

шпорки инф
.docx
|
№1 Предмет и задачи информатики Информатика- фундаментальная естественная наука, изучающая общие свойства информации, процессы, методы и средства её обработки. Предметом изучения информатики является информация. Предмет информатики как науки составляют:
Задачи информатики: Иссследование информационных процессов любой природы. Разработка информационной техники и создание новейшей технологии переработки информации на базе полученных результатов исследований информационных процессов. Решение научных и инженерных проблем создания, внедрения и обеспечения эффективного использования компьютерной техники и технологии во всех сферах общественной жизни.
|
№2 Информация: определение, виды и свойства Информация — это сведения об объектах и явлениях окружающей среды, их параметрах, свойствах и состояниях, которые уменьшают имеющуюся о них степень неопределенности, неполноты знаний. Информатика рассматривает информацию как связанные между собой сведения, изменяющие наши представления о явлении или объекте окружающего мира. С этой точки зрения информацию можно рассматривать как совокупность знаний о фактических данных и зависимостях между ними. Информация:
Свойства информации: точность, ценность, своевременность, доступность, адекватность, актуальность, устность, полезность, защищенность
|
||||||||||||||||
|
№3 Информационные процессы Информационный процесс - совокупность последовательных действий (операций), производимых над информацией (в виде данных, сведений, фактов, идей, гипотез, теорий и пр.), для получения какого-либо результата (достижения цели Наиболее обобщенными информационными процессами являются сбор, преобразование, использование информации. К основным информационным процессам, изучаемым в курсе информатики, относятся: поиск, отбор, хранение, передача, кодирование, обработка, защита информации. Компьютер является универсальным устройством для автоматизированного выполнения информационных процессов.
|
№4 Информационные технологии Информационные технологии (ИТ, от англ. information technology, IT) — это класс областей деятельности, относящихся к технологиям управления и обработкой огромного потока информации с применением вычислительной техники. Согласно определению, принятому ЮНЕСКО, Информационные Технологии (ИТ) — это комплекс взаимосвязанных научных, технологических, инженерных наук, изучающих методы эффективной организации труда людей, занятых обработкой и хранением информации с помощью вычислительной техники и методы организации и взаимодействия с людьми и производственным оборудованием, их практические применение, а также связанные со всем этим социальные, экономические и культурные проблемы. Основные черты современных ИТ: -компьютерная обработка информации; -хранение больших объёмов информации на машинных носителях; -передача информации на любые расстояния в кротчайшие сроки.
|
||||||||||||||||
|
№5
Термин информационная система (ИС) используется как в широком, так и в узком смысле. В широком смысле информационная система есть совокупность технического, программного и организационного обеспечения, а также персонала, предназначенная для того, чтобы своевременно обеспечивать надлежащих людей надлежащейинформацией[1]. Также в достаточно широком смысле[2] трактует понятие информационной системы Федеральный закон РФ от 27 июля 2006 года № 149-ФЗ «Об информации, информационных технологиях и о защите информации»: «информационная система — совокупность содержащейся в базах данных информации и обеспечивающих ее обработку информационных технологий итехнических средств»[3]. В узком смысле информационной системой называют только подмножество компонентов ИС в широком смысле, включающеебазы данных, СУБД и специализированные прикладные программы. ИС в узком смысле рассматривают как программно-аппаратную систему, предназначенную для автоматизации целенаправленной деятельности конечных пользователей, обеспечивающую, в соответствии с заложенной в нее логикой обработки, возможность получения, модификации и хранения информации[6]. В любом случае основной задачей ИС является удовлетворение конкретных информационных потребностей в рамках конкретной предметной области. Современные ИС де-факто немыслимы без использования баз данных и СУБД, поэтому термин «информационная система» на практике сливается по смыслу с термином «система баз данных».
|
№6 Информация. Меры Информации. Меры информации:
|
||||||||||||||||
|
№7 Информация. Меры Информации. Меры информации:
|
№8 Семантическая мера информации. Тезаурус Семантическая(смысловая) мера информации используется для измерения смыслового содержания информации. Наибольшее распространение здесь получила тезаурусная мера, связывающая семантические свойства информации со способностью пользователя принимать поступившее сообщение. Тезаурус — это совокупность сведений, которыми располагает пользователь или система. Максимальное количество семантической информации потребитель получает при согласовании ее смыслового содержания со своим тезаурусом, когда поступающая информация понятна пользователю и несет ему ранее не известные сведения. С семантической мерой количества информации связан коэффициент содержательности, определяемый как отношение количества семантической информации к общему объему данных.
|
||||||||||||||||
|
№9 Синтаксическая мера информации. Структурный подход Хартли к измерению количества информации. Синтаксические меры информации. Объем данных в сообщении измеряется количеством символов (разрядов) принятого алфавита в этом сообщении. Часто информация кодируется числовыми кодами в той или иной системе счисления. Естественно, что одно и то же количество разрядов в разных системах счисления способно передать разное число состояний отображаемого объекта. Подход Хартли к измерению количества информации: Степень неопределености определяется возможным числом состояний системы. Задачи: 4 возможных масти, 4 возможных оценки, 4 возможных угла. Любой из 4 ответов равновероятен,его вероятность ¼. Одинаковая вероятность ответов обуславливает и равную неопределенность,снимаемую ответом,след.каждый ответ несет одинаковую информацию. Формула Хартли: I = log 2 N ;если количество возможных сообщений во множестве возможных сообщений равно N ,то количество информации I приходящееся на 1 сообщение определяется log общего числа возможных сообщений.
