

Житомирської області за 2011-2013 рр.
Завершується перший підрозділ другого розділу порівнянням екологічного стану досліджуваного об'єкта у Житомирській області із середнім значенням по Україні. Для цього будується графік (рис. 2.3)

Рис. 2.3. Співвідношення забруднення об'єкту дослідження
У Житомирський області та в середньому по Україні
Провести аналіз екологічного стану Житомирської області. Визначити чи забруднення досліджуваного об'єкта більшим ніж середні значення по Україні в цілому. Встановити можливість запровадження органічного сільського господарства у області та конкретизувати райони.
При проведенні експериментів чи спостережень дослідники, як правило, отримають значний масив випадкових даних, що певним чином представляють генеральну сукупність даних. Відразу проаналізувати та зробити висновки за такими наборами первинних даних досить складно. Для того, щоб отримати первинне уявлення про результати досліджень використовують описову статистику.
Описова статистика являє собою техніку збору і підсумовування кількісних даних, яка використовується для перетворення масиву цифрових даних у зручну для сприйняття і подальшого дослідження форму. Відтак, метою описової статистики є узагальнити первинні результати, отримані в результаті спостережень і експериментів.
Первинна обробка результатів спостережень передбачає реалізацію наступних завдань:
проведення статистичного оцінювання за допомогою пакету аналізу даних Excel;
оцінка числових характеристик вибірки.
Примітка: Для обробки числових даних використовують Пакет аналізу. Попередньо його необхідно налаштувати:
в Excel 2003: Сервіс → Надбудови → галочка напроти Пакета аналізу. У меню Сервіс з'явиться команда Аналіз даних.
в Excel 2007: Офіс → Параметри Excel → Надбудови → Управління → Надбудови Excel → кнопка Перейти → галочка навпроти Пакета аналізу. На вкладці Дані у групі Аналіз з'явиться команда Аналіз даних.
Діалогове вікно режиму Описова статистика має наступні параметри:
Вхідний діапазон – блок даних, що містить значення досліджуваного показника (для дослідження курсового проекту використовуються розраховані дані по районам Житомирської області в середньому за три роки).
Групування визначає орієнтацію блоку вихідних даних на робочому аркуші (стовпчики чи стрічечки).
Мітки - наявність імен в блоці даних. Для його визначення треба встановити перемикач в положення Мітки, якщо перший рядок (стовпець) у вхідному діапазоні містить назви стовпців.
Рівень надійності вказує відсоток надійності даних для обчислення довірчого інтервалу. Для його визначення треба встановити прапорець і в полі ввести необхідне значення. Наприклад, значення 95% обчислює рівень надійності середнього із значущістю 0.05.
К-ий найбільший - порядковий номер найбільшого після максимального значення. Встановити прапорець, якщо у вихідну таблицю необхідно включити рядок для k-го найбільшого значення для кожного діапазону даних. У відповідному вікні ввести число k. Якщо k дорівнює 1, цей рядок буде містити максимум з набору даних.
К-ий найменший - порядковий номер найменшого після мінімального значення.
Підсумкова статистика - повний розрахунок показників описової статистики.
Після того як всі необхідні поля заповнені, тиснемо ОК. На основі отриманих даних заповнити табл. 2.2.
Таблиця 2.2
Описова статистика на базі пакету аналізу даних Excel
|
Назва показника |
Значення показника |
|
Середнє |
|
|
Стандартна похибка |
|
|
Медіана |
|
|
Мода |
|
|
Стандартне відхилення |
|
|
Дисперсія вибірки |
|
|
Ексцес |
|
|
Асиметричність |
|
|
Інтервал |
|
|
Мінімум |
|
|
Максимум |
|
|
Сума |
|
|
Рахунок |
|
|
Рівень надійності (95,0%) |
|
Проаналізуйте отримані дані у розрізі основних груп показників: центра розподілу, розміру варіації та форми розподілу, а також зробіть висновки за результатами дослідження.
Примітка. Для симетричного нормального розподілу середнє арифметичне, мода та медіана співпадають. Для рівномірного розподілу співпадають середнє арифметичне та медіана. У випадку асиметричних розподілів середнє, мода та медіана дуже різняться. Для таких розподілів доцільно використовувати медіану.
Стандартне відхилення найкраще характеризує ширину нормального розподілу випадкових величин. У діапазон М±s припадає близько 70 % випадкових величин нормального розподілу. Для неоднорідних сукупностей середній обсяг викидів шкідливих речовин по аналогії можна записати у діапазоні від додатного до від’ємного показника, у той час, як очевидно, що від’ємного значення викидів не існує.
Із непараметричних характеристик розміру варіації найбільш вживаним є інтервал (або розмах) – різниця між максимальним та мінімальним значенням змінної.
Чим більшим є стандартне відхилення, тим більшим є розмах варіації ознаки в сукупності. Статистичні характеристики варіації взаємопов’язані, оскільки дисперсія – це середній квадрат відхилення.
Якщо коефіцієнти асиметрії і ексцесу перевищують за абсолютною величиною число «3», то робиться висновок про невідповідність розподілу характеру нормального.
