

Нов.ПМС-2
.pdfОбъединяя внутренние суммы квадратов для всех серий повторных опытов, мы получим общую сумму квадратов «чистых» ошибок в виде
m n
(Yju Yj )2 j 1 u 1
со степенями свободы
m |
m |
ne (n j |
1) = n j m . |
j 1 |
j 1 |
Отсюда средний квадрат «чистых» ошибок равен
|
|
m |
n |
|
|
|
|
(Y ju Y j )2 |
|||
s 2 |
|
j 1 |
u 1 |
||
e |
|
|
m |
||
|
|
|
n j m |
||
j1
ион служит оценкой 2 независимо от того, корректна ли подобранная модель. Словом, эта величина – полная SS между повторениями, деленная на общее число степеней свободы.
Замечание.
Если имеются два наблюдения Y j1 и Y j 2 в точке X j , то
2 |
|
|
|
|
1 |
|
|
|
(Yju |
|
|
|
|
(Yj1 Yj 2 )2 . |
|
||
Yj )2 |
|
(9.28) |
||||||
2 |
||||||||
u 1 |
|
|
|
|
|
|
||
|
|
|
|
|
|
|
||
Это удобная форма для вычислений. Такая SS имеет только одну степень свободы.
Таким образом, сумма квадратов «чистых» ошибок фактически оказывается частью остаточной суммы квадратов, что мы и покажем.
Остаток для u -го наблюдения при X j можно записать
в виде: |
|
|
|
|
|
|
|
|
|
|
|
|
|
Yju Yj |
(Yju Yj ) (Yj |
Yj ) . |
||||
Здесь мы пользуемся тем обстоятельством, что все повторные точки при любом X j имеют одно и то же предсказанное
121

значение Y j . Если мы возведем в квадрат обе части этого
выражения, |
а затем |
просуммируем |
их по |
u и по j , то |
|||||||
получим: |
|
|
|
|
|
|
|
|
|
|
|
m n |
|
m |
n |
|
|
|
m |
|
|
|
|
(Yju |
)2 = (Yju |
|
|
|
|
|
|
|
|||
Yj |
Yj )2 n j (Yj |
Yj )2 , (9.29) |
|||||||||
j 1 u 1 |
|
j 1 u 1 |
|
|
|
j 1 |
|
|
|
|
|
причем парные произведения исчезают при суммировании по u для каждого j . Слева в уравнении (9.29) стоит остаточная
сумма квадратов. Первый член в правой части – это сумма квадратов «чистых» ошибок. Последний член мы называем суммой квадратов неадекватности. Отсюда следует, что сумму квадратов, обусловленную «чистой» ошибкой, можно ввести в
таблицу дисперсионного анализа, как это показано на рис. 9.5.
SS1 связанная с неадекватностью, находится по разности, nr- ne степеней свободы
Остаточная SS1 n2-степеней свободы Разлагается на:
SS1 связанная с «чистой» ошибкой по повторным опытам, ne степеней свободы
Оценка σ2 , если модель корректна; σ2 - смещение, если модель не корректна
Приводит к MSL - среднему квадрату, обусловленному неадекватностью
Сравнение
Приводит к Se2 – среднему квадрату,
обусловленному «чистой» ошибкой
Оценка σ2
|
Рис. 9.5 |
|
Затем производится сравнение отношения F MSL |
se2 |
|
со 100 (1 ) % точкой |
F -распределения при (n ne ) и |
ne |
степенях свободы. Если это отношение является:
1) значимым, то это показывает, что модель, повидимому, неадекватна и следует изучить, когда и как встречается неадекватность.
122
2) не значимым, то это показывает, что, по-видимому, оснований сомневаться в адекватности модели нет, и что как средний квадрат, связанный с «чистой» ошибкой, так и средний квадрат, обусловленный неадекватностью, могут
использоваться как оценки 2 .
Объединенная оценка 2 может быть получена из суммы квадратов, связанной с «чистой» ошибкой, и суммы квадратов, связанной с неадекватностью, путем объединения их в остаточную сумму квадратов и деления ее на остаточное
число степеней свободы nr , что дает s2 SS nr .
nr .