|
№10 Основы теории вероятностей. Р(А)= где Р(А)-вероятность события А, m-число случаев благоприятных событию А, n-общее число случаев. Эта формула применима для несовместных равновозможных событий, образующих полную группу. Эти события называются случаями. Свойства вероятности:
|
||||||||||||||||
|
№11 Статистический подход Шеннона к измерению количества информации. Сравним 2 объекта: коробку, в которой находятся 999 черных и 1 белый шар и коробку, в которой находятся 500 белых и 500 черных шаров. любая информация приводит к снятию некоторой доопытной неопределенности. В 1 случае сообщение для получателя почти полностью определено, он не осуществлял опыта, знал, что извлечет черный шар, поэтому сообщение о его извлечении несет количество информации близкое к 0. вероятность таких сообщений близка к 1,поэтому среднее количество информации на 1 сообщение будет мало. Во 2 случае, когда предсказания об исходе опыта невозможно, сообщение о событии несет значительно больше информации для получателя. Суть: изложенные соображения приводят к необходимости учитывать при определении количества информации не только количество разных сообщений от источника, но и вероятность получения тех или иных сообщений. Именно это положено в основу статистического подхода Шеннона к определению количества информации.
|
№12 Понятие энтропии Энтропия- мера неопределенности состояния некоторой системы. Кол-во информации измеряется уменьшением энтропии той системы, для уточнения которой предназначены сведения. .
|
||||||||||||||||
|
№13 Энтропия и информация. Формула Шеннона. Энтропией системы называется сумма произведений вероятностей различных состояний системы на логарифм их вероятностей.
|
№14 Единицы измерения информации Бит – слишком мелкая единица измерения. На практике чаще применяется более крупная единица – байт, равная восьми битам. Именно восемь битов требуется для того, чтобы закодировать любой из 256 символов алфавита клавиатуры компьютера (256=28). Широко используются также еще более крупные производные единицы информации: 1 Килобайт (Кбайт) = 1024 байт = 210 байт, 1 Мегабайт (Мбайт) = 1024 Кбайт = 220 байт, 1 Гигабайт (Гбайт) = 1024 Мбайт = 230 байт. В последнее время в связи с увеличением объемов обрабатываемой информации входят в употребление такие производные единицы, как: 1 Терабайт (Тбайт) = 1024 Гбайт = 240 байт, 1 Петабайт (Пбайт) = 1024 Тбайт = 250 байт. За единицу информации можно было бы выбрать количество информации, необходимое для различения, например, десяти равновероятных сообщений. Это будет не двоичная (бит), а десятичная (дит) единица информации.
|
||||||||||||||||
|
№15Представление числовой информации в ПК. Форматы представления целых чисел в ПК Для представления целых чисел в ПК используется двоичная СС, базис которой 0 и 1. Двоичный разряд является наименьшей единицей хранения информации в ПК и называется битом. 8 последовательных бит образуют байт. Целые и дробные числа в компьютере представляются по-разному. Для представления чисел в памяти ПК используются два формата:
Различают следующие типы целых чисел:
|
№16Способы кодирования информации Существует 2 основных способа кодирования целых чисел в компьютере:
Способы кодирования информации:
Код – это система условных знаков для представления информации. Кодирование – переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки. Декодирование – действия по восстановлению первоначальной формы представления информации. Для декодирования нужен код.
|

 1
1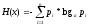
|
№17)Выполнение основных арифметических операций в дополнительных кодах.Примеры. 18) Прямой и дополнительный код целого числа в памяти компьютера. Примеры. Прямой код – это представление числа в двоичной системе счисления, при котором первый (старший) разряд отводится под знак числа. Если число положительное, то в левый разряд записывается 0; если число отрицательное, то в левый разряд записывается 1. Таким образом, в двоичной системе счисления, используя прямой код, в восьмиразрядной ячейке (байте) можно записать семиразрядное число. Например: 0 00011010 - положительное число 1 00011010 – отрицательное число Абсолютная часть числа записывается в двоичном поле справа налево. Прямой код редко используется т.к. тратится разряд для хранения знака числа, диапазон представления чисел сужается. Пример: Представить число -129 в прямом коде в формате integer . 1)129
2) Записываем в формате integer
