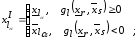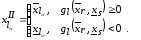Тоді кореляційна функція має вигляд
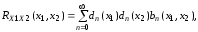
де
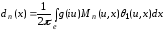 ,
,
bn(x1,x2) – функції, які як і an(x1,x2) залежать лише від кореляційних характеристик процесу на вході і не залежать від нелінійності;
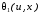 –одновимірна
характеристична функція процесу на
вході нелінійного елементу;
–одновимірна
характеристична функція процесу на
вході нелінійного елементу;
Мn (u, x) – поліном n-го степеня.
Для знаходження кореляційної функції нормального випадкового процесу зручно застосовувати метод похідних. Він полягає у знаходженні похідних кореляційної функції за коефіцієнтом кореляції вхідного нормального процесу, після чого шукана кореляційна функція знаходиться елементарним інтегруванням.
Таким чином, обчислення кореляційної функції після нелінійного статичного перетворення нормального випадкового процесу зводиться до розв’язання звичайного диференціального рівняння k-го порядку вигляду
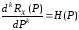 ,
,
де H(P) – права частина рівняння.
Отже,
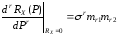 ,
r
=
0,
1,...,
k-1,
,
r
=
0,
1,...,
k-1,
де
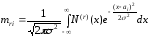 ,i
= 1, 2.
,i
= 1, 2.
Операторний метод моделювання перетворень стохастичних даних дозволяє наближено оцінити закон розподілу вихідного сигналу fy(y), якщо відомі закони розподілу вхідних сигналів fx1(х1), fx2(х2) та їх перший і другий моменти, включаючи взаємну кореляційну функцію RХ1Х2(х1,х2).
Нехай вхідні дані Х1 и Х2 розподілені за законами fx1(1), fx2(2) та їх взаємна кореляційна функція – Rx1x2(). Диференціальний закон розподілу вихідного даного fy(y) може бути знайдений як інтегральний оператор вигляду:
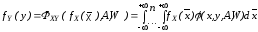
де ФXY – інтегральний оператор, n – кількість вхідних величин, A та W - параметри алгебраїчного й інтегро-диференціального перетворень.
Вираз ядра оператора (1)(x,y) для нелінійної алгебраїчної операції ґрунтується на відомій в теорії випадкових процесів формулі нелінійного перетворення випадкового процесу і рівнянні регресії. Вираз ядра для інтегро-диференціального перетворення ґрунтується на поданні такого перетворення інтегральною сумою (інтегралом Дюамеля).
Методи моделювання перетворень нечітких даних
Нечіткі дані можна поділити на лінгвістичні і числові. Над лінгвістичними даними виконуються переважно множинні операції .
Операції над нечіткими множинами:
а)
Доповненням
нечіткої множини
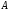 називається нечітка множина
називається нечітка множина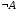 ,
функція належності якої дорівнює:
,
функція належності якої дорівнює:
 ,
,
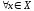 .
.
б)
Перетином
двох нечітких множин
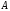 і
і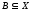 називається нечітка множина
називається нечітка множина ,
функція належності якої дорівнює:
,
функція належності якої дорівнює:
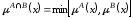 ,
,
 ,
,
в)
Об’єднанням
двох
нечітких множин
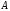 і
і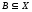 називається нечітка множина
називається нечітка множина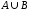 ,
функція належності якої дорівнює:
,
функція належності якої дорівнює:
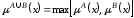 ,
,
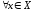 ,
,
Кардинальне число (потужність) нечіткої множини
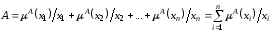
знаходиться
таким чином:
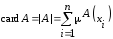 .
.
Інтегральні оператори перетворення щільності розподілу
|
Операція |
Оператор |
Параметри |
|
|
|
|
|
|
|
|
|
|
|
|

 -
область визначення
-
область визначення
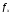
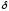 -
дельта-функція Дірака
-
дельта-функція Дірака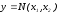
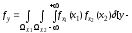
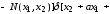
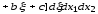
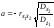
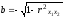
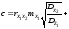
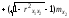
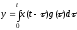
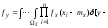