Если используются не повторные опыты в качестве повторных, то s 2 будет проявлять склонность к переоценке
2 , а F -критерий для проверки неадекватности будет иметь тенденцию к ошибочному определению ее отсутствия
Пример на иллюстрацию неадекватности и «чистой» ошибки
В табл. 9.3 представлены результаты 24 наблюдений. Таблица 9.3
Номер |
Y |
X |
Но- |
Y |
X |
Но- |
Y |
X |
наб- |
|
|
мер |
|
|
мер |
|
|
лю- |
|
|
наб- |
|
|
наб- |
|
|
дения |
|
|
лю- |
|
|
лю- |
|
|
|
|
|
дения |
|
|
дения |
|
|
1 |
2,3 |
1,3 |
9 |
1,7 |
3,7 |
17 |
3,5 |
5,3 |
2 |
1,8 |
1,3 |
10 |
2,8 |
4,0 |
18 |
2,8 |
5,3 |
3 |
2,8 |
2,0 |
11 |
2,8 |
4,0 |
19 |
2,1 |
5,3 |
4 |
1,5 |
2,0 |
12 |
2,2 |
4,0 |
20 |
3,4 |
5,7 |
5 |
2,2 |
2,7 |
13 |
5,4 |
4,7 |
21 |
3,2 |
6,0 |
6 |
3,8 |
3,3 |
14 |
3,2 |
4,7 |
22 |
3,0 |
6,0 |
7 |
1,8 |
3,3 |
15 |
1,9 |
4,7 |
23 |
3,0 |
6,3 |
8 |
3,7 |
3,7 |
16 |
1,8 |
5,0 |
24 |
5,9 |
6,7 |
По этим данным была оценена линия регрессии
123

Yi 1,436 0,338X i .
Рассчитаем данные для таблицы дисперсионного анализа. Сумма квадратов, обусловленная регрессией,
|
|
|
[ X iYi X i Yi |
n]2 |
||||||
|
|
2 |
|
|||||||
SS(b1 b0 ) (Yi |
Y ) |
= |
|
|
|
|
|
=6,326, |
||
2 |
( X i ) |
2 |
|
|||||||
|
|
|
|
|
|
X i |
|
n |
||
(число степеней свободы 1).
Общая (полная) скорректированная сумма квадратов есть sYY Yi 2 ( Yi )2  n =27,518,
n =27,518,
(число степеней свободы n 1=23);
sYY (Yi Y )2 =27,518; sYY Yi 2 nY 2 .
|
|
|
|
Остаток считается по формуле |
ei Yi |
Yi |
, для каждого |
наблюдения |
|
|
|
Yi |
считается по предложенной прямой Yi =1,436+0,338, |
|||||
а сумма квадратов для остатков считается по формуле |
||||||
|
|
n |
|
|
|
|
|
(Yi |
|
n 2 . |
|
||
ei |
Yi )2 со степенями свободы |
|
||||
|
|
i 1 |
|
|
|
|
|
|
|
|
|
|
|
Для |
примера |
SS (Yi Yi )2 |
=21,192 |
( n 2 =22); |
||
s2 SS (n 2) =0,963.
(n 2) =0,963.
Таблица 9.4 является таблицей дисперсионного анализа. Сумма квадратов:
1) связанная с ―чистой‖ ошибкой, из повторений при X 1,3
есть 12 (2,3 1,8)2 =0,125 с 1 степенью свободы (использована
формула (9.28);
2) связанная с ―чистой‖ ошибкой, из повторений при X 4,7 (считается по формуле (9.27)
(5,4)2 (3,2)2 (1,9)2 (5,4 3,2 1,9)2  3 = 43,01 36,75 =6,26с
3 = 43,01 36,75 =6,26с
2 степенями свободы.
124

Таблица 9.4
|
Число |
Суммы |
Сред- |
|
|
Источник |
степе- |
квадра- |
ние |
F -отноше- |
|
|
ней |
тов SS |
квадра- |
ние |
|
|
свободы |
|
ты MS |
|
|
|
|
|
|
MS |
– |
Регрессия |
1 |
6,326 |
6,326 |
средний. |
|
|
|
|
|
квадрат, |
|
|
|
|
|
обусловл. |
|
|
|
|
|
регресс- |
|
|
|
|
|
сией |
|
|
|
|
|
s 2 |
– |
|
|
|
|
средний |
|
Остаток |
22 |
21,192 |
0,963 |
квадрат, |
|
|
|
|
|
обуслов- |
|
|
|
|
|
ленный |
|
|
|
|
|
остаточ- |
|
|
|
|
|
ной |
вариа- |
|
|
|
|
цией |
|
Общий, |
|
|
|
F MS s 2 |
|
скорректи- |
|
|
|
=6,569 |
|
рованный |
23 |
27,518 |
|
||
|
значимо |
||||
|
|
|
|
||
|
|
|
|
при |
|
|
|
|
|
=0,05, |
|
|
|
|
|
если |
нет |
|
|
|
|
неадекват- |
|
|
|
|
|
ности |
|
Аналогичные вычисления дают следующие величины.