Количество значений, которые можно поместить в семиразрядной ячейке со знаком в дополнительном разряде равно 256. Это совпадает с количеством значений, которые можно поместить в восьмиразрядную ячейку без указания знака. Однако диапазон значений уже другой, ему принадлежат значения от -128 до 127 включительно (при переводе в десятичную систему счисления). Дополнительный код В дополнительном коде, также как и прямом, первый разряд отводится для представления знака числа. Прямой код используется для представления положительных чисел, а дополнительный – для представления отрицательных. Поэтому, если в первом разряде находится 1, то мы имеем дело с дополнительным кодом и с отрицательным числом. Все остальные разряды числа в дополнительном коде сначала инвертируются, т.е. заменяются противоположными (0 на 1, а 1 на 0). Например, если 1 0001100 – это прямой код числа, то при формировании его дополнительного кода, сначала надо заменить нули на единицы, а единицы на нули, кроме первого разряда. Получаем 1 1110011. Но это еще не окончательный вид дополнительного кода числа. Далее следует прибавить единицу к получившемуся инверсией числу: 1 1110011 + 1 = 1 1110100 В итоге и получается число, которое принято называть дополнительным кодом числа. Причина, по которой используется дополнительный код числа для представления отрицательных чисел, связана с тем, что так проще выполнять математические операции. Например, у нас два числа, представленных в прямом коде. Одно число положительное, другое – отрицательное и эти числа нужно сложить. Однако просто сложить их нельзя. Сначала компьютер должен определить, что это за числа. Выяснив, что одно число отрицательное, ему следует заменить операцию сложения операцией вычитания. Потом, машина должна определить, какое число больше по модулю, чтобы выяснить знак результата и определиться с тем, что из чего вычитать. В итоге, получается сложный алгоритм. Куда проще складывать числа, если отрицательные преобразованы в дополнительный код. Это можно увидеть на примерах ниже. Операция сложения положительного числа и отрицательного числа, представленного в прямом коде Прямой код числа 5: 0 000 0101 Прямой код числа -7: 1 000 0111 Два исходных числа сравниваются. В разряд знака результата записывается знак большего исходного числа. Если числа имеют разные знаки, то вместо операции сложения используется операция вычитания из большего по модулю значения меньшего. При этом первый (знаковый) разряд в операции не участвует. _ 000 0111 000 0101 ------------- 000 0010 После выполнения операции учитывается первый разряд. Результат операции 1 000 0010, или -210. Операция сложения положительного числа и отрицательного числа, представленного в дополнительном коде Прямой код числа 5: 0 000 0101 Прямой код числа -7: 1 000 0111 Формирование дополнительного кода числа -7. Прямой код : 1 000 0111 Инверсия : 1 111 1000 Добавление единицы: 1 111 1001 Операция сложения. 0 000 0101 + 1 111 1001 -------------- 1 111 1110 Проверка результата путем преобразования к прямому коду. Дополнительный код: 1 111 1110 Вычитание единицы : 1 111 1101 Инверсия : 1 000 0010 (или -210) Арифметические операции в двоичной системе счисления В двоичной системе счисления арифметические операции выполняются по тем же правилам, что и в десятичной системе счисления, т.к. они обе являются позиционными (наряду с восьмеричной, шестнадцатеричной и др.). Сложение Сложение одноразрядных двоичных чисел выполняется по следующим правилам: 0 + 0 = 0 1 + 0 = 1 0 + 1 = 1 1 + 1 = 10 В последнем случае, при сложении двух единиц, происходит переполнение младшего разряда, и единица переносится в старший разряд. Переполнение возникает в случае, если сумма равна основанию системы счисления (в данном случае это число 2) или больше его (для двоичной системы счисления это не актуально). Сложим для примера два любых двоичных числа: 1101 + 101 ------ 10010 Вычитание Вычитание одноразрядных двоичных чисел выполняется по следующим правилам: 0 - 0 = 0 1 - 0 = 1 0 - 1 = (заем из старшего разряда) 1 1 - 1 = 0 Пример: 1110 - 101 ---- 1001 Умножение Умножение одноразрядных двоичных чисел выполняется по следующим правилам: 0 * 0 = 0 1 * 0 = 0 0 * 1 = 0 1 * 1 = 1 Пример: 1110 * 10 ------ + 0000 1110 ------ 11100 Деление Деление выполняется так же как в десятичной системе счисления: 1110 | 10 |---- 10 | 111 ---- 11 10 ---- 10 10 ---- 0
|
№19 Представление целых и дробных чисел в памяти компьютера. Примеры. Для представления информации в ПК используется двоичная система счисления, базис которой 0 и 1. Двоичный разряд является наименьшей единицей хранения информации в комп называется битом.(binary digit - двоичный разряд) восемь последовательных бит образуют байт. биты в байте нумеруются справа налево начиная с нуля. Чаще всего рассматриваются последовательности 2, 4, 8 байтов. Целые и дробные числа представляются в памяти компьютера по разному. различают следующие типы целых чисел:
Дробные
числа представляются в памяти ПК в
форме "с плавающей точкой (плавающей
запятой)".
