) з Массачусетського технологічного інституту в 1993. Також в 1993 році з'явилася пошукова система «Aliweb», що працює дотепер. Першою повнотекстовою пошуковою системою стала «WebCrawler», запущена в 1994. На відміну від своїх попередників, вона дозволяла користувачам шукати за будь-якими ключовими словами на будь-якій веб-сторінці, відтоді це стало стандартом для всіх основних пошукових систем.
В Інтернеті функціонує декілька сотень словникових пошукових систем. Принцип роботи з такими пошуковими системами ґрунтується на використанні ключових слів. Розшукуючи відомості з деякої теми, користувач повинен дібрати ключові слова, які описують цю тему, і задати їх індексній пошуковій системі як запит. Користувачам такої пошукової системи надається форма, або пульт управління пошуком, для введення ключового слова (слів) або фрази. Пошукова система знаходить у своїх базах даних, які називаються індексами або покажчиками, адреси Web-ресурсів, котрі містять ключові слова, і видає клієнту сторінку з посиланнями на ці ресурси. Така Web-сторінка називається звітом про результати пошуку.
Словникові пошукові системи зазвичай складаються з трьох головних елементів:
-
пошуковий робот (агент, павук, або кроулер)- програма, яка регулярно здійснює сканування максимально можливої кількості доступних їй web-сайтів; індексує всі слова з цих сторінок (разом з адресами URL) і розміщує їх в індекси системи;
-
індекс системи – база даних пошукової системи, де зберігаються перетворені особливим чином текстові складові всіх відвіданих роботом html-сторінок і інших файлів,
-
система пошуку – програма, яка обробляє запит користувача, знаходить в індексі документи, що відповідають критеріям запиту, і виводить список знайдених документів в певному порядку.
Система пошуку є найважливішим елементом всієї системи, оскільки від алгоритмів, покладених в основу її функціонування, безпосередньо залежить якість і швидкість пошуку.
Система пошуку працює так:
-
Отриманий від користувача запит піддається морфологічному аналізу. Генерується інформаційне оточення кожного документа, що міститься в базі (яке і буде згодом відображено у вигляді відповідної текстової інформації на сторінці видачі результатів пошуку).
-
Отримані дані передаються як вхідні параметри спеціальному модулю ранжування. Обробляються дані всіх документів, внаслідок чого для кожного документа розраховується власний рейтинг, що характеризує релевантність запиту, введеного користувачем, і різних складових цього документа, що зберігаються в індексі пошукової системи.
-
Залежно від вибору користувача цей рейтинг може бути скоригований додатковими умовами (наприклад, так званий «розширений пошук»).
-
Далі генерується сніппет, тобто для кожного знайденого документа з таблиці документів витягуються заголовок, коротка анотація, яка найбільше відповідає запиту і посилання на сам документ, причому знайдені слова підсвічують.
-
Отримані результати пошуку передаються користувачеві у вигляді сторінки видачі пошукових результатів.
В ідеальному випадку, розташованими першими у списку будуть документи, що є найбільш релевантними до запиту користувача.
Релевантність – основне поняття при індексації документа в пошукових системах. Релевантність – міра відповідності змісту знайденої сторінки запиту користувача.
Різні пошукові системи використовують різні алгоритми ранжування, однак основними принципами визначення релевантності є:
-
Кількість слів запиту у текстовому вмісті документу (тобто в html-коді).
-
Теги, в яких ці слова розташовуються.
-
Розміщення шуканих слів у документі.
-
Питома вага слів, відносно яких визначається релевантність, у загальній кількості слів документу.
Ці принципи застосовуються всіма пошуковими системами. А наведені нижче використовуються деякими, але достатньо відомими системами (наприклад, AltaVista).
-
Час - як довго сторінка знаходиться в індексі системи. Якщо сайт існує досить довго, це означає, що його власник є досвідченим щодо даної теми, і користувачу більше підійде сайт, що існує вже кілька років, ніж той, який з'явився тиждень тому і стосується цієї ж теми.
-
Індекс цитування - як багато посилань на дану сторінку веде з інших сторінок, що зареєстровані у індексі системи.
Система пошуку виводить ранжований таким чином перелік документів і повертає його користувачу, який зробив запит. Різні пошукові системи вибирають різні способи показу отриманого переліку - деякі відображають лише посилання, інші виводять посилання з декількома першими реченнями документу або заголовок документу разом з посиланням. Коли користувач звертається до посилання на один з документів, цей документ завантажується з сервера, на якому він знаходиться.