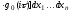
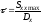
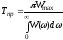
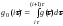
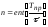
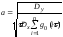
Принципи узагальнення математичних операцій на нечіткі дані були розроблені для того, щоб для нечітких чисел можна було застосовувати арифметичні та алгебраїчні операції, які використовуються для звичайних чітких даних.
Базовий принцип узагальнення – це принцип узагальнення Заде, який полягає в наступному.
Якщо
задана функція від k
змінних y=g(x1,x2,..xk)
і аргументи
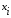 - нечіткі числа
- нечіткі числа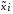 з носіямиsupp
з носіямиsupp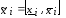 ,
,
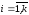 то нечітке число
то нечітке число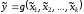 визначається в такий спосіб :
визначається в такий спосіб :
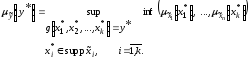
Алгоритм принципу узагальнення Заде.
1. Фіксується
значення .
.
2. Знаходяться всі
k-ті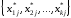 ,
що задовольняють умови:
,
що задовольняють умови:
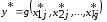 ,
,
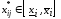 ,
,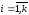 ,
,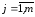 .
.
Визначається ступінь належності елемента
 нечіткому числу
нечіткому числу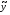 за формулою:
за формулою:
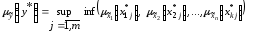 .
.
4.Перевіряється
умова чи взяті всі елементи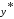 .
Якщо "так", то переходять до кроку
5, інакше фіксують нове значення
.
Якщо "так", то переходять до кроку
5, інакше фіксують нове значення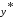 і переходять до кроку 2.
і переходять до кроку 2.
5.Кінець.
Основні арифметичні операції над нечіткими числами у відповідності до принципу узагальнення мають вигляд:
додавання
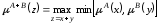 ,
,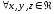
віднімання
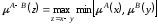 ,
,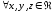
множення
 ,
,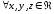
ділення
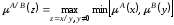 ,
,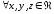
Якщо y=g(x1,x2,..xk)- функція відkнечітких аргументів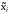 ,
кожний із яких задається функцією
належності вnточках універсальної
множини
,
кожний із яких задається функцією
належності вnточках універсальної
множини
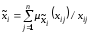 ,
,
 ,
,
тo
для визначення нечіткого числа
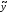 за принципом узагальнення Заде
необхідно
перебрати
за принципом узагальнення Заде
необхідно
перебрати
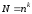 варіантів.
варіантів.
Для вдосконалення
принципу узагальнення Заде ввели принцип
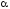 -рівневого
узагальнення.
-рівневого
узагальнення.
Якщо задана функція
від нечітких аргументів y=g(x1,x2,..xk),
у якої нечіткі числа подані у вигляді
розкладання на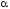 -рівневі
множини:
-рівневі
множини:
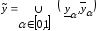 ,
,
 ,
,
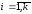 .
.
то
для будь-якого
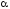 -рівня
значення функції обчислюється за
формулами:
-рівня
значення функції обчислюється за
формулами:
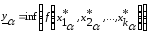 ;
;
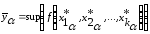 ,
,
де
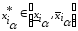 ,
,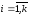 .
.
У LR формі
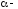 рівень
множиниА
згідно з
рівень
множиниА
згідно з
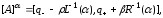
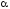 [0,1].
[0,1].
При застосуванні
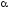 -рівневого
принципу узагальнення необхідно
розв’язувати оптимізаційну задачу:
дана функція відkзміннихy=g(x1,x2,..xk),
у якій аргументи
-рівневого
принципу узагальнення необхідно
розв’язувати оптимізаційну задачу:
дана функція відkзміннихy=g(x1,x2,..xk),
у якій аргументи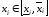 ,
,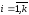 і потрібно знайти такі значення аргументів
і потрібно знайти такі значення аргументів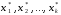 ,
що забезпечують максимальне
,
що забезпечують максимальне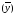 і мінімальне
і мінімальне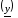 значення функції y=g(x1,x2,..xk)на області визначення
значення функції y=g(x1,x2,..xk)на області визначення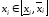 ,
, .
При цьому для спрощення розв’язування
задачі вводять ряд обмежень, властивих
реальним моделям, що дозволяє одержати
простий алгоритм.
.
При цьому для спрощення розв’язування
задачі вводять ряд обмежень, властивих
реальним моделям, що дозволяє одержати
простий алгоритм.
Припустимо, що функція y=g(x1,x2,..xk)відповідає таким обмеженням:
Область зміни будь-якого аргументу неперервна.
На області визначення функція диференційована.
Множину аргументів
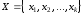 можна подати об’єднанням не більше,
ніж трьох підмножин
можна подати об’єднанням не більше,
ніж трьох підмножин
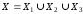 причому:
причому:
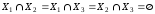 ;
;
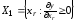
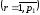 ;
;

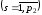 ;
;
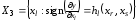 ;
;
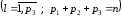 .
.
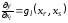 - знакозмінна
функція і для усіх
- знакозмінна
функція і для усіх
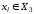 ,
знак похідної
,
знак похідної не залежить від
не залежить від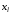 тобто :
тобто :
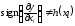 .
.
Більш досконалим
є модифікований принцип узагальнення,
за яким нечітким узагальненням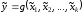 називається число
називається число
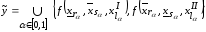 ,
,
де
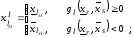
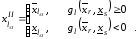
Методику нечіткого узагальнення аналітичних моделей можна подати у такому алгоритмі:
1.Подати вихідну математичну модель у вигляді функції
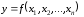 .
.
2.Визначити
границі зміни аргументів: ,
,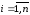 .
.
3.Знайти
часткові похідні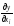
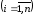 .
.
4. Позначити:
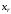 - аргументи, для
яких
- аргументи, для
яких
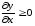 на всій області визначення;
на всій області визначення;
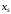 -
аргументи, для яких
-
аргументи, для яких
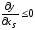 на всій області визначення;
на всій області визначення;
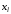 -
аргументи, для яких
-
аргументи, для яких
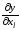 є знакозмінною функцією і її знак
залежить тільки від значень
є знакозмінною функцією і її знак
залежить тільки від значень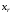 аргументів
аргументів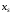 і
, тобто
і
, тобто
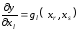 .
.
5. Записати нечітку
математичну модель
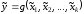 ,
у вигляді:
,
у вигляді:
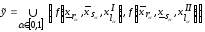
де