Пример: представить в
форме с плавающей точкой в 32-х разрядном
формате число -56,55
1) переводим число
в двоичную с/с
-56,55 =
11000010011000100011001100110011 Если в разрядной сетке мантиссы остаются свободные разряды, то они заполняются либо нулями, либо периодом дроби. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
№20 Представление алфавитно-цифровой информации. Современные вычислительные машины обрабатывают не только числовую, но и текстовую, иначе говоря, алфавитно-цифровую информацию, содержащую цифры, буквы, знаки препинания, математические и другие обозначения, называемые символами. > Существуют символы трех типов: цифры 0, 1, 2, . . .,9 буквы Аа, ВЬ, ... , Zz специальные символы . . . «+», «—», «•», «,», « = », пробел, «:», «;» Термин «буквенно-цифровая информация» относится и к цифрам, и к буквам, и к специальным символам. Совокупность символов, используемых каким-либо устройством, называется набором символов или алфавитом этого устройства. Именно такой характер имеет экономическая, планово-производственная, учетная, бухгалтерская, статистическая и другая информация, содержащая наименование предметов, фамилии людей и т. д. Характер этой информации таков, что для ее представления требуются слова переменной длины. Возможность ввода, обработки и вывода алфавитно-цифровой информации важна и для решения чисто математических задач, так как позволяет оформлять результаты вычислений в удобной форме — в виде таблиц с нужными заголовками и пояснениями. Чтобы иметь возможность представлять в ЭВМ информацию, выраженную символами алфавита, необходимо сами символы закодировать определенным образом. Код — это система символов, отображающих сообщение в данном алфавите. Все ЭВМ работают в двоичном коде (режиме). Существует несколько систем кодирования. В ЕС ЭВМ применяют четыре системы, одна из которых основана на представлении символов 7-разрядным двоичным кодом, две — 8-разрядным и 12-позиционная, которая предназначена для представления символов на 12-позиционных перфокартах. Наибольшее распространение получило представление алфавитно-цифровой информации посредством восьмиразрядного кода. Каждый код представляет одну двоичную цифру или один двоичный разряд, или один бит. Бит (binary digit — двоичная цифра) — двоичная единица количества информации. Байт принят в качестве основной единицы количества инфор-мации и представляет собой группу из восьми соседних двоичных разрядов (бит), которой вычислительная машина может оперировать как единым целым при передаче, хранении и обработке данных (информации). Цифровые вычислительные машины Единой системы относятся к символьно-ориентированным ЭВМ. При использовании каждой команды в соответствии с указаниями, содержащимися в ней, они обрабатывают по одному или по нескольку байтов информации. Каждый такой байт эквивалентен либо символу определенного входного языка, либо числу или его части в зависимости от его значения и системы счисления, в которой оно выражено. Байт был принят в качестве основной машинной единицы информации для того, чтобы возможно было создать системы машин, процесс обработки информации в которых был бы независим от размеров преобразуемых слов. Этот выбор обусловил внедрение единой иерархической структуры данных. В порядке увеличения количества разрядов эта структура содержит (рис. 34) фиксированные составные единицы (полуслово, слово, двойное слово) и информационную единицу переменной длины (поле). > Полуслово состоит из двух байт, слово — из четырех и двойное слово — из восьми (соответственно 16, 32 и 64 двоичных разрядов); поле может быть любой длины в пределах от 1 до 256 байт. В байте разряды нумеруются от 0 до 7, в полуслове — от О до 15, в слове — от 0 до 31, в двойном слове — от 0 до 63. |
№21 Представление графических данных в ПК. Как и любая другая информация в ЭВМ, графические изображения хранятся, обрабатываются и передаются по линиям связи в закодированном виде - т.е. в виде большого числа бит- нулей и единиц. Существует большое число разнообразных программ, работающих с графическими изображениями. В них используются самые разные графические форматы- т.е. способы кодирования графической информации. Расширения имен файлов, содержащих изображение, указывают на то, какой формат в нем использован, а значит какими программами его можно просмотреть, изменить (отредактировать), распечатать. Несмотря на все это разнообразие существует только два принципиально разных подхода к тому, каким образом можно представить изображение в виде нулей и единиц (растровая и векторная графика) ПРИ ИСПОЛЬЗОВАНИИ РАСТРОВОЙ ГРАФИКИ С ПОМОЩЬЮ ОПРЕДЕЛЕННОГО ЧИСЛА БИТ КОДИРУЕТСЯ ЦВЕТ КАЖДОГО МЕЛЬЧАЙШЕГО ЭЛЕМЕНТА ИЗОБРАЖЕНИЯ - ПИКСЕЛА. Изображение представляется в виде большого числа мелких точек, называемых пикселами. Каждый из них имеет свой цвет, в результате чего и образуется рисунок, аналогично тому, как из большого числа камней или стекол создается мозаика или витраж, из отдельных стежков- вышивка, а из отдельных гранул серебра- фотография. При использовании растрового способа в ЭВМ под каждый пиксел отводится определенное число бит, называемое битовой глубиной. Каждому цвету соответствует определенный двоичный код (т.е. код из нулей и единиц). Например, если битовая глубина равна 1, т.е. под каждый пиксел отводится 1 бит, то 0 соответствует черному цвету, 1 -белому, а изображение может быть только черно-белым. Если битовая глубина равна 2, т.е. под каждый пиксел отводится 2 бита, 00- соответствует черному цвету, 01- красному , 10 - синему , 11- черному , т.е. в рисунке может использоваться четыре цвета. Далее, при битовой глубине 3 можно использовать 8 цветов, при 4 - 16 и т.д. Поэтому, графические программы позволяют создавать изображения из 2, 4, 8, 16 , 32, 64, ... , 256, и т.