Для ефективного пошуку інформації за допомогою пошукової системи пропонуємо деякі практичні поради (представлені правила найбільш загальні; всі відмінності, що стосуються якогось конкретної пошукової системи завжди можна знайти в розділі «Help»):
1. Перш за все необхідно визначитися з метою пошуку і мовою запиту (рос., укр., англ. та ін.). При цьому потрібно концентруватися не тільки на самій меті, але і на тому, що може їй супроводити (ключові слова, спеціальні терміни, дієслова і т. д.). Кількість україномовних сторінок в мережі Інтернет значно нижча, ніж російськомовних і, тим більше, англомовних.
2. Як вибрати пошукову систему? Найпопулярнішою для пошуку українською мовою є Google (www.google.com.ua). Крім того існує українська пошукова система МЕТА (meta.ua), але база її дещо обмежена. Популярними для пошуку російською мовою є Яндекс (www.yandex.ru) і Рамблер ((www.rambler.ru). Українську мову підтримують всі російськомовні системи. Для пошуку іноземними мовами використовують Google (підтримує більше 30-ти мов), який має зручне налаштування, де можна задати: «Шукати сторінки тільки такими мовами».
Іноді для пошуку якоїсь найсвіжішої інформації, корисно використовувати декілька пошукових машин (так званий метапошук).
Пошукові машини розрізняються не тільки підтримуваними мовами. Різниця в способах індексування дає різні результати при пошуку.
3. У запиті слід використовувати ті слова, що найточніше характеризують тему, яка цікавить користувача.
Наприклад: Вам необхідно знайти розклад потягів що проходять через Львів. Як загальний запит можна так і записати в стрічку пошуку: розклад всіх потягів що проходять через львів. Реєстр - тобто рядкові букви або прописні - значення не має.
Проте, по такому запиту, наприклад, Яндекс, знаходить лише розклади поїздів, що проходять через Самару, Тернопіль, але Львова серед результатів пошуку може не бути. Це у жодному випадку не означає, що цієї інформації в базі пошукової системи немає, просто запит був сформульований не дуже вдало.
Будь-яка пошукова система прагне знайти сторінки, на яких знаходиться максимальна кількість слів з запиту, більш того, якщо ці слова ще слідують одне за одним, то такі сторінки будуть виведені першими. Тобто, наприклад, якщо в тексті сторінки зустрічається фраза «розклад всіх потягів, що проходять через Рівне», то за відсутності такої ж фрази «розклад всіх потягів, що проходять через Львів» система визначить, що вони мають 5 спільних слів, тобто з великою вірогідністю сторінка, що містить цю фразу вам підійде, хоча це і не так. Тому потрібно такий запит скоректувати, прибравши всі слова-паразити і залишивши тільки слова, які точно характеризують вашу потребу. У нашому випадку словами-паразитами є слова «всіх, що проходять, через», які можуть зустрічатися на яких завгодно сторінках. Задавши скоректований запит «розклад потягів львів», отримаємо те, що шукали.
4. Пошукова машина сама розташовує результати пошуку по релевантності. Це означає, що найпершими будуть розташовані посилання на документи, в яких слова, що шукаються, знаходяться поряд одне з одним, ближче до початку сторінки або в заголовках. Результати пошуку виводяться посторінково.
5. Іноді необхідно не прибирати зайві слова, а навпаки деталізувати запит, якщо слова, задані для пошуку, дуже загальні, а результати настільки схожі, що легко вибрати потрібне з десятків або сотень сторінок не є можливим.
Наприклад, пошук зі словом «медики» дасть тисячі абсолютно різних документів; пошук зі словами «львівські медики» звузить коло пошуку;
6. Для більшості пошукових серверів має значення послідовність слів у запиті, тому найбільш важливі і характерні терміни треба розміщувати на початку запиту і додавати до них менш значущі терміни.
7. У більшості випадків просто скоректувати запит недостатньо. Необхідно використовувати оператори мови запитів пошукової системи, яку використовуєте. Ці оператори допоможуть знаходити таку інформацію, яку за допомогою простих запитів знайти абсолютно неможливо.
Оператори, спільні для багатьох пошукових систем.
