

e-maxx_algo
.pdfАлгоритм Левита нахождения кратчайших путей от заданной вершины до всех остальных вершин
Пусть дан граф с N вершинами и M ребрами, для каждого из которых указан его вес Li. Также дана стартовая вершина V0. Требуется найти кратчайшие пути от вершины V0 до всех остальных вершин.
Алгоритм Левита решает эту задачу весьма эффективно (по поводу асимптотики и скорости работы см. ниже).
Описание
Пусть массив D[1..N] будет содержать текущие кратчайшие длины путей, т.е. Di - это текущая длина кратчайшего пути от вершины V0 до вершины i. Изначально массив D заполнен значениями "бесконечность", кроме DV0 = 0. По
окончании работы алгоритма этот массив будет содержать окончательные кратчайшие расстояния.
Пусть массив P[1..N] содержит текущих предков, т.е. Pi - это вершина, предшествующая вершине i в кратчайшем пути от вершины V0 до i. Так же как и массив D, массив P изменяется постепенно по ходу алгоритма и к концу его принимает окончательные значения.
Теперь собственно сам алгоритм Левита. На каждом шаге поддерживается три множества вершин:
●M0 - вершины, расстояние до которых уже вычислено (но, возможно, не окончательно);
●M1 - вершины, расстояние до которых вычисляется;
●M2 - вершины, расстояние до которых ещё не вычислено.
Вершины в множестве M1 хранятся в виде двунаправленной очереди (deque).
Изначально все вершины помещаются в множество M2, кроме вершины V0, которая помещается в множество M1.
На каждом шаге алгоритма мы берём вершину из множества M1 (достаём верхний элемент из очереди). Пусть V - это выбранная вершина. Переводим эту вершину во множество M0. Затем просматриваем все рёбра, выходящие из этой вершины. Пусть T - это второй конец текущего ребра (т.е. не равный V), а L - это длина текущего ребра.
●Если T принадлежит M2, то T переносим во множество M1 в конец очереди. DT полагаем равным DV + L.
●Если T принадлежит M1, то пытаемся улучшить значение DT: DT = min (DT, DV + L). Сама вершина T никак не передвигается в очереди.
●Если T принадлежит M0, и если DT можно улучшить (DT > DV + L), то улучшаем DT, а вершину T возвращаем в множество M1, помещая её в начало очереди.
Разумеется, при каждом обновлении массива D следует обновлять и значение в массиве P.
Подробности реализации
Создадим массив ID[1..N], в котором для каждой вершины будем хранить, какому множеству она принадлежит: 0 - если M2 (т.е. расстояние равно бесконечности), 1 - если M1 (т.е. вершина находится в очереди), и 2 - если M0 (некоторый
путь уже был найден, расстояние меньше бесконечности).
Очередь обработки можно реализовать стандартной структурой данных deque. Однако есть более эффективный способ. Во-первых, очевидно, в очереди в любой момент времени будет храниться максимум N элементов. Но, вовторых, мы можем добавлять элементы и в начало, и в конец очереди. Следовательно, мы можем организовать очередь на массиве размера N, однако нужно зациклить его. Т.е. делаем массив Q[1..N], указатели (int) на первый элемент QH и на элемент после последнего QT. Очередь пуста, когда QH == QT. Добавление в конец - просто запись в Q[QT] и увеличение QT на 1; если QT после этого вышел за пределы очереди (QT == N), то делаем QT = 0. Добавление в начало очереди - уменьшаем QH на 1, если она вышла за пределы очереди (QH == -1), то делаем QH = N-1.
Сам алгоритм реализуем в точности по описанию выше.
Асимптотика

Мне не известна более-менее хорошая асимптотическая оценка этого алгоритма. Я встречал только оценку O (N M)
у похожего алгоритма.
Однако на практике алгоритма зарекомендовал себя очень хорошо: время его работы я оцениваю как O (M log N), хотя, повторюсь, это исключительно экспериментальная оценка.
Реализация
typedef pair<int,int> rib;
typedef vector < vector<rib> > graph;
const int inf = 1000*1000*1000;
int main()
{
int n, v1, v2; graph g (n);
... чтение графа ...
vector<int> d (n, inf); d[v1] = 0;
vector<int> id (n); deque<int> q; q.push_back (v1); vector<int> p (n, -1);
while (!q.empty())
{
int v = q.front(), q.pop_front(); id[v] = 1;
for (size_t i=0; i<g[v].size(); ++i)
{
int to = g[v][i].first, len = g[v][i].second; if (d[to] > d[v] + len)
{
d[to] = d[v] + len; if (id[to] == 0)
q.push_back (to); else if (id[to] == 1)
q.push_front (to); p[to] = v;
id[to] = 1;
}
}
}
... вывод результата ...
