

SQLServer08_DM_Nesterov
.pdfРис.5.128. Результат успешной обработки структуры
После изменения настройки, повторно запускаем полную обработку структуры, которая сейчас должна завершиться успешно
(рис.5.128).
Задание 1. По аналогии с рассмотренным примером создайте структуру и модель интеллектуального анализа.
После обработки можно открыть в редакторе структуру и на вкладке Mining Model Viewer ознакомиться с построенной моделью (рис.5.129). Инструмент Cluster Profiles (рис.5.130) позволяет увидеть характеристики выявленных кластеров. Например, кластер 4 объединяет клиентов старшего возраста (средний возраст около 63 лет), ра-
ботающих в сфере управления (EnglishOccupation=‘Management‘).
Здесь же можно переименовать кластеры, провести детализацию (опция Drill Through в контекстном меню), чтобы увидеть записи, относимые к каждому кластеру.
221
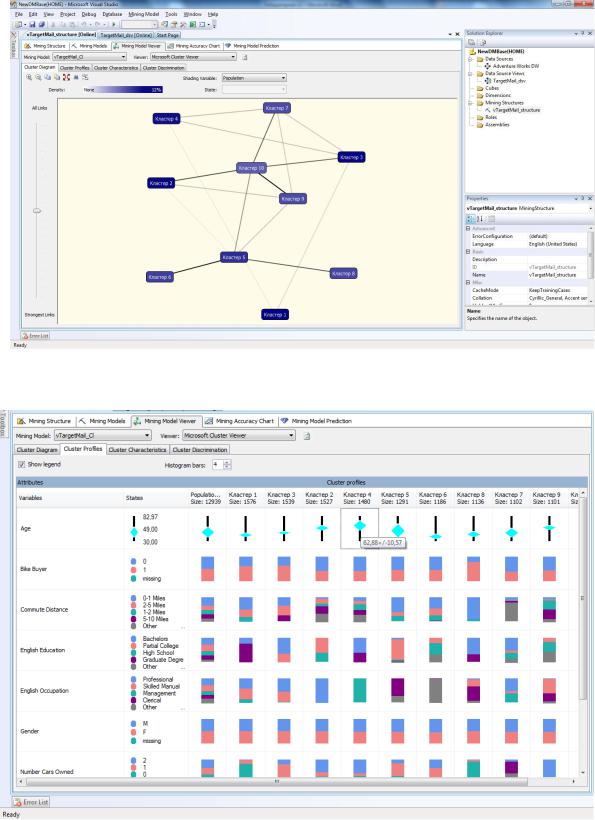
Рис. 5.129. Просмотр модели – диаграмма кластеров
Рис.5.130. Просмотр характеристик выявленных кластеров
222
Задание 2. Ознакомьтесь с результатами кластеризации. Охарактеризуйте полученные кластеры. Посмотрите, все ли добавленные в модель столбцы учитывались в процессе кластеризации или некоторые были проигнорированы (для этого посмотрите данные на вкладке Mining Models).
Получение номера кластера
Теперь рассмотрим, как можно получить список клиентов с идентификаторами присвоенных им кластеров. Для этого можно использовать конструкцию прогнозирующего соединения (PREDICTION JOIN) и функцию Cluster().
В среде BI Dev Studio в окне просмотра модели перейдем на вкладку Mining Model Prediction. В окне Select Input Tables нажмем кнопку Select Case Table и укажем, откуда брать варианты: представление источника данных TargetMail_dsv и в нем vTargetMail. После этого надо выбрать список отображаемых в результатах запроса атрибутов. Пусть это будет ключ клиента (Customer Key), его имя, отче-
ство или второе имя и фамилия (FirstName, Middle Name, LastName) и
регион проживания (Region). Также нам нужно получить значение функции Cluster (рис.5.131). Когда запрос сформирован в конструкторе, можно переключиться к представлению результатов (кнопка с изображением таблицы на панели инструментов окна Mining Model Prediction). Результат выполнения прогнозирующего запроса приведен на рис.5.132, а его код представлен ниже.
Задание 3. По аналогии с рассмотренным примером, выведите список клиентов с идентификаторами кластеров, к которым их относит модель.
Воспользуйтесь функцией ClusterProbability, чтобы получить оценку вероятности того, что данный вариант находится в указанном кластере.