7.1. Для пошуку точної фрази використовується оператор строгої відповідності – подвійні лапки " ". Поєднання слів, які ви вкажете в лапках, враховуватимуться системою як єдине ціле, тобто таким чином ви задаєте порядок слідування слів одне за одним. Наприклад, за запитом «медична інформатика» можна отримати в результатах пошуку сторінки із словами, що згадуються відособлено, тобто на одній сторінці може бути слово «медична», на іншій – «інформатика» і т. д. Конструкція ж «"медична інформатика"» в лапках примушує пошукову систему відкинути всі зайві сторінки і показувати лише ті, на яких ці два слова йдуть одне за одним.
7.2. Оператор оператор обов'язкової відсутності слова "-" (мінус або NOT). Наприклад, якщо потрібно вивести всі журнали, окрім «Acta Medica», потрібно ввести: «медичні журнали –"Acta Medica"».
7.3. Достатньо часто буває корисно, щоб необхідні ключові слова були присутні в межах одного документа. Для цього необхідно використовувати логічний оператор AND. Проте, у всіх пошукових системах це ж можна зробити, поставивши звичайний пропуск (Space). Наприклад, запити: «медичні журнали» і «медичні AND журнали», як правило, дадуть один і той же результат.
7.4. Логічний оператор OR дозволяє знайти хоч би одне слово із запиту. Наприклад, за допомогою запиту: «медичні OR журнали» можна знайти документи, в яких зустрічається або слово медичні, або слово журнали.
7.5. Для пошуку по частині ключового слова використовуються знаки: «*» (позначає довільну частину слова) і «?» (позначення будь-якого символу).
Наприклад: за запитом «Комп'ютер*» отримаємо документи, що містять слова: “Комп'ютер”, ”комп'ютерна”, ”Комп'ютерники” і т. д., а за запитом «к?мпанія» отримаємо документи, що містять слова кампанія або компанія.
7.6. Оператор пошуку синонімів (~): Якщо необхідно знайти тексти, що містять не тільки ключові слова, але і їх синоніми, то можна скористатися оператором "~" перед словом, до якого необхідно знайти синоніми.
7.8. Оператор діапазону (..): Для тих, кому доводиться працювати з цифрами, Google дав можливість шукати діапазони між числами. Для того, щоб знайти всі сторінки, що містять числа в якомусь діапазоні «від - до», треба між цими крайніми значеннями поставити дві крапки (..), тобто, оператор діапозону.
Наприклад: Чисельність населення 1913..1935
7.9. Для пошуку в заголовках в Яндексі потрібно використовувати конструкцію title:( ), таким чином, наш запит може виглядати як: «title:(діагностика пневмонія)».
Для пошуку в заголовках у Google використовується абсолютно інша конструкція – allintitle. Наприклад: «allintitle: діагностика пневмонія»
7.10. Оператор intitle - показує сторінки, в яких тільки те слово, яке стоїть безпосередньо після оператора intitle, міститься в заголовку, а решта всіх слів запиту може бути в будь-якому місці тексту. Якщо поставити оператор intitle перед кожним словом запиту, це буде еквівалентно використанню оператора allintitle. Наприклад: «діагностика intitle: пневмонія».
7.11. Але не тільки заголовки корисні при пошуку потрібної інформації. Значну допомогу може надати і текст посилань. Адже будь-який сайт має певну структуру, тобто якісь посилання, які ведуть на його сторінки або сторінки інших сайтів. Кожне таке посилання має власний опис, за значенням сумісне, а часто і більш інформативне, ніж заголовок самої сторінки, на яку вона веде. Адже і в текстах посилань теж можна шукати.
Наприклад, ми хочемо знайти в мережі файл, наприклад, завантажити останню версію універсального музичного програвача winamp. Оскільки програма ця відома, то, ймовірно, існує немало сайтів, на яких є посилання на сторінку, з якої можна завантажити останню версію winamp. Якщо спробувати пошукати в тексті цих посилань, швидше за все однією з перших в результатах пошуку з'явиться потрібна нам сторінка, оскільки решта всіх посилань веде саме на неї. Для пошуку в описах посилань в Google використовується оператор allinlinks, отже, запит можна сформулювати приблизно так: «allinlinks: winamp download».
7.12. Оператор link - дозволяє побачити адреси всіх сайтів, які посилаються на сторінку, щодо якої зроблено запит. Так, запит link:www.google.com видасть сторінки, в яких є посилання на google.com.
7.13. Як відомо, Google індексує не тільки html сторінки. Якщо, наприклад, знадобилося знайти яку-небудь інформацію у відмінному від html типі файлу, можна скористатися оператором filetype, який дозволяє шукати інформацію в певному типі файлів (html, pdf, doc, rtf...). Наприклад, на запит «медична інформатика filetype:pdf» отримаємо pdf-файли, зі словами медична інформатика.
