

3.2.1. Точечные оценки параметров
Рассмотрим генеральную совокупность с двумя признаками х и у, совместное распределение которых задано плотностью двумерного нормального закона:
![]() (121)
(121)
где
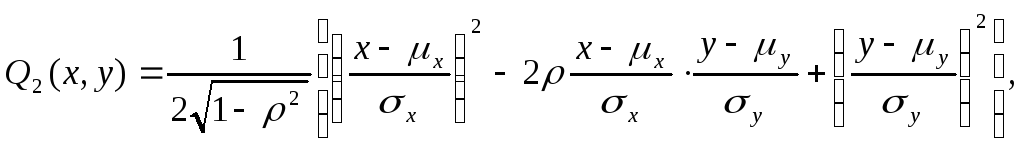 определяемого
пятью
параметрами
определяемого
пятью
параметрами
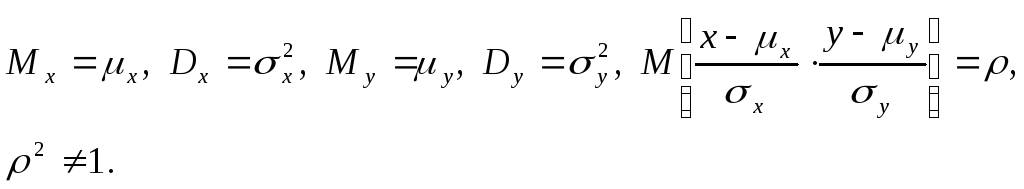
Имея эти параметры, можно получить уравнения линий регрессии, показывающих изменение условных математических ожиданий в зависимости от изменения соответствующих значений случайных аргументов:
![]() —прямая
регрессии у
на x;
—прямая
регрессии у
на x;
![]() —прямая
регрессии x
на y;
—прямая
регрессии x
на y;
![]() –коэффициент
регрессии у
на х;
–коэффициент
регрессии у
на х;
![]() –коэффициент
регрессии х
на
у.
–коэффициент
регрессии х
на
у.
Полезно вспомнить, что квадрат коэффициента корреляции 2, т. е. коэффициент детерминации, в рассматриваемой модели указывает долю дисперсии одной случайной величины, обусловленную вариацией другой. Коэффициент регрессии yx показывает, на сколько единиц своего измерения увеличится (>0) или уменьшится (<0) в среднем у(Му/х), если х увеличить на единицу своего измерения.
Задача двумерного корреляционного анализа состоит, прежде всего, в оценке пяти параметров, определяющих генеральную совокупность.
В качестве точечных оценок неизвестных начальных моментов первого и второго порядка генеральной совокупности берутся соответствующие выборочные моменты.
Точечные же оценки неизвестных других параметров получают с помощью формул, аналогичных формулам вычисления самих параметров через генеральные начальные моменты. Таким образом, будем иметь:
![]() —оценка
для x,
—оценка
для x,
![]() —оценка
для у,
—оценка
для у,
![]() —оценка
для М(х2),
—оценка
для М(х2),
![]() —оценка
для М(у2),
—оценка
для М(у2),
xy — оценка для М(ху).
Откуда
![]() —оценка
для
—оценка
для
![]() ,
,
![]() —оценка
для
—оценка
для
![]() ,
,
r=![]() — оценка
для .
— оценка
для .
Оценки генеральных коэффициентов регрессии yx и xy получаются соответственно по формулам:
![]()
откуда оценки уравнений регрессии имеют вид:
![]()
При
этом
![]() и
и![]() — обозначения
оценок для условных математических
ожиданий Му/х
и Мх/у
генеральной совокупности.
— обозначения
оценок для условных математических
ожиданий Му/х
и Мх/у
генеральной совокупности.
Следует
отметить, что вышеприведенные точечные
оценки являются состоятельными, а
![]() и
и
![]() несмещенными и эффективными. Кроме
того, распределение выборочных средних
(
несмещенными и эффективными. Кроме
того, распределение выборочных средних
(![]() ,
,![]() )
не зависит от распределения (
)
не зависит от распределения (![]() ).
Наконец, выборочный коэффициент
корреляции r
по абсолютной
величине не превосходит единицы.
).
Наконец, выборочный коэффициент
корреляции r
по абсолютной
величине не превосходит единицы.
2.3.3. Приемы вычисления выборочных
характеристик
Если объем выборки невелик, то наблюдаемые точки располагают в таблице в порядке их регистрации и обрабатывают по следующей схеме:
|
х |
у |
x2 |
y2 |
ху |
|
. . xj . . |
. . yj . . |
. .
. . |
. .
. . |
. . xjyj . . |
|
|
|
|
|
|
В схеме последовательно заполняют столбцы таблицы результатами операций, указанных сверху. В последней строке вычисляются соответствующие суммы элементов столбцов. Далее используют формулы:
![]()


