

Нов.ПМС-2
.pdfсильно и потому обычно не справедливо. |
|
|
|
В линейной модели Y 0 1 X |
исключение |
0 |
|
означает, что линия проходит через точку |
X |
0 , Y 0 , |
т.е. |
она отсекает нулевой отрезок 0 0 при X 0 |
. Исключение |
||
0 из модели возможно с помощью «центрирования» данных,
но это не то же самое, что приравнивание 0 |
0 . Если мы |
|||||||||||||||||||||||||||||
запишем уравнение (9.11) в виде: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
Y Y |
( 0 1 X Y ) 1 ( X X ) , |
||||||||||||||||||||||||||||
или |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
y |
x , |
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
где y Y Y |
, |
x X |
X |
|
|
0 |
|
|
X |
Y |
, |
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
||
то оценки для и |
|
1 |
будут такими: |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
(xi |
x)( yi y) |
|
( X i |
|
)(Yi |
|
|
|
|||||||||||||||||||
b |
|
X |
Y |
) |
||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
= |
|
|
|
|
|
|
|
|
|
|
|
, |
||||||||
1 |
|
|
|
(xi |
|
x)2 |
|
|
|
|
|
( X i X )2 |
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
в соответствии с уравнением (9.17) и |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
b |
y b x 0 |
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
так как x y 0 при любом значении b1 .
Поэтому можно записать центрированную модель, совсем опуская свободный член (отрезок)
|
|
|
|
|
|
: Y Y |
(X X ) . |
||||
0 |
1 |
|
|
|
|
Таким образом, мы потеряли один параметр, что соответствует потере данных, а это влечет за собой потерю части информации. Потерянная часть информации эффективно используется для корректировки модели, позволяющей исключить свободный член
9.4. Точность оценки регрессии
Рассмотрим вопрос о том, какая точность может быть приписана оценке линии регрессии. Рассмотрим тождество:
|
|
|
|
|
|
|
|
Yi Yi |
Yi Y (Yi |
Y ) . |
(9.20) |
||||
|
101 |
|
|
|
|
||
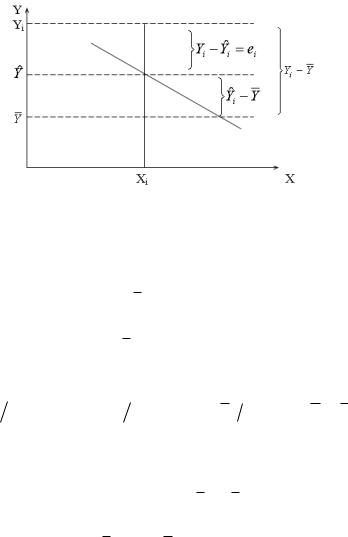
Что это означает геометрически, показано на рис. 9.3.
Рис. 9.3
Остаток ei Yi Yi представляет собой разность между двумя величинами:
1) отклонением наблюдаемого значения отклика Yi от
общего среднего откликов Y и
2) отклонение предсказанного значения отклика Yi от
того же общего среднего Y .
Заметим, что среднее арифметическое предсказанных значений Yi равно
|
n (b0 b1 X i ) n = (nb0 nb1 X ) n = b0 b1 X Y . |
Yi |
Иными словами, среднее арифметическое предсказанных
значений Yi то же, что и наблюдаемых откликов Yi .Отсюда, |
|
как было установлено ранее, |
|
|
|
ei (Yi Yi ) = nY nY 0 . |
|
Уравнение (9.20) можно переписать еще и так: |
|
|
|
Yi Y (Yi |
Y ) (Yi Yi ) . |
Если мы возведем обе части этого выражения в квадрат и
просуммируем по i 1,2,...n , то получим: |
|
|
||||||
|
|
|
|
|
|
|
|
|
(Yi Y )2 |
(Yi |
Y )2 (Yi Yi |
)2 . |
(9.21) |
||||
|
|
|
|
102 |
|
|
||
В уравнении (9.21) величина Yi Y – это отклонение i -го
наблюдения от общего среднего, следовательно, левая часть уравнения (9.21) – это сумма квадратов отклонений
относительно среднего наблюдений (сокращенно |
SS |
||
относительно среднего), а |
также |
скорректированная сумма |
|
|
|
|
|
квадратов Y -в. Так как |
Yi Yi |
есть отклонение |
i -го |
наблюдения от его предсказанного или вычисленного значения
( i -й остаток), а Yi Yi – отклонение предсказанного значения
i -го наблюдения от среднего, то мы можем выразить уравнение (9.21) словесно следующим образом: «сумма квадратов относительно среднего» = «сумма квадратов относительно регрессии» + «сумма квадратов, обусловленная регрессией».