7.14. Оператор info - дозволяє побачити інформацію, яка відома Google про відповідну сторінку. Наприклад: info:www.wiches.ru; info:www.food.healthy.com
7.15. Оператор site - оператор обмежує пошук конкретним доменом або сайтом. Наприклад, щоб знайти інформацію про професорів Львівського національного медичного університету ім. Данила Галицького можна написати «професор site:www.meduniv.lviv.ua», а щоб отримати сторінки тільки з Польщі достатньо ввести site:.pl
7.16. Якщо запит починається з оператора allinurl, то пошук обмежений тими документами, в яких всі слова запиту містяться тільки в адресі сторінки, тобто в url. Наприклад: «allinurl: med».
7.17. Оператор inurl: Слово, яке розташовано безпосередньо після оператором inurl (без пробілу між ними), буде знайдено тільки в адресі сторінки Інтернету, а решта слів – в будь-якому місці такої сторінки. Наприклад: «inurl:books скачати».
7.18. Оператор related: Цей оператор описує сторінки, які "схожі" на якусь конкретну сторінку. Так, запит related:www.google.com видасть сторінки подібні на Google за тематикою.
7.19. Оператор define: Цей оператор виконує роль своєрідного тлумачного словника, що дозволяє швидко отримати визначення того слова, яке введене після оператора. Наприклад: define:дизентерія.
Стандарти передавання медичної інформації
Відсутність єдиного стандарту медичної інформації – її нагромадження, зберігання, передавання – є однією із перешкод до глобалізації й подальшого розвитку телемедичних технологій. На сьогодні існує біля сотні різних стандартів, які використовуються для маніпуляції з медичною інформацією. У більшості випадків назви стандартів – це абревіатури груп, організацій чи установ, що беруть участь у їх розробці.
Існує велика кількість різних стандартів для передавання всіх видів медичної інформації: ASTM, ASC X12, IEEE/MEDIX, NCPDP, HL7, DICOM і т.п. Тому, є актуальним створення єдиного стандарту обміну медичними даними.
Кожна група з розробки стандартів має деяку спеціалізацію, наприклад, так ASC X12 займається зовнішніми стандартами обміну електронними документами, ASTM Е31.11 – стандартами обміну даними лабораторних тестів, IEEE Р1157 – стандартами обміну медичними даними («МЕDIX»), АCR/NEMA DICOM – стандартами, які пов'язані з обміном зображень і т. д.
У США, в 1996 році Американським національним інститутом стандартів (АNSI) був затверджений національний стандарт обміну медичними даними в електронному вигляді - НL7 (Неalth Level 7). Мета стандарту HL7:
-
полегшення взаємодії комп'ютерних програм в установах охорони здоров'я;
-
обмін зовнішніми даними;
-
стандартизація обміну даними між медичними комп'ютерними програмами, при якій виключається або значно знижується необхідність у опрацюванні та реалізації специфічних програмних інтерфейсів;
-
підтримка електронного обміну інформацією в охороні здоров'я при використанні широкого спектру комунікаційних середовищ.
Перша версія стандарту НL7 була опрацьована в 1987 році. Даний стандарт використовується не лише в США, але і в Австрії, Австралії, Великобританії, Німеччині, Ізраїлі, Канаді, Японії і т.п.
Другим глобальним медичним стандартом є DICOM (Digital Imaging and Communications in Medicine, цифрові зображення і обмін ними в медицині), який був розроблений Американським Коледжем Радіології (American College of Radiology, ACR) і Національною асоціацією виробників електронного устаткування (National Electrical Manufacturers Association, NEMA) в 1985 році.
DICOM - це індустріальний стандарт для передачі радіологічних зображень та іншої медичної інформації між комп'ютерами, що спирається на стандарт Open System Interconnection, розроблений Міжнародною організацією стандартів (International Standards Organization, ISO). Стандарт DICOM описує паспортні дані пацієнта, умови проведення дослідження, положення пацієнта у момент отримання зображення і т. д., для того, щоб надалі було можливо провести медичну інтерпретацію цього зображення.
Стандарт дозволяє організувати цифровий зв'язок між різним діагностичним і терапевтичним устаткуванням, що використовується в системах різних виробників. На основі DICОМ з використанням стандартного протоколу (наприклад TСР/ІР) можуть включатися в єдину телемедичну мережу: базові робочі станції (БРС), комп’ютерні (КТ) і магнітно-резонансні томографи (МРТ), мікроскопи, УЗД-сканери, загальні архіви, сервери і призначені для користувача комп'ютери від різних виробників, розташовані в одному або в різних містах.
