

SQLServer08_DM_Nesterov
.pdfРис.5.138. Три модели в одной структуре
После того, как структура и модели созданы и обработаны, рекомендуется выяснить, какая из моделей дает более точный прогноз. Для этого можно использовать диаграммы точности (англ. Mining Accuracy Chart), а также зарезервированное при создания структуры тестовое множество вариантов, которое не задействовалось при обучении модели.
Перейдем на вкладку Mining Accuracy Chart (рис.5.139). Там можно отметить, для каких моделей будут строиться диаграммы, и какие данные будут использоваться в процессе тестирования. Можно использовать набор данных, зарезервированный в модели или в структуре, а также внешний набор данных. Первые два варианта будут отличаться, если при создании модели задавался фильтр вариантов. Проверочный набор в модели будет включать только варианты, соответствующие фильтру, а проверочный набор в структуре фильтр не учитывает. В нашем случае фильтрация не использовалась, так что эти варианты равнозначны.
Кроме того, для дискретного целевого атрибута можно выбрать предсказываемое значение (Predict Value, рис.5.139). В рассматриваемом примере нам более интересно значение «1», т.е. клиент, который сделает покупку.
231

Рис.5.139. Предварительные настройки для оценки точности модели
Выбираем тестовый набор для структуры, Predict Value = 1, и переходим на вкладку Lift Chart. Стандартная диаграмма точности, называемая диаграммой роста (англ. Lift Chart), будет выглядеть, как представлено на рисунке 5.140. Верхняя линия соответствует идеальной модели; линия, идущая под наклоном 45% – случайному выбор. У нас в тестовом наборе примерно 50% вариантов имеют значение BikeBuyer равное 1. И можно представить, что каждая модель согласно своему прогнозу формирует упорядоченный по степени близости к искомому значению список вариантов. У идеальной модели все искомые варианты будут в первых 50 процентах списка. У случайной модели – в первой половине списка будет только 50% клиентов, сделавших покупку. Чем ближе результат к идеальной модели, тем точнее прогноз. В нашем примере наилучший результат дает модель, использующая алгоритм деревьев принятия решений (Decision Trees).
232

Рис.5.140. Диаграмма роста
Рис.5.141. Диаграмма роста, когда целевое значение не выбрано
233

Если не указывать целевое значение (т.е. на рис.5.139 не ставить Predict Value = 1), то диаграмма точности будет выглядеть, как представлено на рис.5.141. На ней тоже видно, что модель vTargetMail_DT дает более точный прогноз.
Чтобы получить стоимостную оценку качества модели, можно использовать диаграмму роста прибыли (на рис.5.140 в выпадающем списке Chart Type выбрать Profit Chart). BI Dev Studio запросит дан-
ные об общем числе вариантов – Population (например, это число клиентов, которым собираемся провести рассылку), ограничении на суммарную стоимость – Fixed Cost (например, бюджет рекламной рассылки), затратах на единицу – Individual Cost (например, стоимость отправки одного письма с рекламным предложением), выручке от од-
ного покупателя – Revenue per Individual (рис.5.142).
Рис.5.142. Настройки для построения диаграммы роста прибыли
Полученная диаграмма позволяет понять, какое число предложений надо разослать для получения максимальной прибыли. Будем считать, что на основе прогнозов каждой модели сформирован список клиентов, упорядоченный по убыванию прогнозируемой вероятности покупки клиентом велосипеда. Из диаграммы роста прибыли (рис. 5.143) видно, что при использовании модели vTargetMail_DT, максимум прибыли достигается, когда предложения отправлены примерно 64% клиентов, начиная с верхней части списка.
Задание 4. По аналогии с описанием, проведите анализ точности полученных моделей. Прокомментируйте результаты.
234

Рис.5.143. Диаграмма роста прибыли
5.14. РАБОТА 14. ПРОСМОТР МОДЕЛЕЙ ИНТЕЛЛЕКТУАЛЬНОГО АНАЛИЗА (ДЕРЕВЬЯ РЕШЕНИЙ,
УПРОЩЕННЫЙ АЛГОРИТМА БАЙЕСА, НЕЙРОННЫЕ СЕТИ). НАПИСАНИЕ «ОДНОЭЛЕМЕНТНЫХ» ПРОГНОЗИРУЮЩИХ ЗАПРОСОВ
Данная лабораторная работа посвящена более подробному знакомству с содержимым модели и написанию прогнозирующих запросов. В среде BI Dev Studio откроем созданную в ходе выполнения предыдущих лабораторных работ базу данных аналитических служб. В ней откроем в редакторе структуру vTargetMail_Structure2, которую создавали в работе № 13. Перейдем на вкладку Mining Model Viewer и в выпадающем списке Mining Model выберем модель vTargetMail_NB, основанную на использовании упрощенного алгоритма Байеса (рис.5.144).
235