}

Алгоритм Флойда-Уоршелла нахождения кратчайших путей между всеми парами вершин
Дан ориентированный или неориентированный взвешенный граф с  вершинами. Требуется найти значения всех величин
вершинами. Требуется найти значения всех величин  — длины кратчайшего пути из вершины
— длины кратчайшего пути из вершины  в вершину
в вершину  .
.
Предполагается, что граф не содержит циклов отрицательного веса (тогда ответа между некоторыми парами вершин может просто не существовать — он будет бесконечно маленьким).
Этот алгоритм был одновременно опубликован в статьях Роберта Флойда (Robert Floyd) и Стивена Уоршелла (Варшалла) (Stephen Warshall) в 1962 г., по имени которых этот алгоритм и называется в настоящее время. Впрочем, в 1959 г. Бернард Рой (Bernard Roy) опубликовал практически такой же алгоритм, но его публикация
осталась незамеченной.
Описание алгоритма
Ключевая идея алгоритма — разбиение процесса поиска кратчайших путей на фазы.
Перед -ой фазой ( |
) считается, что в матрице расстояний |
сохранены длины таких кратчайших |
путей, которые содержат в качестве внутренних вершин только вершины из множества (вершины графа мы нумеруем, начиная с единицы).
Иными словами, перед -ой фазой величина |
равна длине кратчайшего пути из вершины в вершину , |
если этому пути разрешается заходить только в вершины с номерами, меньшими  (начало и конец пути не считаются). Легко убедиться, что чтобы это свойство выполнилось для первой фазы, достаточно в матрицу расстояний
(начало и конец пути не считаются). Легко убедиться, что чтобы это свойство выполнилось для первой фазы, достаточно в матрицу расстояний
записать матрицу смежности графа: |
— стоимости ребра из вершины в вершину . При этом, |
если между какими-то вершинами ребра нет, то записать следует величину "бесконечность"  . Из вершины в саму себя всегда следует записывать величину
. Из вершины в саму себя всегда следует записывать величину  , это критично для алгоритма.
, это критично для алгоритма.
Пусть теперь мы находимся на -ой фазе, и хотим пересчитать матрицу |
таким образом, чтобы |
||
она соответствовала требованиям уже для |
-ой фазы. Зафиксируем какие-то вершины и . У нас возникает |
||
два принципиально разных случая: |
|
|
|
● Кратчайший путь из вершины в вершину |
, которому разрешено дополнительно проходить через |
||
вершины |
, совпадает с кратчайшим путём, которому разрешено проходить через |
||
вершины множества |
|
. |
|
В этом случае величина  не изменится при переходе с
не изменится при переходе с  -ой на
-ой на 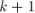 -ую фазу.
-ую фазу.
●"Новый" кратчайший путь стал лучше "старого" пути.
Это означает, что "новый" кратчайший путь проходит через вершину |
. Сразу отметим, что мы не потеряем |
|
|
общности, рассматривая далее только простые пути (т.е. пути, не проходящие по какой-то вершине дважды). |
|
||
Тогда заметим, что если мы разобьём этот "новый" путь вершиной |
на две половинки (одна идущая |
, а другая |
|
— |
), то каждая из этих половинок уже не заходит в вершину |
. Но тогда получается, что длина каждой из |
|
этих половинок была посчитана ещё на -ой фазе или ещё раньше, и нам достаточно взять просто сумму  , она и даст длину "нового" кратчайшего пути.
, она и даст длину "нового" кратчайшего пути.
Объединяя эти два случая, получаем, что на -ой фазе требуется пересчитать длины кратчайших путей между всеми парами вершин  и
и  следующим образом:
следующим образом:
new_d[i][j] = min (d[i][j], d[i][k] + d[k][j]);
Таким образом, вся работа, которую требуется произвести на -ой фазе — это перебрать все пары вершин и пересчитать длину кратчайшего пути между ними. В результате после выполнения  -ой фазы в матрице
-ой фазы в матрице
расстояний |
будет записана длина кратчайшего пути между и |
, либо , если пути между этими вершинами |
не существует. |
|
|
Последнее замечание, которое следует сделать, — то, что можно не создавать отдельную |
||
матрицу |
для временной матрицы кратчайших путей на |
-ой фазе: все изменения можно делать сразу |
в матрице . В самом деле, если мы улучшили (уменьшили) какое-то значение в матрице расстояний, мы не могли ухудшить тем самым длину кратчайшего пути для каких-то других пар вершин, обработанных позднее.