д. цветов. Понятно, что с каждым увеличением возможного количества цветов (палитры) вдвое, увеличивается объем памяти, необходимый для запоминания изображения (потому что на каждый пиксел потребуется на один бит больше). ОСНОВНЫМ НЕДОСТАТКОМ РАСТРОВОЙ ГРАФИКИ ЯВЛЯЕТСЯ БОЛЬШОЙ ОБЪЕМ ПАМЯТИ, ТРЕБУЕМЫЙ ДЛЯ ХРАНЕНИЯ ИЗОБРАЖЕНИЯ. Это объясняется тем, что нужно запомнить цвет каждого пиксела, общее число которых может быть очень большим. Например, одна фотография среднего размера в памяти компьютера занимает несколько Мегабайт, т.е. столько же, сколько несколько сотен (а то и тысяч) страниц текста. ПРИ ИСПОЛЬЗОВАНИИ ВЕКТОРНОЙ ГРАФИКИ В ПАМЯТИ ЭВМ СОХРАНЯЕТСЯ МАТЕМАТИЧЕСКОЕ ОПИСАНИЕ КАЖДОГО ГРАФИЧЕСКОГО ПРИМИТИВА- ГЕОМЕТРИЧЕСКОГО ОБЪЕКТА (НАПРИМЕР, ОТРЕЗКА, ОКРУЖНОСТИ, ПРЯМОУГОЛЬНИКА И Т.П.), ИЗ КОТОРЫХ ФОРМИРУЕТСЯ ИЗОБРАЖЕНИЕ. В ЧАСТНОСТИ, ДЛЯ ОТРИСОВКИ ОКРУЖНОСТИ ДОСТАТОЧНО ЗАПОМНИТЬ ПОЛОЖЕНИЕ ЕЕ ЦЕНТРА, РАДИУС, ТОЛЩИНУ И ЦВЕТ ЛИНИИ. По этим данным соответствующие программы построят нужную фигуру на экране дисплея. Понятно, что такое описание изображения требует намного меньше памяти (в 10 - 1000 раз) чем в растровой графике, поскольку обходится без запоминания цвета каждой точки рисунка. ОСНОВНЫМ НЕДОСТАТКОМ ВЕКТОРНОЙ ГРАФИКИ ЯВЛЯЕТСЯ НЕВОЗМОЖНОСТЬ РАБОТЫ С ВЫСОКОКАЧЕСТВЕННЫМИ ХУДОЖЕСТВЕННЫМИ ИЗОБРАЖЕНИЯМИ, ФОТОГРАФИЯМИ И ФИЛЬМАМИ. Природа избегает прямых линий, правильных окружностей и дуг. К сожалению, именно с их помощью (поскольку эти фигуры можно описать средствами математики, точнее- аналитической геометрии) и формируется изображение при использовании векторной графики. Попробуйте описать с помощью математических формул, картины И.Е.Репина или Рафаэля! (Но не "Черный квадрат" К.Малевича!) ПОЭТОМУ ОСНОВНОЙ СФЕРОЙ ПРИМЕНЕНИЯ ВЕКТОРНОЙ ГРАФИКИ ЯВЛЯЕТСЯ ОТРИСОВКА ЧЕРТЕЖЕЙ, СХЕМ, ДИАГРАММ И Т.П. Как отличить векторную графику от растровой? Если Вы видите на экране фотографию или рисунок с близким к естественному изображением, с большим числом цветов и оттенков, то, скорее всего, Вы имеете дело с растровой графикой. Если чертеж, диаграмму, простой стилизованный рисунок,- с векторной. Если программа позволяет стирать, копировать или перемещать целые фрагменты (площади) изображения, то это растровая графика. Если удалить, скопировать, переместить можно только какие-то определенные фигуры или их части, то это графика векторная. Файлы *.bmp , *.pcx , *.gif , *.msp , *.img и др. соответствуют форматам растрового типа, *.dwg , *.dxf , *.pic и др. - векторного. Иногда, правда, растровые изображения могут входить в состав векторных как отдельные графические примитивы.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
№22 Особенности реализации вещественной компьютерной графики. Когда говорят о точности представления вещественных чисел, надо помнить следующее: десятичное число, имеющее даже всего одну значащую цифру после запятой, вообще говоря, невозможно записать точно в любом из вещественных типов. Объясняется это тем, что конечные десятичные дроби часто оказываются бесконечными периодическими двоичными дробями. Так, 0,110 = 0,0(0011)2, а, значит, и в нормализованном виде такое двоичное число будет иметь бесконечную мантиссу и не может быть представлено точно. При записи подобной мантиссы в ячейку компьютера число не усекается, а округляется. Если под мантиссу отведено n бит и n + 1-ая значащая цифра двоичной нормализованной мантиссы равна 0, то цифры начиная с n +1-ой просто отбрасываются, если же n + 1-ая цифра равна единице, то к целому числу, составленному из первых n значащих цифр мантиссы, прибавляется единица. Рассмотрим, как будет выглядеть запись мантиссы числа а = 0,110 при двоичной нормализации для различных значений количества разрядов, отведенных под мантиссу n. a = 0,110 = 0,0(0011)2 = 0,11(0011)2 × 2-3, т.е. мантисса в нормализованном числе есть 0,11(0011)2. При n = 10, m = 1100110011 (остальные цифры мантиссы отброшены в результате округления). При n = 12, m = 110011001101 (последняя цифра изменилась с 0 на 1 при округлении). При n = 13, m = 1100110011010 (две последних цифры изменились при прибавлении 1). Рассмотрим теперь ошибки, которые могут возникнуть при операциях сложения и вычитания (каждая возможная ошибка соответствует одному шагу алгоритма компьютерного сложения или вычитания вещественных чисел). 1)Потеря значащих цифр мантиссы у меньшего из чисел при выравнивании порядков. В худшем случае утерянными оказываются все значащие цифры и а + b = а, что является абсурдным с точки зрения математики, но возможным в компьютерной арифметике с ограниченным числом разрядов. 2)Потеря крайней справа значащей цифры результата при сложении или вычитании мантисс (при сложении и вычитании двух чисел количество значащих цифр может увеличиться лишь на одну). Это влияет на точность, но не на правильность результата. 3)Выход за границу допустимого диапазона значения того или иного вещественного типа при нормализации результата. В данном случае получаемый порядок оказывается либо больше максимально возможного значения, либо меньше минимального. Данную ситуацию различные компиляторы и операционные системы обрабатывают по-разному, но чаще всего выполнение программы прерывается с сообщением об ошибке: "арифметическое переполнение". |