Рис.5.144. Диаграмма модели, основанной на упрощенном алгоритме Байеса
После проведения обработки, модель интеллектуального анализа данных хранит метаданные о себе, собранную статистику, а также закономерности, выявленные алгоритмом интеллектуального анализа. Способ описания закономерностей зависит от используемого алгоритма.
Среда BI Dev Studio предоставляет инструменты, позволяющие ознакомиться с содержимым модели. В частности, это представленные на рисунке 5.144 диаграммы (вид диаграммы зависит от используемого алгоритма). В случае упрощенного алгоритма Байеса можно использовать диаграмму типа «сеть зависимостей» (Dependency Network) для того, чтобы увидеть, насколько значения одних атрибутов влияют на значения других.
Если на диаграмме (рис.5.144) щелчком мыши выделить целевой атрибут (Bike Buyer) и передвинуть вниз «бегунок» All Links в левой части экрана, то можно увидеть, что в наибольшей степени на решение о приобретении велосипеда влияет число машин в собственности у клиента (рис.5.145).
236
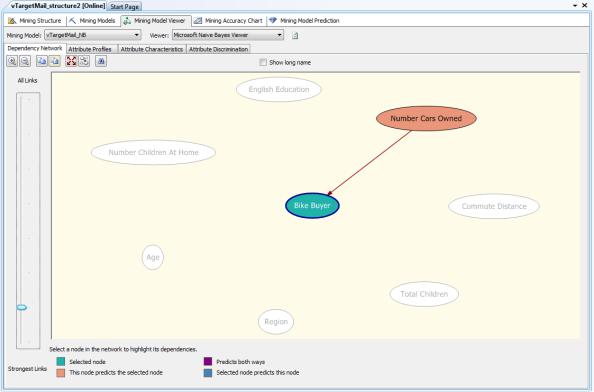
Рис. 5.145. Работа с диаграммой типа «сеть зависимостей»
Вкладка Attribute Discrimination позволяет увидеть, какие значения входных атрибутов в наибольшей степени соответствуют тому или иному значению выходного (рис.5.146). Из представленных на рисунке данных можно сделать вывод, что отсутствие машины у клиента с большой вероятностью приведет к покупке велосипеда. Похожие диаграммы мы видели в Excel, в ходе выполнения лабораторной № 2, посвященной использованию инструмента «Анализ ключевых факторов влияния».
Еще более подробно ознакомиться с содержимым модели позволяет средство просмотра Microsoft Generic Content Tree Viewer. Если открыть в нем модель vTargetMail_NB можно увидеть содержимое модели в виде иерархии узлов. На рисунке 5.147 представлено содержимое узла, соответствующее ситуации, когда у клиента нет машин (атрибут Number Cars = 0). Из 2977 вариантов, в которых это значение встречается, 1889 клиентов купили велосипед (это примерно 63%) и 1088 – не купили.
237

Рис.5.146.Сравнение наборов значений входных атрибутов, соответствующих выбранным значениям выходного атрибута
Рис.5.147. Просмотр модели в Microsoft Generic Content Tree Viewer
238

Для модели vTargetMail_DT, использующей алгоритм деревьев принятия решений, первой показывается одноименная диаграмма Decision Tree (рис.5.148). На ней отображаются узлы построенного дерева, а выбор любого конечного узла позволяет понять, как алгоритм будет строить прогноз для соответствующей комбинации значений входных параметров. Например, на рисунке показано, что для клиента имеющего две машины, проживающего в регионе Pacific (Тихоокеанский), возрастом менее 43 лет, будет сделан положительный прогноз относительно покупки им велосипеда, т.к. из 103 подобных клиентов в обучающей выборке 84 – сделали покупку.
Также для моделей на основе алгоритма деревьев принятия решения можно получить рассмотренные выше диаграммы типа «сеть зависимостей».
Для основанной на алгоритме нейронных сетей модели vTargetMail_DT будет отображаться диаграмма попарного сравнения вариантов, аналогичная представленной на рисунке 5.146.
Рис. 5.148. Диаграмма Decision Tree
239

Задание 1. Проведите анализ содержимого всех моделей, построенных в ходе предыдущей лабораторной. Опишите полученные результаты.
Построение прогнозов
Вернемся к модели vTargetMail_DT, которая как мы выяснили в работе № 13, дает наиболее точный прогноз. Попробуем сейчас построить прогноз для отдельного варианта. Это можно представить как попытку узнать, купит ли человек, заполнивший анкету, велосипед или нет.
Перейдем на вкладку построителя запросов Mining Model Prediction. В окне Mining Model нажмите кнопку Select Model и выберите в структуре vTargetMail_Structure2 модель vTargetMail_DT (рис.5.149).
Рис.5.149 Выбор модели, используемой для построения прогноза
В связи с тем, что прогноз мы хотим построить для одного варианта, значения атрибутов которого будем вводить вручную, в контекстном меню выберем соответствующий тип запроса – Singleton
240