Асимптотика алгоритма, очевидно, составляет 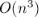 .
.

Реализация
На вход программе подаётся граф, заданный в виде матрицы смежности — двумерного массива |
размера |
, |
|
в котором каждый элемент задаёт длину ребра между соответствующими вершинами. |
|
|
|
Требуется, чтобы выполнялось |
для любых . |
|
|
for (int k=0; k<n; ++k)
for (int i=0; i<n; ++i)
for (int j=0; j<n; ++j)
d[i][j] = min (d[i][j], d[i][k] + d[k][j]);
Предполагается, что если между двумя какими-то вершинами нет ребра, то в матрице смежности было записано какое-то большое число (достаточно большое, чтобы оно было больше длины любого пути в этом графе); тогда это ребро всегда будет невыгодно брать, и алгоритм сработает правильно.
Правда, если не принять специальных мер, то при наличии в графе рёбер отрицательного веса,
врезультирующей матрице могут появиться числа вида  ,
,  , и т.д., которые, конечно, попрежнему означают, что между соответствующими вершинами вообще нет пути. Поэтому при наличии в
, и т.д., которые, конечно, попрежнему означают, что между соответствующими вершинами вообще нет пути. Поэтому при наличии в
графе отрицательных рёбер алгоритм Флойда лучше написать так, чтобы он не выполнял переходы из тех состояний,
вкоторых уже стоит "нет пути":
for (int k=0; k<n; ++k)
for (int i=0; i<n; ++i)
for (int j=0; j<n; ++j)
if (d[i][k] < INF && d[k][j] < INF)
d[i][j] = min (d[i][j], d[i][k] + d[k][j]);
Восстановление самих путей
Легко поддерживать дополнительную информацию — так называемых "предков", по которым можно будет восстанавливать сам кратчайший путь между любыми двумя заданными вершинами в
виде последовательности вершин.
Для этого достаточно кроме матрицы расстояний поддерживать также матрицу предков , которая
для каждой пары вершин будет содержать номер фазы, на которой было получено кратчайшее расстояние между ними. Понятно, что этот номер фазы является не чем иным, как "средней" вершиной искомого кратчайшего пути, и теперь нам просто надо найти кратчайший путь между вершинами и , а также между и .
Отсюда получается простой рекурсивный алгоритм восстановления кратчайшего пути.
Случай вещественных весов
Если веса рёбер графа не целочисленные, а вещественные, то следует учитывать погрешности, неизбежно возникающие при работе с типами с плавающей точкой.
Применительно к алгоритму Флойда неприятным спецэффектом этих погрешностей становится то, что найденные алгоритмом расстояния могут уйти сильно в минус из-за накопившихся ошибок. В самом деле, если на первой фазе имела место ошибка  , то на второй итерации эта ошибка уже может превратиться в
, то на второй итерации эта ошибка уже может превратиться в 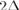 , на третьей — в
, на третьей — в 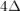 , и так далее.
, и так далее.
Чтобы этого не происходило, сравнения в алгоритме Флойда следует делать с учётом погрешности:
if (d[i][k] + d[k][j] < d[i][j] - EPS) d[i][j] = d[i][k] + d[k][j];
Случай отрицательных циклов
Если в графе есть циклы отрицательного веса, то формально алгоритм Флойда-Уоршелла неприменим к такому графу. На самом же деле, для тех пар вершин  и
и  , между которыми нельзя зайти в цикл отрицательного вес,
, между которыми нельзя зайти в цикл отрицательного вес,

алгоритм отработает корректно.
Для тех же пар вершин, ответа для которых не существует (по причине наличия отрицательного цикла на пути между ними), алгоритм Флойда найдёт в качестве ответа какое-то число (возможно, сильно отрицательное, но
не обязательно). Тем не менее, можно улучшить алгоритм Флойда, чтобы он аккуратно обрабатывал такие пары вершин и выводил для них, например,  .
.