№23 Представление звука в ПК. Современные компьютеры «умеют» сохранять и воспроизводить звук (речь, музыку и пр.) Звук, как и любая другая информация, представляется в памяти ЭВМ в форме двоичного кода. Основной принцип кодирования звука, как и кодирования изображения, выражается словом «дискретизация». При кодировании изображения дискретизация — это разбиение рисунка на конечное число одноцветных элементов — пикселей. И чем меньше эти элементы, тем меньше наше зрение замечает дискретность рисунка. Физическая природа звука — это колебания в определенном диапазоне частот, передаваемые звуковой волной через воздух (или другую упругую среду). Аудиоадаптер (звуковая плата) — специальное устройство, подключаемое к компьютеру, предназначенное для преобразования электрических колебаний звуковой частоты в числовой двоичный код при вводе звука и для обратного преобразования (из числового кода в электрические колебания) при воспроизведении звука. В процессе записи звука аудиоадаптер с определенным периодом измеряет амплитуду электрического тока и заносит в регистр двоичный код полученной величины. Затем полученный код из регистра переписывается в оперативную память компьютера. Качество компьютерного звука определяется характеристиками аудиоадаптера: частотой дискретизации и разрядностью. Частота дискретизации — это количество измерений входного сигнала за 1 секунду. Частота измеряется в герцах (Гц). Одно измерение за 1 секунду соответствует частоте 1 Гц. Разрядность регистра — число бит в регистре аудиоадаптера. Разрядность определяет точность измерения входного сигнала. Чем больше разрядность, тем меньше погрешность каждого отдельного преобразования величины электрического сигнала в число и обратно. Если разрядность равна 8 (16), то при измерении входного сигнала может быть получено 28 = 256 (216 = 65536) различных значений. Очевидно, 16-разрядный аудиоадаптер точнее кодирует и воспроизводит звук, чем 8-разрядный. Пример. Определить размер (в байтах) цифрового аудиофайла, время звучания которого составляет 10 секунд при частоте дискретизации 22,05 кГц и разрешении 8 бит. Файл сжатию не подвержен. Решение. Формула для расчета размера (в байтах) цифрового аудиофайла (монофоническое звучание): (частота дискретизации в Гц) х ( время записи в сек) х (разрешение в битах)/8. Таким образом, размер файла вычисляется так: 22050 х 10 х 8/8 = 220 500 байт.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
№24 Методы сжатия данных а ПК. Сжатие информации – это процесс преобразования информации, хранящейся в файле, к виду, при котором уменьшается избыточность в ее представлении и соответственно требуется меньший объем памяти для хранения; процесс сокращения количества битов, необходимых для хранения и передачи некоторого объема информации. Существует сжатие без потерь, когда информация, восстановленная из сжатого сообщения, в точности соответствует исходной (применяется при обработке текстов, записанных на естественном или искусственном языках), и сжатие с потерями (необратимое), когда восстановленная информация только частично соответствует исходной (применяется при обработке изображений и звука, для цифровой записи аналоговых сигналов). Основные способы сжатия: статистический и словарный. При первом каждому символу присваивается код, основанный на вероятности его появления в тексте. Высоко вероятные символы получают короткие коды и наоборот. Одним из самых ранних и широко известных статистических методов является алгоритм Хаффмана, при котором символы заменяются кодом, состоящим из целого количества битов. Позднее он был вытеснен арифметическим кодированием, имеющим схожую с кодом Хаффмана функцию и основанным на идее кодирования символов дробным числом битов. Арифметическое сжатие может быть использовано в тех случаях, когда степень сжатия важнее, чем временные затраты на сжатие информации. При словарном способе группы последовательных символов или "фраз" заменяются кодом. Замененная фраза может быть найдена в некотором словаре. Одним из наиболее простых и наглядных является метод сжатия последовательностей одинаковых символов, не относящийся к названным основным методам. Метод основан на представлении последовательности одинаковых символов в виде двух величин K и S, где K - количество повторяющихся символов, S - код этого символа. Основным недостатком данного метода является то, что он обеспечивает сжатие лишь в случае, когда в исходном файле основную часть составляют повторяющиеся символы. В противном случае сжатый файл может занимать больше места, чем исходный неуплотненный файл. Наиболее эффективно метод сжатия последовательностей одинаковых символов работает в случае двоичных файлов. Синтетические алгоритмы. Рассмотренные выше алгоритмы в «чистом виде» на практике не применяются из-за того, что эффективность каждого из них сильно зависит от начальных условий. В связи с этим, современные средства архивации, используют более сложные алгоритмы, основанные на комбинации нескольких теоретических методов. Общим принципом в работе таких «синтетических» алгоритмов является предварительный просмотр и анализ исходных данных для индивидуальной настройки алгоритма на особенности обрабатываемого материала. |
№25 Понятие и классификация с/с. Форма представления определяет порядок записи числа с помощью предназначенных для этого знаков. при этом значение числа является ин-вариантом, т.е. не зависит от способа его представления. способ представления числа определяется с/с. С/с - правило записи чисел с помощью набора знаков, называемых цифрами. q, основание - натуральное число, определяющее кол-во знаков, используемых для записи чисел. А, алфавит(базис) - множество знаков, используемых для записи чисел. Классификация с/с: 1 вариант: а- позиционные; б- непозиционные; в- смешанные. (Римская с/с) 2 вариант: А- позиционные; б- непозиционные. (Унарная, римская). №26 Порядок представления чисел в позиционной и непозиционной с/с. Системой счисления называется знаковая система, в которой числа записываются по определенным правилам с помощью символов некоторого алфавита, называемых цифрами. В непозиционных системах вес цифры не зависит от ее позиции в записи числа.Пример непозиционной системы счисления - римская система, в которой в качестве цифр используются латинские буквы: IVXLCDM В позиционных системах счисления вес каждой цифры изменяется в зависимости от ее положения (позиции) в последовательности цифр, изображающих число. Десятичная система счисления является позиционной. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
№27 Переводы целых и дробных чисел из десятичной с/с в недесятичные. Примеры. 1 способ заключается в разбиении числа на степени основания той системы, в которую выполняется перевод. этот способ пригоден для небольших чисел.
