

Мокроусов_ОКЗИ
.pdfОтличие для схемы при Nk>6 состоит в применении SubByte для каждого 4-го байта из Nk. Цикловая константа независит от Nk и определяется следующим образом:
Rcon[i] = ( RC[i], '00' , '00' , '00' ), где
RC[0]='01'
RC[i]=xtime(Rcon[i-1])
2.5.9. Выбор циклового ключа
i-ый цикловой ключ получается из слов массива циклового ключа от W[Nb*i] и доW[Nb(i+1)]. Это показано на рис. 2.7.
Рис. 2.7. Расширение ключа и выбор циклового ключа для Nb=6 и Nk=4
Замечание: Алгоритм выработки ключей можно осуществлять и без использования массива W[Nb*(Nr+1)]. Для реализаций, в которых существенно требование к занимаемой памяти, цикловые ключи могут вычисляться на лету посредством использования буфера из Nk слов.
31
2.5.10. Шифр
Шифр Rijndael состоит из:
Начального добавления циклового ключа;
Nr-1 циклов;
заключительного цикла.
На псевдо-Си это выглядит следующим образом:
Rijndael (State, CipherKey)
{
KeyExpansion(CipherKey, ExpandedKey); // Расши-
рение ключа
AddRoundKey(State, ExpandedKey); // Добавление циклового ключа
For ( i=1 ; i<Nr ; i++)
Round(State,ExpandedKey+Nb*i); // циклы
FinalRound(State, ExpandedKey+Nb*Nr); // заклю-
чительный цикл
}
Если предварительно выполнена процедура расширения ключа, то Rijndael будет выглядеть следующим образом:
Rijndael (State, CipherKey)
{
AddRoundKey(State, ExpandedKey); For ( i=1 ; i<Nr ; i++) Round(State,ExpandedKey+Nb*i);
FinalRound(State, ExpandedKey+Nb*Nr);
}
Замечание: Расширенный ключ должен всегда получаться из ключа шифрования и никогда не указывается напрямую. Нет никаких ограничений на выбор ключа шифрования.
32
3.МОДЕЛИ ОТКРЫТЫХ ТЕКСТОВ
3.1.Алфавиты открытых сообщений
Сообщения представляют собой последовательности знаков (или слова) некоторого алфавита. Различают естественные алфавиты (русский, английский,…), и специальные алфавиты – цифровые или буквенно-цифровые (двоичный алфавит, состоящий из символов 0 и 1).
Буквенный алфавит, в котором буквы расположены в их естественном порядке, обычно называют нормальным алфавитом. В противном случае говорят о смешанных алфавитах. В свою очередь смешанные алфавиты де-
лят на систематически перемешанные алфавиты и слу-
чайные алфавиты. К первым относятся алфавиты, полученные из нормального на основе некоторого правила, ко вторым – алфавиты, буквы которых следуют друг за другом в хаотическом порядке. Смешанные алфавиты обычно используются в качестве нижней строки подстановки, представляющей собой ключ шифра простой замены. Для запоминания ключа применяется несложная процедура перемешивания алфавита, например, основанная на ключе-
вом слове.
Полный русский алфавит состоит из 33 букв. Вместе с тем используются и сокращённые русские алфавиты, содержащие 32, 31 или 30 букв: можно отождествить буквы Е и Ё, И и Й, Ь и Ъ. Часто бывает удобно включить в алфавит знак пробела между словами.
Английский алфавит состоит из 26 букв. Иногда используется сокращённый 25-буквенный алфавит, в котором отождествлены буквы I и J.
Во французском и испанском языках практически не используются буквы K и W. Эти буквы встречаются только в некоторых словах иностранного происхождения
33
(«kilo, wagon»). Поэтому часто используется 24-буквенный алфавит.
Внемецком языке исключительно редки буквы Q, X
иY. Они лишь в некоторых малоупотребительных словах иностранного происхождения («quarta»). Помимо латинских букв немецкий алфавит использует ещё три буквы ö, ä, ë, которые заменяются эквивалентами OE, AE и UE соответственно. Поэтому часто обходятся 24 буквами.
Витальянском языке крайне редки буквы J, K, W, X, Y. Поэтому используется 21или 22-х буквенный алфавит.
Из известных специальных алфавитов можно выделить код Бодо, применяемый для передачи сообщений с помощью телетайпов и использующий 32-значный алфавит, а также код ASCII – американский стандартный код информационного обмена.
3.2.Частотные характеристики текстовых сообщений
Криптоанализ любого шифра невозможен без учёта особенностей текстов сообщений, подлежащих шифрованию. Наиболее важной характеристикой текстов является избыточность текста, введённая Шенноном. Именно избыточность открытого текста, проникающая в шифртекст, является основной слабостью шифра.
Более простыми характеристиками текстов, используемые в криптоанализе, являются такие характеристики,
как повторяемость букв, пар букв (биграмм) и вообще k-
грамм, сочетаемость букв друг с другом, чередование гласных и согласных, и некоторые другие. Такие характеристики изучаются на основе наблюдений текстов достаточно большой длины. Некоторая разница значений частот, приводимая в различных источниках, объясняется
34
тем, что частоты существенно зависят не только от длины текста, но и от его характера. Например, редкая буква Ф может стать довольно частой в технических текстах («функция», «дифференциал», «коэффициент»,…).
Ещё большие отклонения от нормы в частоте употребления отдельных букв наблюдаются в некоторых художественных произведениях, особенно в стихах. Хотя подобные отклонения незначительны и в первом приближении ими можно пренебречь, для надёжности определения средней частоты буквы желательно иметь набор различных текстов, заимствованных из различных источников. Однако, подобные отклонения незначительны, и в первом приближении ими можно пренебречь.
Для русского языка частоты (в порядке убывания) знаков алфавита, в котором также имеется знак пробела между словами приведены в табл. 3.1 и на рис. 3.1.
Таблица 3.1
- |
О |
Е,Ё |
А |
И |
Т |
Н |
С |
0.175 |
0.090 |
0.072 |
0.062 |
0.062 |
0.053 |
0.053 |
0.045 |
Р |
В |
Л |
К |
М |
Д |
П |
У |
0.040 |
0.038 |
0.035 |
0.028 |
0.026 |
0.025 |
0.023 |
0.021 |
Я |
Ы |
З |
Ь,Ъ |
Б |
Г |
Ч |
Й |
0.018 |
0.016 |
0.016 |
0.014 |
0.014 |
0.013 |
0.012 |
0.010 |
Х |
Ж |
Ю |
Ш |
Ц |
Щ |
Э |
Ф |
0.009 |
0.007 |
0.006 |
0.006 |
0.004 |
0.003 |
0.003 |
0.002 |
Имеется правило запоминания десяти наиболее частых букв русского алфавита. Эти буквы составляют слово СЕНОВАЛИТР.
35