Для этого можно сделать, например, следующий критерий "не существования пути". Итак, пусть на данном графе отработал обычный алгоритм Флойда. Тогда между вершинами  и не существует кратчайшего пути тогда и только тогда, когда найдётся такая вершина
и не существует кратчайшего пути тогда и только тогда, когда найдётся такая вершина  , достижимая из
, достижимая из  и из которой достижима , для которой выполняется
и из которой достижима , для которой выполняется  .
.
Кроме того, при использовании алгоритма Флойда для графов с отрицательными циклами следует помнить, что возникающие в процессе работы расстояния могут сильно уходить в минус, экспоненциально с каждой фазой. Поэтому следует принять меры против целочисленного переполнения, ограничив все расстояния снизу какойнибудь величиной (например,  ).
).
Более подробно об этой задаче см. отдельную статью: "Нахождение отрицательного цикла в графе".

Кратчайшие пути фиксированной длины, количества путей фиксированной длины
Ниже описываются решения этих двух задач, построенные на одной и той же идее: сведение задачи к возведению матрицы в степень (с обычной операцией умножения, и с модифицированной).
Количество путей фиксированной длины
Пусть задан ориентированный невзвешенный граф с  вершинами, и задано целое число . Требуется для каждой пары вершин
вершинами, и задано целое число . Требуется для каждой пары вершин  и найти количество путей между этими вершинами, состоящих ровно из рёбер. Пути при этом рассматриваются произвольные, не обязательно простые (т.е. вершины могут повторяться сколько угодно раз).
и найти количество путей между этими вершинами, состоящих ровно из рёбер. Пути при этом рассматриваются произвольные, не обязательно простые (т.е. вершины могут повторяться сколько угодно раз).
Будем считать, что граф задан матрицей смежности, т.е. матрицей |
размера |
, где каждый |
|
|||
элемент |
равен единице, если между этими вершинами есть ребро, и нулю, если ребра нет. Описываемый |
|
||||
ниже алгоритм работает и в случае наличия кратных рёбер: если между какими-то вершинами и |
есть сразу |
|
||||
рёбер, то в матрицу смежности следует записать это число |
. Также алгоритм корректно учитывает петли в графе, |
|
||||
если таковые имеются. |
|
|
|
|
|
|
Очевидно, что в таком виде матрица смежности графа является ответом на задачу при |
— |
|||||
она содержит количества путей длины между каждой парой вершин. |
|
|
|
|||
Решение будем строить итеративно: пусть ответ для некоторого найден, покажем, как построить его для |
|
|||||
. Обозначим через |
найденную матрицу ответов для |
, а через |
— матрицу ответов, которую |
|
||
необходимо построить. Тогда очевидна следующая формула:
|
|
Легко заметить, что записанная выше формула — не что иное, как произведение двух матриц |
и в самом |
обычном смысле: |
|
|
|
|
|
Таким образом, решение этой задачи можно представить следующим образом:
Осталось заметить, что возведение матрицы в степень можно произвести эффективно с помощью алгоритма Бинарного возведения в степень.
Итак, полученное решение имеет асимптотику |
и заключается в бинарном возведении в -ую |
степень матрицы смежности графа. |
|
Кратчайшие пути фиксированной длины
Пусть задан ориентированный взвешенный граф |
с вершинами, и задано целое число . Требуется для каждой |
|||
пары вершин и |
найти длину кратчайшего пути между этими вершинами, состоящего ровно из |
рёбер. |
||
Будем считать, что граф задан матрицей смежности, т.е. матрицей |
размера |
, где каждый |
||
элемент |
содержит длину ребра из вершины |
в вершину . Если между какими-то вершинами ребра нет, |
||
то соответствующий элемент матрицы считаем равным бесконечности  .
.
Очевидно, что в таком виде матрица смежности графа является ответом на задачу при |
— |
|
она содержит длины кратчайших путей между каждой парой вершин, или , если пути длины не существует. |
|
|
Решение будем строить итеративно: пусть ответ для некоторого найден, покажем, как построить его для |
|
|
. Обозначим через найденную матрицу ответов для , а через |
— матрицу ответов, которую |
|
необходимо построить. Тогда очевидна следующая формула:
Внимательно посмотрев на эту формулу, легко провести аналогию с матричным умножением: фактически, матрица

 умножается на матрицу
умножается на матрицу  , только в операции умножения вместо суммы по всем
, только в операции умножения вместо суммы по всем 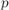 берётся минимум по всем
берётся минимум по всем 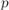 :
:
где операция  умножения двух матриц определяется следующим образом:
умножения двух матриц определяется следующим образом:
Таким образом, решение этой задачи можно представить с помощью этой операции умножения следующим образом:
Осталось заметить, что возведение в степень с этой операцией умножения можно произвести эффективно с помощью алгоритма Бинарного возведения в степень, поскольку единственное требуемое для
него свойство — ассоциативность операции умножения — очевидно, имеется.
