

Погрешности значения функции
При
вычислении значения функции
![]() в точке
в точке![]() (считаем
(считаем![]() приближенным значением точного числа
приближенным значением точного числа![]() )
возникают погрешности – предельная
абсолютная
)
возникают погрешности – предельная
абсолютная![]() и предельная относительная
и предельная относительная![]() .
Выразим эти погрешности через погрешности
числа
.
Выразим эти погрешности через погрешности
числа![]() (будем полагать, что функция
(будем полагать, что функция![]() дифференцируема в точке
дифференцируема в точке![]() ).
).
Так
как функция
![]() дифференцируема в точке
дифференцируема в точке![]() ,
то
,
то
![]() ,
(4.1)
,
(4.1)
где
![]() мало при малом
мало при малом![]() (иными словами, слагаемым
(иными словами, слагаемым![]() в формуле (4.1) можно пренебречь, если
в формуле (4.1) можно пренебречь, если![]() мало).
мало).
Учитывая
равенство (4.1), истинная абсолютная
погрешность
![]() будет оцениваться неравенством
(приближенным)
будет оцениваться неравенством
(приближенным)
![]() ,
,
откуда по определению предельной абсолютной погрешности
![]() . (4.2)
. (4.2)
Итак,
предельная
абсолютная погрешность значения функции
в точке
![]() (
(![]() – приближенное число) равна произведению
модуля производной этой функции в точке
– приближенное число) равна произведению
модуля производной этой функции в точке![]() на предельную абсолютную погрешность
числа
на предельную абсолютную погрешность
числа![]() .
.
Соответственно
предельная относительная погрешность
![]() вычисляется следующим образом
вычисляется следующим образом
![]() =
= . (4.3)
. (4.3)
Найдем с помощью формул (4.2), (4.3) погрешности значений основных элементарных функций.
Пусть
![]() (
(![]() – действительное число). Тогда
– действительное число). Тогда
![]() ,
,
![]() .
.
В
частности при
![]() :
:![]() .
.
Пусть
![]() .
Тогда
.
Тогда
![]() ,
,
![]() .
.
Пусть
![]() .
Тогда
.
Тогда
![]() ,
,
![]() .
.
В
частности, если
![]() ,
то
,
то![]() .
.
Аналогично определяются погрешности значений других основных элементарных функций (см. таблицу 4.1).
Таблица 4.1.
|
№ |
|
|
|
|
1 |
|
|
|
|
2 |
|
|
|
|
3 |
|
|
|
|
4 |
|
|
|
|
5 |
|
|
|
|
6 |
|
|
|
|
7 |
|
|
|
|
8 |
|
|
|
|
9 |
|
|
|
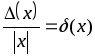
Пример
4.1. Дана
функция
![]() .
Протабулировать ее на отрезке
.
Протабулировать ее на отрезке![]() (считать
(считать![]() ),
разбив его на
),
разбив его на![]() равных частей (все расчеты проводить с
4 знаками после запятой). Вычислить
предельные абсолютные, относительные
погрешности значений функции в узлах
табулирования.
равных частей (все расчеты проводить с
4 знаками после запятой). Вычислить
предельные абсолютные, относительные
погрешности значений функции в узлах
табулирования.
Решение:
Протабулировать функцию
![]() на отрезке
на отрезке![]() с постоянным шагом
с постоянным шагом![]() означает составить таблицу значений
означает составить таблицу значений![]() ,
,![]() (точки
(точки![]() называются узлами табулирования), где
называются узлами табулирования), где
![]() . (4.4)
. (4.4)
В
нашем случае
![]() ,
,![]() ,
,![]() ;
узлы определяются следующим образом:
;
узлы определяются следующим образом:
![]() . (4.5)
. (4.5)
Вычислим значения функции в узлах табулирования (4.5):
![]() .
.
Имеем
![]() ,
,![]() ;
;
![]() ,
,
![]() 3,3261,
3,3261,
![]() ,
,
![]()
и так далее.
Все вычисления значения функции в узлах табулирования заполняем в таблицу 4.2.
Учитывая
формулы (4.2), (4.3), находим погрешности в
узлах (4.5) (при этом число
![]() можно считать точным, а тогда
можно считать точным, а тогда![]() ;
в остальных же узлах (4.5)
;
в остальных же узлах (4.5)![]() ,00005)
,00005)
![]() ,
,
 .
.
