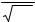Обработка эксперим данных Роганов
.pdfкритериев, называемых критериями согласия, составляет одну из важных задач математической статистики.
Рассмотрим случай простой гипотезы H = (FX (x)= F (x)). Пусть
X1, X2 , ..., Xn – случайная выборка, т.е. наблюдаемые значения случайной величины Х, и пусть Fn* (x) эмпирическая функция распределения выборки.
Определим некоторую неотрицательную меру D отклонения
эмпирической |
функции |
распределения |
Fn* (x) от предполагаемой |
(теоретической) |
функции |
распределения |
F(x) D = D(Fn* , F ). Величину D |
можно определить многими способами, в соответствии с которыми получаются различные критерии для проверки интересующей нас гипотезы. Например, можно положить
|
D(F* , F )= sup |
|
F* (x)− F(x) |
|
|
|
|
|
|
||||
|
n |
x |
|
n |
|
|
или |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
D(Fn* , F )= ∞∫[Fn* (x)− F(x)]2k g(x)dx |
|||||
|
|
−∞ |
||||
где g(x)> 0, |
∞∫g(x)dx < ∞ . В первом случае для проверки данной гипотезы |
|||||
|
−∞ |
|
|
|
|
|
получим критерий Колмогорова, во втором случае (при k =1) – критерий ω2
Мизеса.
Величины X1, X2 , ..., Xn, образующие выборку, в случае справедливости выдвинутой гипотезы можно рассматривать как независимые одинаково распределенные случайные величины с функцией распределения
F(x). Но тогда величина D, как бы она ни была определена, является функцией от случайных величин и поэтому сама есть величина случайная.
|
Предположим, что выдвинутая гипотеза верна, т.е. FX (x)= F(x). Тогда |
|
распределение случайной величины |
D может быть найдено. Зададим число |
|
ε > 0 |
столь малое, что можно |
считать практически невозможным |
111