Итак, полученное решение имеет асимптотику и заключается в бинарном возведении в  -ую степень матрицы смежности графа с изменённой операцией умножения матриц.
-ую степень матрицы смежности графа с изменённой операцией умножения матриц.

Минимальное остовное дерево. Алгоритм Прима
Дан взвешенный неориентированный граф с  вершинами и
вершинами и  рёбрами. Требуется найти такое поддерево этого графа, которое бы соединяло все его вершины, и при этом обладало наименьшим возможным весом (т.е. суммой весов рёбер). Поддерево — это набор рёбер, соединяющих все вершины, причём из любой вершины можно добраться до любой другой ровно одним простым путём.
рёбрами. Требуется найти такое поддерево этого графа, которое бы соединяло все его вершины, и при этом обладало наименьшим возможным весом (т.е. суммой весов рёбер). Поддерево — это набор рёбер, соединяющих все вершины, причём из любой вершины можно добраться до любой другой ровно одним простым путём.
Такое поддерево называется минимальным остовным деревом или просто минимальным остовом. Легко понять, что любой остов обязательно будет содержать  ребро.
ребро.
В естественной постановке эта задача звучит следующим образом: есть  городов, и для каждой пары известна стоимость соединения их дорогой (либо известно, что соединить их нельзя). Требуется соединить все города так, чтобы можно было доехать из любого города в другой, а при этом стоимость прокладки дорог была бы минимальной.
городов, и для каждой пары известна стоимость соединения их дорогой (либо известно, что соединить их нельзя). Требуется соединить все города так, чтобы можно было доехать из любого города в другой, а при этом стоимость прокладки дорог была бы минимальной.
Алгоритм Прима
Этот алгоритм назван в честь американского математика Роберта Прима (Robert Prim), который открыл этот алгоритм в 1957 г. Впрочем, ещё в 1930 г. этот алгоритм был открыт чешским математиком Войтеком Ярником (Vojtěch Jarník). Кроме того, Эдгар Дейкстра (Edsger Dijkstra) в 1959 г. также изобрёл этот алгоритм, независимо от них.
Описание алгоритма
Сам алгоритм имеет очень простой вид. Искомый минимальный остов строится постепенно, добавлением в него рёбер по одному. Изначально остов полагается состоящим из единственной вершины (её можно выбрать произвольно). Затем выбирается ребро минимального веса, исходящее из этой вершины, и добавляется в минимальный остов. После этого остов содержит уже две вершины, и теперь ищется и добавляется ребро минимального веса, имеющее один конец в одной из двух выбранных вершин, а другой — наоборот, во всех
остальных, кроме этих двух. И так далее, т.е. всякий раз ищется минимальное по весу ребро, один конец которого — уже взятая в остов вершина, а другой конец — ещё не взятая, и это ребро добавляется в остов (если таких рёбер несколько, можно взять любое). Этот процесс повторяется до тех пор, пока остов не станет содержать все вершины (или, что то же самое,  ребро).
ребро).
В итоге будет построен остов, являющийся минимальным. Если граф был изначально не связен, то остов найден не будет (количество выбранных рёбер останется меньше  ).
).