Таблица 4.2.
|
i |
|
|
|
|
|
|
|
0 |
0 |
0 |
1 |
3 |
0 |
0 |
|
1 |
0,6284 |
0,7927 |
0,5334 |
3,3261 |
4,8678 |
1,46 |
|
2 |
1,2568 |
1,2111 |
0,2846 |
3,4057 |
8,0695 |
2,37 |
|
3 |
1,8852 |
1,3730 |
0,1518 |
3,5248 |
1,0618 |
0,3 |
|
4 |
2,5136 |
1,5854 |
0,0809 |
3,6663 |
1,1724 |
0,32 |
|
5 |
3,1420 |
1,7726 |
0,0432 |
3,8158 |
1,1944 |
0,31 |
Полиномиальные интерполяции
Весьма редко удается решить задачу прямыми аналитическими методами, тем более реализовать решение в виде вычислительного алгоритма. Основными требованиями к алгоритму являются:
- изменяемость в зависимости от начальных (исходных) условий, т.е. путь решения должен быть по возможности универсальным;
- схематизированность (однозначно должна быть определена последовательность действий),
- рекурсированность – рекурсированный алгоритм состоит из небольших частей, которые неоднократно реализуются для различных наборов значений;
-
решение, реализуемое алгоритмом должно
быть конечным, т.е. должно приводить к
конечному результату за конечное число
шагов. Другими словами, не должно
существовать различного рода расходимостей
(например, часто встречаются т.н.
логарифмические расходимости вида
![]() ,
разрывы первого и второго родов, скачки
значений производных и т.д.), которые
могут оказать существенное влияние на
конечный результат. Поэтому реализации
алгоритма непосредственно на ЭВМ должен
предшествовать тщательный анализ задачи
с целью выявления различных особенностей
в поведении исследуемого процесса.
,
разрывы первого и второго родов, скачки
значений производных и т.д.), которые
могут оказать существенное влияние на
конечный результат. Поэтому реализации
алгоритма непосредственно на ЭВМ должен
предшествовать тщательный анализ задачи
с целью выявления различных особенностей
в поведении исследуемого процесса.
Последнее требование представляется авторам наиболее важным с точки зрения достоверности получаемых результатов вычисления.
Часто при обработке статистических данных возникает задача замены аналитического описания некоторого реального процесса на другое, более удобное с точки зрения дальнейших математических преобразований. Т.е. мы заменяем некоторую функцию f(x) (известную, неизвестную, частично известную), другой ψ(x), полученной в результате некоторых преобразований. В зависимости от цели исследования выбирается метод интерполяции1 или экстраполяции - процесс построения приближенного или аппроксимирующего многочлена соответственно внутри и вне промежутка исследования. Так как методики интерполяции и экстраполяции практически не отличаются друг от друга, то в дальнейшем будем ограничиваться примерами интерполяции. В связи с этим вышеупомянутую процедуру должен предварять анализ исходной зависимости f(x), а именно:
Способ и интервал задания функции (аналитический или табличный);
Оценка степени гладкости функции, имеется ли возможность определения производных;
Требования к интерполирующей функции ψ(x) (определение ее класса);
Определение критерия качества интерполяции, иначе говоря, задание способа оценки погрешности интерполяции. Необходимо в первую очередь определить источники погрешностей. Чаще всего наиболее существенное влияние оказывают следующие:
— погрешность исходных данных;
— погрешность метода;
— погрешность округления;
Погрешность исходных данных, как правило, легче всего поддается оценке и соответствующей корректировке. Более того, часто удается получить точную аналитическую формулу ошибок, исходя из выводов теории вероятностей и математической статистики.
Так как вычислительный алгоритм является рекурсивным, состоящим из целого ряда операций, то происходит т.н. накопление погрешностей: погрешности результата каждого шага оказываются исходными для следующей операции, поэтому точный анализ погрешностей оказывается трудновыполнимым и приходится ограничиваться доверительными оценками.
Сформулируем основные положения.
Первое. Будем рассматривать как таблично, так и аналитически заданные функции.
Второе. В основном будем использовать полиномиальную или кусочно-полиномиальную интерполяцию, т.е. рассматривать в качестве аппроксимирующих функций ψ(x) только многочлены. Данная форма ψ(x) выглядит в большинстве случаев более предпочтительной с точки зрения упрощения дальнейших математических действий (дифференцирования, интегрирования). Другие виды приближений (тригонометрическое, экспоненциальное и пр.) будут применены в следующих разделах.
Третье. Построение аппроксимирующего многочлена и оценку погрешности будем производить с помощью функционалов
 (1)
(1)
 (2)
(2)
соответственно для непрерывных и дискретных функций. Оценка погрешности (степени близости функций f(x) и ψ(x)) по формулам (1) и (2) смысл среднеквадратичной погрешности.
Будем
называть вычислительный метод устойчивым,
если для любого
![]() существует такое
существует такое![]() ,
что максимальная погрешность результата
вычислений меньше
,
что максимальная погрешность результата
вычислений меньше![]() при максимальной погрешности исходных
данных меньше
при максимальной погрешности исходных
данных меньше![]() .
.