Я  Ю
Ю  Э
Э  Ь,Ъ
Ь,Ъ  Ы
Ы 
Щ
Ш
Ч 
Ц  Х
Х  Ф
Ф  У
У  Т
Т  С
С  Р
Р  П
П  О
О  Н
Н  М
М  Л
Л  К
К  Й
Й  И
И  З
З  Ж
Ж  Е,Ё
Е,Ё  Д
Д  Г
Г  В
В  Б
Б  А
А  пробел
пробел 
0 |
0,02 |
0,04 |
0,06 |
0,08 |
0,1 |
0,12 |
0,14 |
0,16 |
0,18 |
Рис. 3.1. Диаграмма встречаемости букв русского языка
Для европейских букв языков 10 наиболее частых букв приведены в табл. 3.2.
36
Таблица 3.2
Французский |
E |
S |
A |
N |
T |
I |
R |
U |
L |
O |
79,9 |
|
% |
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
Немецкий |
E |
N |
I |
S |
T |
A |
H |
D |
U |
|
77,2 |
|
|
% |
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
Английский |
E |
T |
A |
I |
N |
R |
O |
S |
H |
D |
75,3 |
|
% |
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
Испанский |
E |
A |
O |
S |
I |
R |
N |
L |
D |
C |
78,3 |
|
% |
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
Итальянский |
I |
E |
A |
O |
N |
T |
R |
L |
S |
C |
79,9 |
|
% |
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
Для английского языка правило запоминания десяти наиболее частых букв: слово TETRIS-HONDA.
Устойчивыми являются также частотные характеристики биграмм, триграмм, … k-грамм осмысленных текстов. Построение и анализ таблиц k-грамм служит для получения более точных сведений об открытых текстах. Неравновероятность k-грамм тесно связана с характерной особенностью открытого текста – наличием в нём большого числа повторений отдельных фрагментов текста: корней, окончаний, суффиксов, слов и фраз. Так, для русского языка такими привычными фрагментами являются наиболее частые биграммы (рис. 3.2, 3.3) и триграммы:
СТО, ЕНО, НОВ, ТОВ, ОВО, ОВА.
37

100 
 80
80 
 60
60 
 40
40 
 20
20 

0  ВО ГО ЕН КО НА НО ОВ ОС РА РО СТ ТО
ВО ГО ЕН КО НА НО ОВ ОС РА РО СТ ТО
Рис. 3.2. Диаграмма встречаемости наиболее частых биграмм русского языка
25 
 20
20 
 15
15 
 10
10 
 5
5 