Доказательство
Пусть граф |
был связным, т.е. ответ существует. Обозначим через остов, найденный алгоритмом Прима, а через |
— минимальный остов. Очевидно, что действительно является остовом (т.е. поддеревом графа ). Покажем, |
|
что веса и |
совпадают. |
Рассмотрим первый момент времени, когда в происходило добавление ребра, не входящего в оптимальный остов
. Обозначим это ребро через |
, концы его — через |
и , а множество входящих на тот момент в остов вершин — |
||||
через (согласно алгоритму, |
, |
, либо наоборот). В оптимальном остове |
вершины и |
|||
соединяются каким-то путём |
; найдём в этом пути любое ребро , один конец которого лежит в , а другой — |
|||||
нет. Поскольку алгоритм Прима выбрал ребро |
вместо ребра , то это значит, что вес ребра |
больше либо равен |
||||
весу ребра . |
|
|
|
|
|
|
Удалим теперь из ребро , и добавим ребро |
. По только что сказанному, вес остова в результате не мог |
|||||
увеличиться (уменьшиться он тоже не мог, поскольку |
было оптимальным). Кроме того, |
не перестало быть остовом |
||||
(в том, что связность не нарушилась, нетрудно убедиться: мы замкнули путь в цикл, и потом удалили из этого |
||||||
цикла одно ребро). |
|
|
|
|
|
|
Итак, мы показали, что можно выбрать оптимальный остов |
таким образом, что он будет включать ребро . Повторяя |
|||||
эту процедуру необходимое число раз, мы получаем, что можно выбрать оптимальный остов |
так, чтобы он совпадал |
|||||
с . Следовательно, вес построенного алгоритмом Прима |
минимален, что и требовалось доказать. |
|||||
Реализации
Время работы алгоритма существенно зависит от того, каким образом мы производим поиск очередного минимального ребра среди подходящих рёбер. Здесь могут быть разные подходы, приводящие к разным асимптотикам и разным реализациям.

Тривиальная реализация: алгоритмы за  и
и 
Если искать каждый раз ребро простым просмотром среди всех возможных вариантов, то асимптотически |
|
||
будет требоваться просмотр |
рёбер, чтобы найти среди всех допустимых ребро с наименьшим весом. |
||
Суммарная асимптотика алгоритма составит в таком случае |
, что в худшем случае есть |
, — |
|
слишком медленный алгоритм. |
|
|
|
Этот алгоритм можно улучшить, если просматривать каждый раз не все рёбра, а только по одному ребру из каждой уже выбранной вершины. Для этого, например, можно отсортировать рёбра из каждой вершины в порядке возрастания весов, и хранить указатель на первое допустимое ребро (напомним, допустимы только те рёбра, которые ведут в множество ещё не выбранных вершин). Тогда, если пересчитывать эти указатели при каждом
добавлении ребра в остов, суммарная асимптотика алгоритма будет |
, но предварительно |
||
потребуется выполнить сортировку всех рёбер за |
, что в худшем случае (для плотных графов) |
||
даёт асимптотику |
. |
|
|
Ниже мы рассмотрим два немного других алгоритма: для плотных и для разреженных графов, получив в итоге заметно лучшую асимптотику.
Случай плотных графов: алгоритм за 
Подойдём к вопросу поиска наименьшего ребра с другой стороны: для каждой ещё не выбранной будем хранить минимальное ребро, ведущее в уже выбранную вершину.
Тогда, чтобы на текущем шаге произвести выбор минимального ребра, надо просто просмотреть эти минимальные рёбра у каждой не выбранной ещё вершины — асимптотика составит  .
.
Но теперь при добавлении в остов очередного ребра и вершины эти указатели надо пересчитывать. Заметим, что эти указатели могут только уменьшаться, т.е. у каждой не просмотренной ещё вершины надо либо оставить её указатель без изменения, либо присвоить ему вес ребра в только что добавленную вершину. Следовательно, эту фазу можно сделать также за  .
.
Таким образом, мы получили вариант алгоритма Прима с асимптотикой  .
.
В частности, такая реализация особенно удобна для решения так называемой евклидовой задачи о минимальном остове: когда даны  точек на плоскости, расстояние между которыми измеряется
точек на плоскости, расстояние между которыми измеряется
по стандартной евклидовой метрике, и требуется найти остов минимального веса, соединяющий их все (причём добавлять новые вершины где-либо в других местах запрещается). Эта задача решается описанным здесь алгоритмом за  времени и
времени и  памяти, чего не получится добиться алгоритмом Крускала.
памяти, чего не получится добиться алгоритмом Крускала.