На основі отриманих даних необхідно провести групування районів Житомирської області за ступенем забруднення об'єкту дослідження із рівним інтервалом та оптимальним числом груп. Отримані результати представити у вигляді гістограми. Для здійснення групування необхідно розрахувати табл. 2.3. Допоміжні дані для групування.
Для складання рівноінтервального ряду розподілу районів Житомирської області за ступенем забруднення об'єкту дослідження за допомогою формул Стерджесса визначається число інтервалів (m):
m=1+3,322 lg n, де
n – чисельність одиниць сукупності (кількість районів).
Мінімальне та максимальне значення розраховується за допомогою функцій МИН та МАКС відповідно.
Примітка. Переліком аргументів для пошуку мінімального та максимального значення (“Число 1”) приймається масив даних в середньому за три роки по всім 23-ьом районам.
Розмір інтервалу (і) розраховується за формулою:
і=(хмакс - хмін)/m
Таблиця 2.3.
Допоміжні дані для групування
|
Назва показника |
Умовне позначення |
Розрахункове значення |
|
Число інтервалів |
m |
|
|
Мінімальне значення забруднення |
хмін |
|
|
Максимальне значення забруднення |
хмакс |
|
|
Розмір інтервалу |
і |
|
Примітка. Число інтервалів заокруглюється до найменшого цілого. Наприклад, якщо число при розрахунках отримали 5,56, заокруглюємо до 5.
У випадку, коли кількість даних, що групуються, менша за 20, число інтервалів приймають у розмірі 4-5.
Далі формується інтервальний ряд у електронних таблицях Excel. Перший інтервал дорівнює мінімальному значенню плюс розмір інтервалу. Другий інтервал дорівнює перший інтервал плюс розмір інтервалу. Третій інтервал дорівнює другий інтервал плюс розмір інтервалу і т. д.
Для розрахунку часто використовується функція Частота. Масив даних це середні за три роки по районам Житомирської області. Масив інтервалів – інтервальний ряд. Таким чином отримано стовпці частот значень ознаки у інтервалах.
Примітка. Запровадження функції здійснюється одночасним натисканням клавіш CTRL+SHIFT+ENTER
На основі отриманих результатів (частот значень ознаки у інтервалах) будується друга Гістограма (Рис. 2.2. Діаграма розподілу частот забруднення об'єкту дослідження).
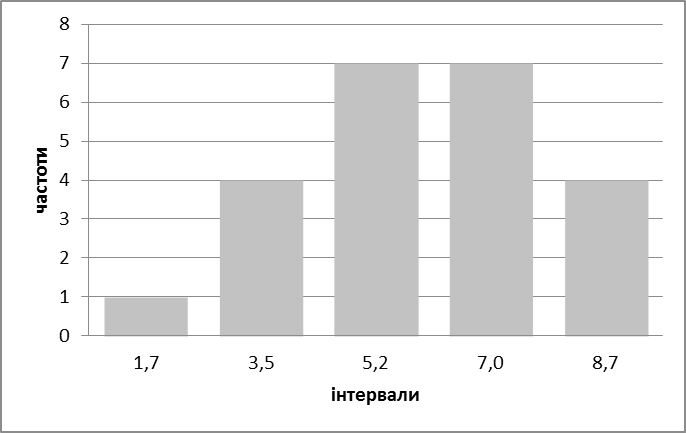
Рис. 2.2. Гістограма розподілу частот забруднення об'єкту дослідження
Побудувати інтервальний ряд розподілу можна також за допомогою пакету «Аналізу даних» Excel. Для цього серед засобів аналізу необхідно обрати опцію «Гистограмма» та додати у діалоговому вікні масив даних, що групуються. Також слід поставити прапорець навпроти опції «Вывод графика». За допомогою таких маніпуляцій ви отримаєте дані, на основі яких слід сформувати аналогічні наведеним вище табл. 2.3 «Дані для групування» та вивести рис. 2.2. «Гістограма розподілу частот забруднення об’єкту дослідження».