Если выборка многочисленна, то данные группируются путем построения двумерного интервального ряда, корреляционная таблица для которого имеет вид:
|
x y |
… |
(ak-bk] |
… |
my |
|
. . . (cl-dl] . . . mx |
. . . … . . . … |
. . . mkl
mk* |
. . . … . . . … |
. . . m*l . . . n |
В таблице mkl — частота прямоугольника, в основании которого лежит полуинтервал (ak - bk], а по высоте — (cl - dl], т.е. число точек выборки, попавших внутри или на часть границы прямоугольника, задаваемой полуинтервалами. При этом длины интервалов по х одинаковы и равны hx; то же самое относится и к у (одинаковой длины hy).
Для вычисления характеристик интервального вариационного ряда переходим к условному дискретному вариационному ряду с условными вариантами
![]()
где х0, у0 — рабочие средние — выбираются обычно равными
центрам интервалов, лежащих в середине соответ-
ствующих одномерных рядов;
xk — центры интервалов.
Таким образом, условные варианты — целые числа, наименее уклоняющиеся от нуля по абсолютной величине.
Вычисления удобно производить по схеме, последовательно заполняя строки, лежащие ниже таблицы двумерного ряда условных вариантов (1 4), и столбцы, лежащие справа от этой таблицы (1 2):
|
x' y' |
… xk … |
my |
|
|
|
. yl .
|
. . . … mkl … . . .
|
. mxl .
|
.
. |
.
. |
|
mx |
… mk* … |
n |
|
|
|
1. x'mx 2. (x')2mx 3.
4.
|
… x'kmk* … … (x'k)2mk* ... …
… |
| ||
Заметим,
что для контроля вычислений можно
использовать равенство
![]() ,
т.е. равенство чисел в конце строки 3 и
столбца 1.
,
т.е. равенство чисел в конце строки 3 и
столбца 1.
Далее используются формулы:
![]()
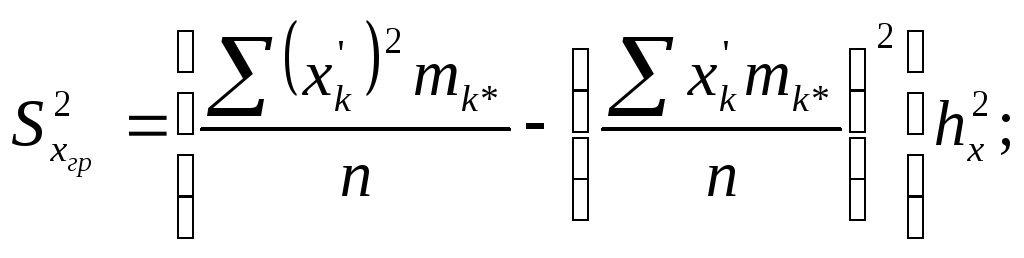
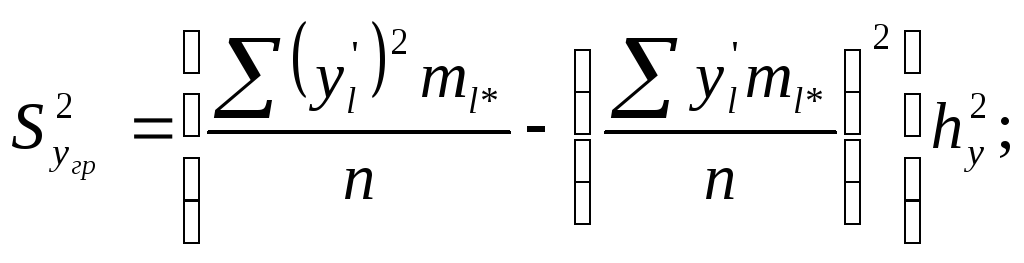

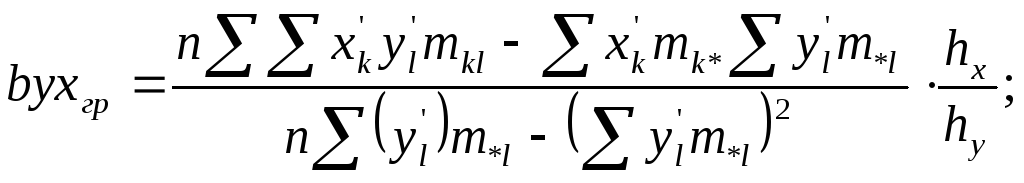
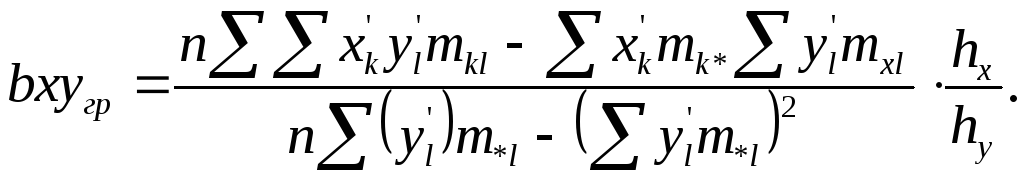
При
группировке вычисленные характеристики
могут сильно отличаться от выборочных.
Оценки по группированным данным
центральных моментов второго порядка
![]() и
и![]() можно улучшить
поправками Шеппарда:
можно улучшить
поправками Шеппарда:
![]() (122)
(122)
Эти поправки часто сглаживают ошибки, возникающие от группировки, если длина интервала (h) не превосходит восьмой части размаха соответствующего признака.