0  АА ВВ ДД ЕЕ ИИ КК ЛЛ ММННООРР СС ТТ ЯЯ
АА ВВ ДД ЕЕ ИИ КК ЛЛ ММННООРР СС ТТ ЯЯ
Рис. 3.3. Диаграмма встречаемости всех удвоений русского языка
Из таблиц k-грамм можно извлечь информацию о сочетаемости букв, то есть о предпочтительных связях букв друг с другом. При анализе сочетаемости букв друг с другом следует иметь в виду зависимость появления букв в открытом тексте от значительного числа предшествующих букв. Для анализа этих закономерностей используют поня-
38
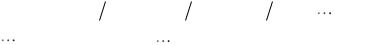
тие условной вероятности. Наблюдения над открытыми текстами показывают, что для условных вероятностей выполняются неравенства
где
a a |
|
i |
i |
1 |
2 |
|
|
|
i |
|
p |
i |
i |
|
|
|
|
i |
i |
|
p |
i |
i |
i |
|
|
p |
|
a |
|
a |
a |
|
, |
p |
|
a |
a |
|
a |
a a |
|
, |
||||
|
|
|
1 |
|
|
1 |
2 |
|
|
|
|
1 |
2 |
|
|
1 |
2 |
3 |
|
|
a |
|
– k-грамма, |
a , a , |
|
a буквы алфавита. |
|
||||||||||||||
|
i |
|
|
|||||||||||||||||
|
|
k |
|
|
|
|
|
1 |
2 |
|
n |
|
|
|
|
|
|
|
|
|
Вопрос о зависимости букв алфавита в открытом тексте от предыдущих букв исследовался русским математиком Марковым. Он доказал, что появления букв в открытом тексте нельзя считать независимыми друг от друга. В связи с этим им отмечена ещё одна устойчивая закономерность открытых текстов, связанная с чередованием гласных и согласных букв. Им были подсчитаны частоты встречаемости биграмм вида гласная-гласная (г,г), гласнаясогласная (г,с), согласная-гласная (с,г), согласнаясогласная (с,с) в русском тексте длиной в 105 знаков. Результаты подсчёта отражены в табл. 3.3.
|
|
|
Таблица 3.3 |
|
Г |
С |
Всего |
|
|
|
|
Г |
6588 |
38310 |
44898 |
|
|
|
|
С |
38296 |
16806 |
55102 |
|
|
|
|
Из таблицы следует, что для русского языка характерно чередование гласных и согласных, причём относительные частоты служат приближениями условных и без-
условных вероятностей |
|
Р(г/с) 0.663, |
Р(г/с) 0.872, |
Р(г) 0.432, |
Р(с) 0.568 |
39
Сочетаемость букв русского языка представлена в табл. 3.4.
|
|
|
|
|
|
Таблица 3.4 |
|
Слева от буквы |
|
Буква |
Справа от буквы |
||||
Гласн., |
соглас.,% |
буквы |
|
Буквы |
гласн.,% |
соглас.,% |
|
% |
|
|
|
|
|
|
|
3 |
97 |
в, р, н |
А |
л, н, с |
12 |
|
88 |
80 |
20 |
и, а, о |
Б |
о, ы, е |
81 |
|
19 |
68 |
32 |
е, и, о |
В |
о, а, и |
60 |
|
40 |
78 |
22 |
и, е, о |
Г |
о, а, р |
69 |
|
31 |
72 |
28 |
и, е, о |
Д |
е, а, и |
68 |
|
32 |
19 |
81 |
т, р, н |
Е, Ё |
н, т, р, |
12 |
|
88 |
83 |
17 |
а, у, о |
Ж |
е, и, д |
71 |
|
29 |
89 |
11 |
е, а, и |
З |
а, н, в |
51 |
|
49 |
27 |
73 |
о, л, н |
И, Й |
с, н, в |
25 |
|
75 |
55 |
45 |
а, и, с |
К |
о, а, и |
73 |
|
27 |
77 |
23 |
е, о, а |
Л |
и, е, о |
75 |
|
25 |
80 |
20 |
и, е, о |
М |
и, е, о |
73 |
|
27 |
55 |
45 |
а, и, е |
Н |
о, а, и |
80 |
|
20 |
11 |
89 |
в, т, н |
О |
в, с, т |
15 |
|
85 |
65 |
35 |
и, е, о |
П |
о, р, е |
68 |
|
32 |
55 |
45 |
п, о, е |
Р |
а, е, о |
80 |
|
20 |
69 |
31 |
е, и, о |
С |
т, к, о |
32 |
|
68 |
57 |
43 |
е, о, с |
Т |
о, а, е |
63 |
|
37 |
15 |
85 |
н, м, р |
У |
т, п, с |
16 |
|
84 |
70 |
30 |
е, о, и |
Ф |
и, е, о |
81 |
|
19 |
90 |
10 |
а, ы, и |
Х |
о, и, с |
43 |
|
57 |
69 |
31 |
н, а, и |
Ц |
и, е, а |
93 |
|
7 |
82 |
18 |
у, и, о |
Ч |
е, и, т |
66 |
|
34 |
67 |
33 |
а, и, в |
Ш |
е, и, н |
68 |
|
32 |
84 |
16 |
а, я, ю |
Щ |
е, и, а |
97 |
|
3 |
40