2 способ- основной - заключается в последовательном делении исходного десятичного числа на основание той системы, в которую выполняется перевод. Перевести число 344 из десятичной системы в двоичную. Решение:
|
№28 Перевод чисел из недесятичной в десятичную. Примеры. для перевода числа в десятичную с/с необходимо проделать след. действия: 1) записать исходное число в полиномиальной форме 2)выполнить необходимые мат. операции (возвед. в степень, умножение, сложение) Пример: F45ED23C16 = (15·167)+(4·166)+(5·165)+(14·164)+(13·163)+(2·162)+(3·161)+(12·160) = 409985490810 101101102 = (1·27)+(0·26)+(1·25)+(1·24)+(0·23)+(1·22)+(1·21)+(0·20) = 128+32+16+4+2 = 18210 23578 = (2·83)+(3·82)+(5·81)+(7·80) = 2·512 + 3·64 + 5·8 + 7·1 = 126310 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
№29 Специальные приемы перевода. Примеры.
|
№30 Понятие высказывания. виды высказываний. формализация высказываний. понятие логических переменных, констант и логических связок. Под высказыванием обычно понимают всякое повествовательное предложение, утверждающее что-либо о чем-либо, и при этом мы можем сказать, истинно оно или ложно в данных условиях места и времени. Логическими значениями высказываний являются «истина» и «ложь» Пpиведем пример высказываний: Санкт –Петербург стоит на Неве Париж — столица Англии Карась не рыба Число 6 делится на 2 и на 3 Если юноша окончил среднюю школу, то он получает аттестат зрелости, высказывания 1), 4), 5) истинны, а высказывания 2) и 3) ложны. Очевидно, предложение «Да здравствуют наши спортсмены!» не является высказыванием. Различают два вида высказываний: Высказывание, представляющее собой одно утверждение, принято называть простым, или элементарным. Примерами элементарных высказываний могут служить высказывания 1) и 2). Высказывания, которые получаются из элементарных с помощью грамматических связок «не», «и», «или», «если .... то ...», «тогда и только тогда», принято называть сложными, или составными. Формализованная информационная модель — это определенные совокупности знаков (символов), которые существуют отдельно от объекта моделирования, могут подвергаться передаче и обработке. Реализация информационной модели на компьютере сводится к ее формализации в форматы данных, с которыми "умеет" работать компьютер.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
№31 Логические операции над высказываниями. Конъюнкция - логическое умножение (&, * , ^) связка (и, and)
Дизъюнкция - логическое сложение (v, +) связка (или, or)
Отрицание
- логическая операция, которая с помощью
связки «не» каждому исходному
высказыванию ставит в соответствие
составное высказывание, заключающееся
в том, что исходное высказывание
отрицается.
(¬,
Высказывание, составленное из двух высказываний при помощи связки «если ..., то ...», называется логическим следованием, импликацией (-->)
Высказывание, составленное из двух высказываний при помощи связки «тогда и только тогда, когда», называется эквивалентностью. (~)
Строгая
дизъюнкция (
|
№32 Табличное определение логических операций. Вычисление значений истинности формул логики высказываний. Пример. Из элементарных высказываний можно составить более сложные с помощью логических связок , , , , , называемых соответственно отрицание, логическое и (конъюнкция), логическое или (дизъюнкция), логическое следствие (импликация), эквивалентность и круглых скобок (, ). Семантику логических связок можно представить с помощью таблицы истинности. В левой части этой таблицы перечисляются все возможные комбинации значений логических переменных. В правой части – соответствующие им значения новых выражений, полученных из переменных и связок.