125
Таблица 9.5
Уро- |
|
|
|
|
Чис |
Уро- |
|
|
|
|
Число |
n |
|
|
|
ло |
n |
|
|
|
степе- |
||
|
(Y ju |
|
|
|
|
|
(Y ju |
|
|
|
|
вень |
Y j |
степ |
вень |
Y j )2 |
ней |
||||||
X |
u 1 |
|
|
|
еней |
X |
u 1 |
|
|
|
свобо- |
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
своб |
|
|
|
|
|
ды |
|
|
|
|
|
оды |
|
|
|
|
|
|
1,3 |
0,125 |
|
|
|
1 |
4,0 |
0,240 |
|
|
|
2 |
2,0 |
0,845 |
|
|
|
1 |
4,7 |
0,260 |
|
|
|
2 |
3,3 |
2,000 |
|
|
|
1 |
5,3 |
0,980 |
|
|
|
2 |
3,7 |
2,000 |
|
|
|
1 |
6,0 |
0,020 |
|
|
|
1 |
|
|
|
|
|
|
Итого |
12,470 |
|
|
|
11 |
Теперь полученные данные можно переписать в таблицу 9.6 дисперсионного анализа.
Таблица .9.6 Дисперсионный анализ (демонстрация неадекватности)
|
Чис |
Суммы |
Средние |
|
||
Источ- |
ло |
квадратов |
квадраты |
F - |
||
ник |
степеней |
SS |
MS |
отношение |
||
|
свобо- |
|
|
|
|
|
|
ды |
|
|
|
|
|
Регрессия |
1 |
6,326 |
6,326 |
|
||
Остаток |
22 |
21,192 |
s |
2 |
=0,963 |
|
|
|
|
|
|||
|
|
|
|
|
||
Неадекват |
11 |
8,722 |
MSL =0,793 |
|
||
-ность |
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
126

|
|
|
|
Продолжение табл.9.6 |
||
«Чистая» |
11 |
12,470 |
2 |
|
F MS s |
2 |
ошибка |
|
|
se |
=1,13 |
|
|
|
|
4 |
|
=6,569 |
|
|
|
|
|
|
|
||
|
|
|
|
значимо |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
=0,05 |
|
Общий, |
|
|
|
|
|
2 |
скоррек- |
23 |
27,518 |
|
|
F MSL se |
|
|
|
=0,699 |
|
|||
тирован- |
|
|
|
|
|
|
|
|
|
|
не значимо |
||
ный |
|
|
|
|
||
|
|
|
|
|
|
|
Неадекватность находится как разность
SSОСТАТОК – SSЧИТСАЯ ОШИБКА.
Отношение
F MSL 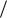 se2 =0,699
se2 =0,699
не значимо, так как оно меньше 1. Поэтому на основе такого критерия нет оснований сомневаться в адекватности нашей
модели и можно использовать s 2 =0,963 как оценку для 2 , чтобы иметь возможность воспользоваться F - критерием для проверки значимости всей регрессии. F - критерий состоятелен, только если нет неадекватности представления результатов нашей моделью
Итак, в итоге рассмотрим все необходимые действия, когда наши данные содержат повторные наблюдения.
1)Подобрать модель, составить простую таблицу дисперсионного анализа с двумя входами: регрессией и остатком. Но для общей регрессии пока не использовать F - критерий.
2)Вычислить сумму квадратов, связанную с ―чистой‖ ошибкой, и разложить остаточную сумму квадратов как на рис. 9.5.
127
3) Применить F - критерий для неадекватности. Если критерий неадекватности не значим, т.е. нет смысла сомневаться в адекватности модели, то перейти к пункту 4.б.
4.а) Значимая неадекватность. Прекратить анализ подобранной модели и искать пути ее улучшения методами анализа остатков. Не применять F - критерий для общей регрессии и не пытаться строить доверительные интервалы. Если нет адекватности подобранной модели, то не верны предпосылки, которые лежат в основе этих операций.
4.б) Неадекватность не значима. Снова объединить суммы квадратов для ‖чистых‖ ошибок и неадекватности в остаточную сумму квадратов. Использовать остаточный
средний квадрат |
s 2 в качестве оценки для D(Y ) 2 , |
применить F - |
критерий для общей регрессии, получить |
доверительные пределы для истинного среднего значения Y , вычислить R 2 и т.д.
Заметим, что если модель проходит все барьеры, это еще не означает, что она правильна, просто нет оснований считать ее неадекватной имеющимся данным. Если неадекватность обнаружена, то может понадобиться другая модель, возможно, квадратичная, вида
Y X X 2 .