223
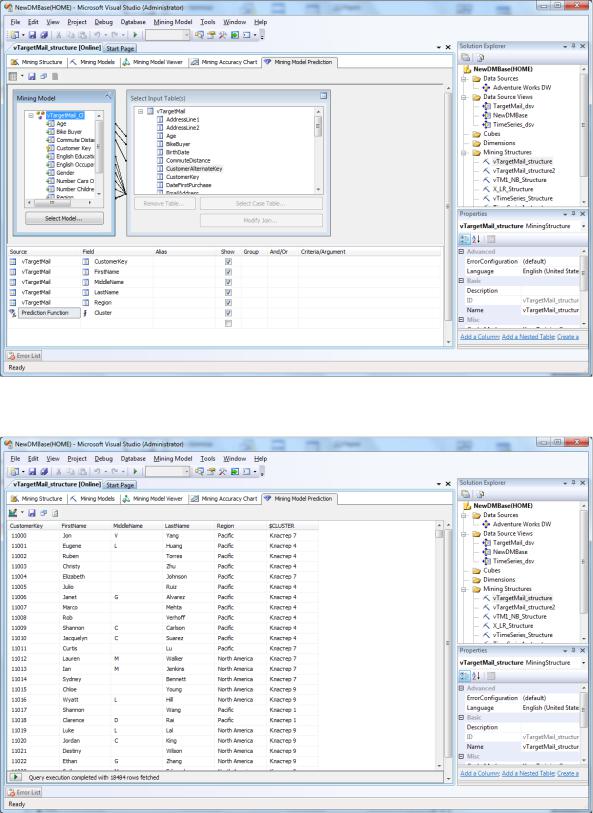
Рис.5.131. Конструктор прогнозирующих запросов
Рис.5.132. Результат выполнения запроса
224
SELECT t.[CustomerKey],t.[FirstName], t.[MiddleName], t.[LastName], t.[Region], Cluster()
From [vTargetMail_Cl] PREDICTION JOIN OPENQUERY([Adventure Works DW],
'SELECT [CustomerKey], [FirstName], [MiddleName], [LastName], [Region], [Gender], [YearlyIncome], [TotalChildren], [NumberChildrenAtHome], [EnglishEducation], [EnglishOccupation], [NumberCarsOwned],[CommuteDistance], [Age], [BikeBuyer]
FROM [dbo].[vTargetMail]') AS t
ON
[vTargetMail_Cl].[Gender] = t.[Gender] AND [vTargetMail_Cl].[Yearly Income]=t.[YearlyIncome] AND [vTargetMail_Cl].[Total Children] = t.[TotalChildren] AND
[vTargetMail_Cl].[Number Children At Home] = t.[NumberChildrenAtHome] AND
[vTargetMail_Cl].[English Education] = t.[EnglishEducation] AND
[vTargetMail_Cl].[English Occupation] = t.[EnglishOccupation] AND
[vTargetMail_Cl].[Number Cars Owned] = t.[NumberCarsOwned] AND
[vTargetMail_Cl].[Commute Distance] = t.[CommuteDistance] AND
[vTargetMail_Cl].[Region] = t.[Region] AND [vTargetMail_Cl].[Age] = t.[Age] AND [vTargetMail_Cl].[Bike Buyer] = t.[BikeBuyer]
225
5.13. РАБОТА 13. ЗАДАЧА КЛАССИФИКАЦИИ. СОЗДАНИЕ СТРУКТУРЫ И МОДЕЛЕЙ
ИНТЕЛЛЕКТУАЛЬНОГО АНАЛИЗА. СРАВНЕНИЕ ТОЧНОСТИ МОДЕЛЕЙ
Данная лабораторная работа посвящена решению задачи классификации и оценке точности прогнозов, получаемых с использованием разных алгоритмов.
Пусть, используя имеющиеся данные компании Adventure Works, необходимо определить, купит ли новый клиент велосипед или нет. Это пример задачи классификации, которую можно решить с помощью разных алгоритмов: упрощенного алгоритма Байеса, нейронных сетей, деревьев решений. Рассмотрим, как для одной структуры можно создать несколько моделей и оценить качество формируемого ими прогноза.
По аналогии с заданиями предыдущей лабораторной создадим структуру интеллектуального анализа и модель, использующую упрощенный алгоритм Байеса. Назовем структуру – vTargetMail_structure2, модель на основе алгоритма Naïve Bayes
(упрощенный алгоритм Байеса) – vTargetMail_NB. Данные будем брать, как и раньше, из представления vTargetMail, используя созданные в предыдущих лабораторных источник данных (Data Source) и представление источника данных (Data Source View).
При определении структуры и модели в перечне столбцов отметим ключевой атрибут – CustomerKey и предсказываемое (англ. Predictable) значение – BikeBuyer (1 – признак того, что клиент купил велосипед; 0 – не купил). Чтобы определить, какие атрибуты оказывают на него влияние, воспользуемся кнопкой Suggest и отметим предлагаемые столбцы, в наибольшей степени влияющие на целевой (рис. 5.133). Наши знания о предметной области подсказывают, что адрес и имя стоит исключить, а включив в список EnglishEducation, можно исключить FrenchEducation и SpanishEducation, т.к. это то же самое,
226
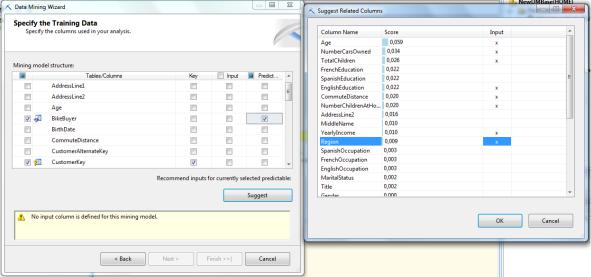
только на другом языке. Таким образом, в качестве входных (Input) атрибутов будем использовать:
-Age (возраст клиента);
-NumberCarsOwned (число машин в собственности);
-TotalChildren (общее число детей);
-EnglishEducation (образование);
-CommuteDistance (расстояние до работы);
-NumberChildrenAtHome (число детей дома);
-YearlyIncome (годовой доход);
-Region (регион проживания).