Із використанням DICOM можна проводити різні медичні дослідження в територіально-розподілених діагностичних центрах із можливістю збору і опрацювання інформації в потрібному місці.
Стандарт DICOM версії 3.0 призначений для передавання медичних зображень, що отримуються за допомогою різних методів променевої та іншої діагностики (загальна кількість сумісних методів - 29).
Завдання
-
Визначте IP-адресу серверів www.google.com.ua, meduniv.lviv.ua використовуючи команду ping. (Використовується для перевірки IP-адреси призначення і виведення результатів перевірки на екран. При цьому відправляються запити зазначеному вузлу мережі й фіксуються відповіді, час між відправленням запиту й одержанням відповіді, дозволяє визначати двосторонні затримки маршруті й частоту втрати пакетів, тобто побічно визначати завантаженість каналів передачі даних і проміжних пристроїв.) Для цього в вікні Термінал необхідно ввести ping доменне ім’я
-
Визначте до якого класу IP – адрес належать ці адреси.
-
Ввійти на українську сторінку пошукової системи Google.
-
Використовуючи простий пошук, знайти інші пошукові системи. Сформувати ключову фразу українською, англійською та російською мовами. Оцінити результати пошуку.
-
Зайти на довільну знайдену пошукову систему. Провести пошук в цій системі з тією ж ключовою фразою, що й в Google. Порівняти результати пошуку.
-
Знайти документи, які містять одночасно слова хірургія, педіатрія. Записати результати пошуку.
-
Знайти документи, які містять хоча б одне із слів: хірургія, педіатрія. Записати результати пошуку.
-
Знайти документи, які містять слово хірургія але не містять слово педіатрія. Записати результати пошуку.
-
Порівняти результати пошуку при використанні подвійних лапок і без них.
-
Записати і пояснити результати при використанні наведених вище операторів (п.7.5-7.19)
Список літератури:
-
Андерсон К., Минаси М. Локальные сети. Полное руководство: Пер. с англ. - К.: ВЕК+, ЭНТРОП, Спб.: КОРОНА принт, 1999. - 624 с.
-
Бройдо В.Л. Вычислительные системы, сети и телекоммуникации. – СПб.: Питер, 2003. – 688.
-
Гук М. Аппаратные средства локальных сетей: Энциклопедия. - СПб.: Издательство "Питер", 2000. - 576 с.
-
Кульгин М. Технологии корпоративных сетей. Энциклопедия. - СПб.: Издательство "Питер", 2000. - 704 с.
-
Козлова Т.В. Как найти любую информацию в internet . Издательство: НТ Пресс. 2006,
-
Олифер В.Г., Олифер Н.А. Компьютерные сети. Принципы, технологии, протоколы. - СПб.: Издательство "Питер", 2000. - 672 с.
-
Основы сетей передачи данных /В.Г. Олифер, Н.А. Олифер. – М.: ИНТУИТ.РУ “Интернет-Университет Информационных технологий”, 2003 – 248 с.
-
Пятибратов А.П. и др. Вычислительные системы, сети и телекоммуникации: Учебник/ Под редакцией А.П. Пятибратова. – М.: Финансы и статистика, 2001. – 512 с.
-
Райс Л. Эксперименты с локальными сетями микроЭВМ. – М.: Мир, 1990. – 268с.
-
Власов В.Н. Локальные сети. Полное руководство – М.: Просвещение, 1999.– 492 с
-
Волков В.П. IP-протокол. – М.: Просвещение, 1999.– 790 с
-
.Федотов А.М. Введение в Internet.
-
Буров Є. Комп’ютерні мережі. ― Львів: БАК, 1999. ― 468c.
-
Основи сучасних комп’ютерних технологій ./ Под. Ред.Хомоненко. ― СПБ : Корона, 1998. ― 448c.
-
Фафенберг Б. Открой для себя INTERNET. ― К.; M.; СПБ.: Комиздат; Диалектика, 1998. ― 400c.
-
Крол Є. Все об INTERNET. К.: BHV, 1995. ― 320c.
-
Берзин С. INTERNET у вас дома. ― СПб.: BHV, 1997. ― 400c.
-
Левин Д. Р. і др. INTERNET для чайников. ― К.; M.; СПб.: Диалектика, 1998. ― 200c.