Связки имеют следующий приоритет: . Приоритет операций, представленных логическими связками можно изменить с помощью скобок. Высказывания, построенные с помощью простых высказываний, связок и скобок, называют правильно построенными формулами или сокращённо формулами. Замечательным свойством логики высказываний является то, что ее семантика близка к соответствующим высказываниям на естественном языке. Так, например семантика формул содержащих связки и практически совпадает со смыслом фраз содержащих слова «не» и «и». Однако имеются и некоторые различия. Так формула х у несколько шире, чем русское «х или у». Выражение «х или у» по смыслу ближе к формуле х у х у. Еще больше различий между семантикой формулы х у в логике высказываний и выражению «из х следует у». В русском языке это выражение истинно, если истинны х и у, т.е. предложение русского языка по смыслу совпадает с формулой х у. Логическое следствие истинно также, если х и у ложны или х ложна, а у истинна. Логическую формулу х у следует интерпретировать на естественном языке так: «Если х истинна, то у тоже истинна, а остальное неизвестно». Для любой формулы также можно построить таблицу истинности. Например, для формулы таблица истинности будет выглядеть следующим образом:
Очевидно, что если формула содержит n переменных, то в таблице истинности будет содержаться 2n строк. В приведенном примере формула содержит 2 переменные и 22 = 4 строки. Кроме того, данная формула истинна на любом наборе значений своих переменных. Такие формулы называются тождественно истинными или тавтологиями. В противоположной ситуации, формула является тождественно ложной или невыполнимой. Если две разные формулы принимают одинаковые значения на любом наборе значений переменных, то такие формулы называют равносильными. Равносильные формулы будем обозначать знаком равенства =.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
№33 Равносильные
преобразования логических формул.
Примеры.
Две
формулы алгебры логики А и В называются
равносильными, если
они принимают одинаковые логические
значения на любом наборе значений
входящих в них высказываний
(А
II. Равносильности, выражающие одни логические операциичерез другие:
1.
2.
3.
4.
5.
6.
1.
2.
3.
4.
5.
6. Используя равносильности группы I, II и III, можно часть формул алгебры логики или всю формулу заменить равносильной ей формулой. Такие преобразования называются равносильными. Равносильные преобразования формул применяются для доказательства равносильностей, для приведения формул к заданному виду, для упрощения формул. Пример. Доказать тождественную истинность формулы:
|
№34 Понятие и формы представления булевской функции. (Булева функция). Булевой функцией от n аргументов называется функция f из n-ой степени множества { 0, 1 } в множество { 0, 1 }.Иначе говоря, булева функция – это функция, и аргументы и значение которой принадлежит множеству { 0, 1 }. Множество { 0, 1 } мы будем в дальнейшем обозначать через B. Булеву функцию от n аргументов можно рассматривать как n-местную алгебраическую операцию на множестве B. При этом алгебра <B;>, где – множество всевозможных булевых функций, называется алгеброй логики. Конечность области определения функции имеет важное преимущество – такие функции можно задавать перечислением значений при различных значениях аргументов. Для того, чтобы задать значение функции от n переменных, надо определить значения для каждого из 2nнаборов. Эти значения записывают в таблицу в порядке соответствующих двоичных чисел. В результате получается таблица следующего вида:
Раз у нас есть стандартный порядок записывания наборов, то для того, чтобы задать функцию, нам достаточно выписать значенияf(0,0,...,0,0), f(0,0,...,0,1), f(0,0,...,1,0), f(0,0,...,1,1),..., f(1,1,...,0,0), f(1,1,...,0,1), f(1,1,...,1,0), f(1,1,...,1,1). Этот набор называют вектором значений функции. Таким образом, различных функций n переменных столько, сколько различных двоичных наборов длины 2n*. А их 2 в степени 2n. Множество B содержит два элемента – их можно рассматривать как булевы функции от нуля (пустого множества) переменных – константу 0 и константу 1. Функций от одной переменной четыре: это константа 0, константа 1, тождественная функция, т.е. функция, значение которой совпадает с аргументом и так называемая функция ``отрицание''. Отрицание будем обозначать символом ¬ как унарную операцию. Приведём таблицы этих четырёх функций:
Как видим, функции от некоторого числа переменных можно рассматривать как функции от большего числа переменных. При этом значения функции не меняется при изменении этих ``добавочных'' переменных. Такие переменные называются фиктивными, в отличие от остальных –существенных.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


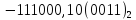 2)
нормализуем мантиссу:
-1,1100010(0011)*
2)
нормализуем мантиссу:
-1,1100010(0011)* 3)
вычисляем характеристику
127+5=1111111+101=
3)
вычисляем характеристику
127+5=1111111+101=
 Алгоритм
перевода правильной десятичной дроби
будет следующим:
1. Последовательно
выполнять умножение исходной десятичной
дроби и получаемых дробных частей
произведений на основание системы до
тех пор, пока не получится нулевая
дробная часть или не будет достигнута
требуемая точность вычислений.
2.
Записать полученные целые части
произведения в прямой последовательности.
Алгоритм
перевода правильной десятичной дроби
будет следующим:
1. Последовательно
выполнять умножение исходной десятичной
дроби и получаемых дробных частей
произведений на основание системы до
тех пор, пока не получится нулевая
дробная часть или не будет достигнута
требуемая точность вычислений.
2.
Записать полученные целые части
произведения в прямой последовательности. )
связка(не, not)
)
связка(не, not)
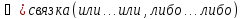
 В
В