На рис. 9.4 показаны некоторые ситуации, которые могут возникнуть, когда прямая строится по данным шаг за шагом.
Влияние повторных опытов на R2
Мы уже отмечали, что величина R 2 не может достичь 1, если есть повторные опыты. Никакая модель не может изменить вариацию, обусловленную ―чистой‖ ошибкой. В нашем последнем примере: сумма квадратов, обусловленная ―чистой‖ ошибкой, равна 12,470 при 11 степенях свободы. То, что модель подогнана к этим данным, не имеет значения, все равно величина 12,470 остается неизменяемой и
128
необъясняемой. Следовательно, максимум R 2 , достижимый при этих данных, есть
max R |
2 |
|
SS |
общая |
SSобусловл. |
= |
27,518 12,470 |
=0,5468, |
|
|
|
SSобщая |
|
27,518 |
|||||
|
|
|
|
|
|
|
|||
или 54,68 %. |
|
|
|
|
|
|
|||
То значение |
R 2 , которое |
фактически достигнуто для |
|||||||
подобранной модели, равно: |
|
|
|
||||||
R2 = SS РЕГР. / общаяSS скор = 6,326/27,518=0,2299, или 22,99 %,
Иными словами, мы можем объяснить 0,2299/0,5468=0,4202, или 42,02 % того, что возможно объяснить.
«Чистая» ошибка в многофакторном случае Полученные формулы для одной переменной применимы
в общем случае для n предикторов X1 , X 2 ,... . Но у повторных
опытов должны совпадать все координаты, т.е., например, следующие четыре отклика для четырех точек
( X1 , X 2 , X 3 , X 4 ) = (4,2,17,1), (4,2,17,1), (4,2,17,1), (4,2,17,1)
дают повторные опыты. Однако четыре точки
( X1 , X 2 , X 3 , X 4 ) = (4,2,16,1), (4,2,17,1), (4,2,18,1), (4,2,19,1)
уже не дают повторных опытов, поскольку координаты X 3 во всех этих случаях различны.
Корреляция между переменными X и Y и регрессия
Когда мы выдвигали постулат о линейности модели
Y 0 1 X ,
то мы предварительно полагали, что Y можно выразить как функцию 1-го порядка от X без учета ошибок.
В такой зависимости X обычно предполагается фиксированным (неслучайным), т.е. не имеющим вероятностного распределения, Y предполагается случайной величиной, имеющей распределение вероятностей со средним0 1 X и дисперсией D( ) .
129

Рассмотрим две случайные величины U |
и W с |
||
некоторым |
непрерывным |
совместным |
двумерным |
распределением вероятностей f (U ,W ) . Тогда мы определяем
коэффициент корреляции между ними как |
|
|
||||||
UW |
|
cov(U ,W ) |
|
, |
|
|
||
|
|
|
|
|
|
|||
|
|
|
|
|
|
|||
D(U )D(W ) |
|
|
||||||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
||
где cov(U ,W ) |
(U М (U ))(W М (W )) f (U ,W )dUdW , |
|||||||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
||
D(U ) (U М (U ))2 f (U ,W )dUdW , |
||||||||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
М (U ) Uf (U ,W )dUdW . |
|
|||||||
|
|
|
|
|
|
|
|
|
Значения D(W ) и М(W) определяются аналогично в терминах |
||||||||
W . Известно, что 1 UW 1. Величина |
UW |
служит мерой |
||||||
линейной зависимости между случайными величинами U и |
||||||||
W . Если имеется |
выборка |
объема |
n |
из величин |
||||
(U1 ,W1 ),...(U n ,Wn ) с совместным распределением, то величина
|
|
|
n |
|
|
|
|
|
|
|
|
|
|||
|
|
|
(U i U |
)(Wi W ) |
|||||||||||
rUW |
|
|
i 1 |
|
|
|
|
|
|
|
(9.30) |
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
n |
|
|
|
||||||||||||
|
|
|
|
n |
|
|
|||||||||
|
|
|
(U i U |
)2 |
|
|
(Wi W )2 |
||||||||
|
|
|
i 1 |
|
i 1 |
||||||||||
называется выборочным коэффициентом корреляции между U и W , оценивает UW и представляет собой эмпирическую
меру линейной зависимости между U и W . rUW лежит между -
1 и +1.
Для нашей регрессионной задачи будем рассматривать rXY . Если корреляция rXY не равна нулю, это значит, что в нашем множестве данных существует некоторая линейная
зависимость между конкретными значениями |
X i и Yi при |
|
i 1,2,...n . (Мы предполагаем, |
что X i не |
подвержены |
130 |
|
|