

Так: перейти на крок 11. Ні: перейти на крок 13.
Крок 11.
Чи виконується нерівність
![]() ?
?
Так: закінчення пошуку: немає просування до рішення. Перейти на крок 13.
Ні: перейти на крок 12.
Крок 12. Покласти k = k + 1. Перейти на крок 3.
Крок 13. Останов.
Варто відмітити, що в процесі одновимірного пошуку необхідно, по можливості, уникати точних обчислень, тому що експерименти показують, що на виконання операцій пошуку уздовж прямої витрачається дуже значна частина загального часу обчислень.
У вищеописаному узагальненому градієнтному алгоритмі можна використовувати різні градієнтні методи шляхом визначення відповідних напрямків пошуку на кроці 6. Визначаючи відповідним чином s(wk), можна трансформувати розглянутий узагальнений градієнтний алгоритм практично в будь-який градієнтний алгоритм навчання БНМ, що дозволяє істотно спростити розробку нейромережних систем без жорсткої прив'язки до визначеного градієнтного алгоритму.
Розглянемо деякі окремі випадки узагальненого градієнтного алгоритму.
Метод Коші (метод найшвидшого спуска, у навчанні нейронних мереж відомий, як алгоритм зворотного поширення помилки першого порядку або Backpropagation) полягає в реалізації правила (крок 6 узагальненого градієнтного алгоритму):
![]() .
.
Позначивши
поточний градієнт
![]() ,
,
одержимо: s(wk) = – γkgk, де γk – швидкість навчання.
Величина γ або покладається постійною, і тоді звичайно послідовність wk збігається в довкілля оптимального значення w, або вона є спадною функцією часу так, як це робиться в стохастичних алгоритмах оптимізації та адаптації.
Дана процедура може виконуватися доти, поки значення керованих змінних не стабілізуються або поки помилка не зменшиться до прийнятного значення. Слід зазначити, що дану процедуру характеризує повільна швидкість збіжності та можливість влучення в локальні мінімуми функціонала.
Для методу Ньютона або алгоритму зворотного поширення помилки другого порядку крок 6 узагальненого градієнтного алгоритму має вигляд:
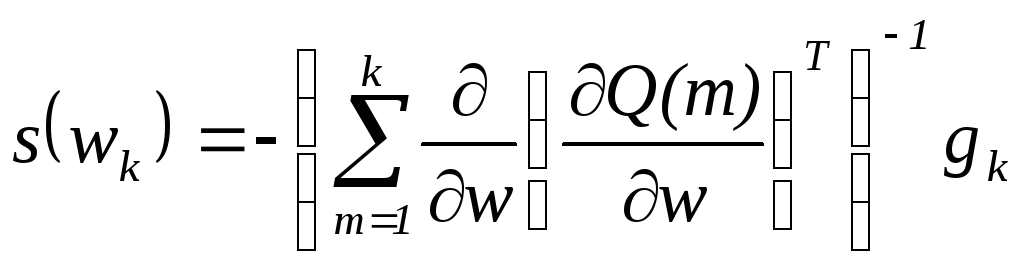 .
.
Алгоритми спряжених градієнтів представляють собою підклас методів, які квадратично збігаються. Для алгоритмів спряжених градієнтів крок 6 узагальненого градієнтного алгоритму має вигляд:
s(wk) = –gk + k s(wk-1).
У більшості алгоритмів спряжених градієнтів розмір кроку коректується при кожній ітерації, на відміну від інших алгоритмів, де швидкість, що навчається, використовується для визначення розміру кроку. Різні версії алгоритмів спряжених градієнтів відрізняються способом, за яким обчислюється константа β.
Для алгоритму спряжених градієнтів Флетчера-Рівса правило обчислення константи β має вигляд:
 ,
,
де β – відношення квадрата норми поточного градієнта до квадрата норми попереднього градієнта.
В узагальненому градієнтному алгоритмі відсутня процедура повернення до початкової ітерації для методу Флетчера-Рівса, але разом з тим тести, включені в алгоритм, забезпечують виявлення будь-яких труднощів, асоційованих з необхідністю повернення при розрахунках по методу сполучених градієнтів.
Для алгоритму спряжених градієнтів Полака - Рібьера правило обчислення константи β має вигляд:
 ,
,
де β – внутрішній добуток попередньої зміни в градієнті та поточного градієнта, поділений на квадрат норми попереднього градієнта.
Алгоритм Левенберга - Марквардта вимагає наявності інформації про значення похідних цільової функції. В алгоритмі Левенберга-Марквардта використовується метод зворотного поширення помилки першого порядку, щоб обчислити якобіан J цільової функції відносно ваг і порогів мережі.
Для алгоритму Левенберга-Марквардта крок 6 узагальненого градієнтного алгоритму має вигляд:
s(wk) = – [Hk + ηI]-1gk,
де H = JTJ; J – якобіан; gk = JTe – поточний градієнт; e – вектор помилок; η – скаляр; I – одинична матриця.
Адаптивне значення η збільшується в η+ разів доти, поки значення цільової функції не зменшиться. Після чого зміни вносяться в мережу і η зменшується в η – разів.