|
Таблиця 2.3 Дані групування за допомогою пакету Аналізу даних Excel |
| |
|
Інтервали розподілу |
Частота | |
|
до 13,7 |
2 | |
|
від 13,8 до 18,6 |
6 | |
|
від 18,7 до 22,5 |
0 | |
|
понад 22,6 |
4 |
Рис. 2.2. Гістограма розподілу частот забруднення об’єкту дослідження |
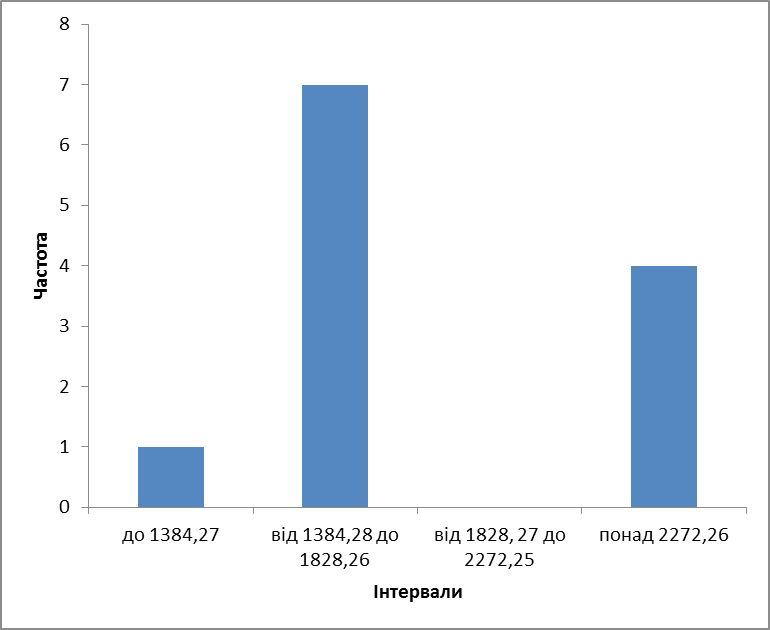
Оцінити кількість найбільш та найменш забруднених районів Житомирської області. Виявити рівномірність розподілу районів у інтервалах.
У підрозділі 2.2. здійсніть прогноз забруднення об’єкту дослідження. Задачі прогнозно-розрахункового напрямку, із використанням регресійного методу аналізу, дають можливість досліджувати особливості та закономірності взаємозв’язку факторних та результативних ознак. Тобто, кожен із методів регресії оцінює взаємозв'язок фактичних даних та інших параметрів, які найчастіше всього є показниками того, коли були проведені спостереження. Це можуть бути як числові значення кожного результату спостереження у часовому ряду, так і самі дата або час спостереження. За допомогою цього методу зв’язок між явищами фіксується аналітично у вигляді математичних виразів (функцій).
Під прогнозуванням мається на увазі науково обґрунтоване передбачення ймовірнісних шляхів розвитку досліджуваних явищ і процесів у майбутньому (на 1 рік вперед). Прогнозування засноване на зберіганні загальної тенденції розвитку явищ у часі, тому на практиці процес прогнозування зводиться до добору на підставі даних минулих періодів аналітичних залежностей досліджуваного параметра від чинників, що впливають, і екстраполяції цих залежностей на майбутнє.
Одним з найбільш поширених засобів прогнозування є побудова ліній тренда засобами MS Excel на основі точкової діаграми за фактичними даними минулих періодів. Ті чи інші якісні властивості розвитку виражають різні рівняння трендів. MS Excel пропонує різноманітні типи апроксимуючої залежності: лінійна, логарифмічна, поліноміальна, степенева, експонентна, лінійна фільтрація. Однак, спроба реалізувати запропоновані моделі призводить до значно різних чисельних результатів, які до того ж, часто мають різний напрямок розвитку. Це викликає необхідність вибору найкращої моделі прогнозування.
Розробка прогнозу із застосуванням ліній тренду передбачає реалізацію наступних завдань:
вибір однієї або декількох кривих, форма яких відповідає динаміці часового ряду;
оцінка параметрів кривих;
перевірка адекватності вибраних кривих прогнозованому процесу і остаточний вибір кривої;
розрахунок прогнозних значень.
Приклад реалізації завдання. На рисунку 2.4 наведено статистичні дані обсягів викидів забруднюючих речовин в атмосферне повітря від стаціонарних та пересувних джерел забруднення (тис. т) за період у 23 роки.
Теоретично обґрунтуємо вибір залежностей відповідно до фактичного ряду. Так, наприклад, якщо в якості фактичного ряду використати дані, що містять нульові або від'ємні значення, то з подальшого розгляду виключаються степенева та експонентна залежності. У даному прикладі виключається лише тренд побудований за допомогою лінійної фільтрації, оскільки він не придатний для прогнозування майбутніх значень.
На основі вхідного ряду даних побудуємо графік, використовуючи для цього стандартний Мастер диаграмм МS Ехсеl. Потім виділяємо базову лінію і натискаємо праву кнопку миші. З контекстного меню обираємо команду Добавить линию тренда. У вікнах, як представлено на рис. 2.4 обираємо тип ліній тренда: лінійна, логарифмічна, поліноміальна, степенева, експонентна.

Рис. 2.4. Лінії тренду викидів забруднюючих речовин в атмосферне повітря
Після побудови ліній тренду на базі теоретично придатних залежностей, кожний результат оцінюємо шляхом ранжування за критеріями, що характеризують достовірність та загальну похибку прогнозу. Для визначення достовірності прогнозу використаємо значення похибки апроксимації (R2) (рис. 2.3). Чим ближче значення R2 до одиниці, тим точніше обрана модель відображає тенденцію розвитку, тобто, тим більше можна довіряти результатам прогнозування. При ранжуванні за цим критерієм моделі з максимальним значенням похибки апроксимації присвоюється мінімальний ранг і т.д. Результати ранжування представлені в табл. 2.4, що має бути наведеною у курсовому проекті.
Таблиця 2.4