Реализация алгоритма Прима для графа, заданного матрицей смежности  :
:
//входные данные int n;
vector < vector<int> > g;
const int INF = 1000000000; // значение "бесконечность"
//алгоритм
vector<bool> used (n);
vector<int> min_e (n, INF), sel_e (n, -1); min_e[0] = 0;
for (int i=0; i<n; ++i) { int v = -1;
for (int j=0; j<n; ++j)
if (!used[j] && (v == -1 || min_e[j] < min_e[v])) v = j;
if (min_e[v] == INF) { cout << "No MST!"; exit(0);
}
used[v] = true;
if (sel_e[v] != -1)
cout << v << " " << sel_e[v] << endl;
for (int to=0; to<n; ++to)
if (g[v][to] < min_e[to]) { min_e[to] = g[v][to]; sel_e[to] = v;
}
}

На вход подаются число вершин |
и матрица |
размера |
, в которой отмечены веса рёбер, и стоят |
||
числа |
, если соответствующее ребро отсутствует. Алгоритм поддерживает три массива: флаг |
||||
|
означает, что вершина включена в остов, величина |
хранит вес наименьшего |
|||
допустимого ребра из вершины |
, а элемент |
содержит конец этого наименьшего ребра (это нужно для |
|||
вывода рёбер в ответе). Алгоритм делает  шагов, на каждом из которых выбирает вершину
шагов, на каждом из которых выбирает вершину  с наименьшей меткой
с наименьшей меткой  , помечает её
, помечает её  , и затем просматривает все рёбра из этой вершины, пересчитывая их метки.
, и затем просматривает все рёбра из этой вершины, пересчитывая их метки.
Случай разреженных графов: алгоритм за 
В описанном выше алгоритме можно увидеть стандартные операции нахождения минимума в множестве и изменение значений в этом множестве. Эти две операции являются классическими, и выполняются многими структурами данных, например, реализованным в языке C++ красно-чёрным деревом set.
По смыслу алгоритм остаётся точно таким же, однако теперь мы можем найти минимальное ребро за время |
. |
|||
С другой стороны, время на пересчёт |
указателей теперь составит |
|
, что хуже, чем в |
|
вышеописанном алгоритме. |
|
|
|
|
Если учесть, что всего будет |
пересчётов указателей и |
поисков минимального ребра, то |
|
|
суммарная асимптотика составит |
— для разреженных графов это лучше, чем оба |
|
||
вышеописанных алгоритма, но на плотных графах этот алгоритм будет медленнее предыдущего. |
|
|||
Реализация алгоритма Прима для графа, заданного списками смежности |
: |
|
||
//входные данные int n;
vector < vector < pair<int,int> > > g;
const int INF = 1000000000; // значение "бесконечность"
//алгоритм
vector<int> min_e (n, INF), sel_e (n, -1); min_e[0] = 0;
set < pair<int,int> > q; q.insert (make_pair (0, 0)); for (int i=0; i<n; ++i) {
if (q.empty()) {
cout << "No MST!"; exit(0);
}
int v = q.begin()->second; q.erase (q.begin());
if (sel_e[v] != -1)
cout << v << " " << sel_e[v] << endl;
for (size_t j=0; j<g[v].size(); ++j) { int to = g[v][j].first,
cost = g[v][j].second; if (cost < min_e[to]) {
q.erase (make_pair (min_e[to], to)); min_e[to] = cost;
sel_e[to] = v;
q.insert (make_pair (min_e[to], to));
}
}
}
На вход подаются число вершин и списков смежности: |
— это список всех рёбер, исходящих из вершины , в |
|
виде пар (второй конец ребра, вес ребра). Алгоритм поддерживает два массива: величина |
хранит |
|
вес наименьшего допустимого ребра из вершины , а элемент |
содержит конец этого наименьшего ребра |
|
(это нужно для вывода рёбер в ответе). Кроме того, поддерживается очередь  из всех вершин в порядке увеличения их меток . Алгоритм делает
из всех вершин в порядке увеличения их меток . Алгоритм делает  шагов, на каждом из которых выбирает вершину
шагов, на каждом из которых выбирает вершину  с наименьшей меткой
с наименьшей меткой
(просто извлекая её из начала очереди), и затем просматривает все рёбра из этой вершины, пересчитывая их метки (при пересчёте мы удаляем из очереди старую величину, и затем кладём обратно новую).
Аналогия с алгоритмом Дейкстры
В двух описанных только что алгоритмах прослеживается вполне чёткая аналогия с алгоритмом Дейкстры: он имеет
такую же структуру ( фаза, на каждой из которых сначала выбирается оптимальное ребро, добавляется в ответ, а затем пересчитываются значения для всех не выбранных ещё вершин). Более того, алгоритм Дейкстры тоже имеет
фаза, на каждой из которых сначала выбирается оптимальное ребро, добавляется в ответ, а затем пересчитываются значения для всех не выбранных ещё вершин). Более того, алгоритм Дейкстры тоже имеет