Рис.5.133. Выбор столбцов в соответствии с рекомендациями
Data Mining Wizard
На рисунке 5.134 представлены типы данных, автоматически установленные для столбцов. Обратите внимание, что для некоторых столбцов установлен тип содержимого Discretized. Связано это с тем, что выбранный для модели упрощенный алгоритм Байеса не работает с числовыми атрибутами с типом содержимого Continuous и для этих столбцов будет проведена дискретизация значений. Такой тип содержимого корректен в случае атрибутов Age и YearlyIncome. Но для ат-
рибутов BikeBuyer, NumberCarsOwned, NumberChildrenAtHome, To-
227
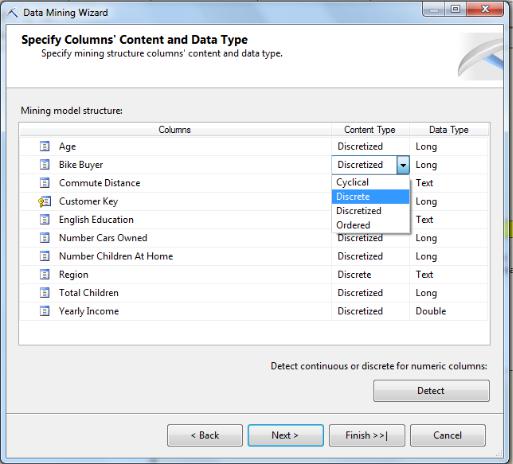
talChildren надо сменить тип на Discrete – мы знаем, что множество возможных значений этих атрибутов невелико.
Рис.5.134. Уточнение типов содержимого
В следующем окне для целей тестирования, в соответствии с установкой по умолчанию, резервируем 30% записей.
Таким образом, мы создали структуру интеллектуального анализа данных. Если открыть структуру в редакторе и перейти на вкладку Mining Models можно удостовериться, что создана и модель (рис.5.135). Обратите внимание, что атрибут BikeBuyer отмечен как предсказываемый (PredictOnly). Раскрывающийся список напротив названия столбца позволяет сменить данную настройку.
Если какой-то атрибут надо исключить из рассмотрения при обучении модели, смените значения Input на Ignore (игнорировать).
228
Рис.5.135. Созданная структура, включающая одну модель
Воспользовавшись контекстным меню (рис.5.136) можно получить доступ к параметрам используемого моделью алгоритма (рис.5.137). Также можно настроить фильтр (пункт Set Model Filter… на рис.5.136), тогда для анализа будут использоваться только варианты, соответствующие условиям фильтрации. Например, это позволяет исключить из рассмотрения клиентов из какого-то региона, который, как мы считаем, существенно отличается от остальных.
Рис.5.136. Контекстное меню позволяет просмотреть и изменить параметры алгоритма
229
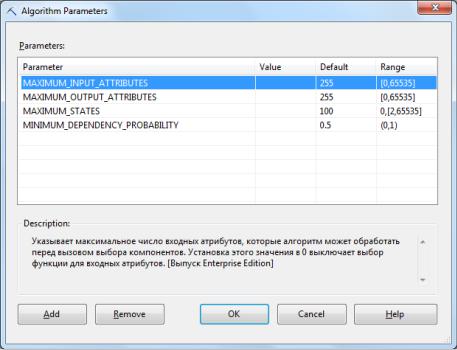
Рис.5.137. Параметры упрощенного алгоритма Байеса для созданной модели
Воспользовавшись пунктом контекстного меню New Mining Model… (рис.5.136) можно создавать модели, основанные на других алгоритмах интеллектуального анализа, но аналогичные исходной по набору атрибутов.
Задание 1. Создайте структуру и модель интеллектуального анализа, как это было описано выше.
Задание 2. В той же структуре создайте две дополнительные модели, одна из которых (назовем ее vTargetMail_DT) будет исполь-
зовать алгоритм Microsoft Decision Trees, другая (vTargetMail_NN) - Microsoft Neural Network. В итоге, должен получиться результат, представленный на рисунке 5.138. Ознакомьтесь с параметрами созданных моделей.
Задание 3. Выполните обработку структуры и всех ее моделей (полную обработку структуры).
230