Пригодность линии регрессии для целей предсказания зависит
от того, какая именно часть SS |
относительно |
среднего |
|
приходится на SS , обусловленную |
регрессией, а |
какая – |
|
соответствует SS относительно регрессии. |
|
|
|
Удовлетворительные результаты получаются, |
если |
SS , |
|
обусловленная регрессией, будет много больше, |
чем |
SS |
|
относительно регрессии или, то же самое, если отношение |
|
||
R2 SS, обусловлен ная 1.
SS, относительна
будет не слишком отличаться от 1.
Всякая сумма квадратов связана с числом, называемым ее степенями свободы. В статистике числом степеней свободы некоторой величины часто называют разность между числом различных опытов и числом констант, найденных по этим опытам независимо друг от друга.
Это понятие можно применить к сумме квадратов. Мы получим число, которое показывает, как много независимых элементов информации, получающихся из n независимых чисел Y1 ,...Yn , требуется для образования данной суммы
квадратов. Например, для SS относительно среднего
103
требуется n 1 независимый элемент (из чисел Y1 |
|
|
|
|
|
||||||
Y |
,...Yn Y |
|
|||||||||
независимы только n 1, так как сумма всех n |
чисел при |
||||||||||
определении среднего приравнивалась к нулю). |
|
|
|
|
|
|
|||||
Мы можем вычислить сумму квадратов SS , обусловленную |
|||||||||||
регрессией, используя единственную функцию от |
Y1 ,...Yn , а |
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
именно b1 , [т.к. |
(Yi Y )2 b12 (X i X )2 ], |
и |
|
поэтому |
|||||||
данная сумма квадратов имеет одну степень свободы. |
|
|
|
|
|||||||
По разности |
SS относительно регрессии имеет ( n 2 ) |
||||||||||
степени свободы. Это отражает тот факт, что рассматриваемые остатки получены для модели прямой линии, которая требует оценивания двух параметров. Вообще, остаточная сумма квадратов основывается на числе степеней свободы, равном числу наблюдений минус число оцениваемых параметров. Следовательно, в соответствии с уравнением (9.21) мы можем разложить степени свободы таким образом:
. (9.22)
Пользуясь уравнениями (9.21) и (9.22), мы можем построить таблицу дисперсионного анализа. (ANOVA). Обозначение ANOVA произошло от английских слов « Analysis of variance». «Средний квадрат» MS получается при делении каждой суммы квадратов SS на соответствующее ей число степеней свободы.
Таблица 9.1. Таблица дисперсионного анализа (ANOVA). Основное
разложение
Источник |
Число |
|
Суммы |
Средние |
||
вариации |
степе- |
квадратов |
квадраты |
|||
|
ней |
|
SS |
MS |
||
|
свобо- |
|
|
|
|
|
|
ды |
|
|
|
|
|
Обуслов- |
|
|
|
|
|
|
ленный |
|
n |
|
|
|
|
регрес- |
1 |
(Yi Y )2 |
MS |
|||
сией |
|
i 1 |
|
|||
|
|
|
|
|
|
|
|
|
|
104 |
|
||
Продолжение табл. 9.1
Относи- |
|
n |
|
|
|
SS |
|
|
тельно |
n 2 |
(Yi |
Yi )2 |
s 2 |
|
|
||
n 2 |
|
|||||||
i 1 |
|
|
|
|
|
|||
регрессии |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(остаток) |
|
|
|
|
|
|
|
|
Общий, |
|
|
|
|
|
|
|
|
скоррек- |
|
n |
|
|
|
|
|
|
|
|
(Yi |
|
|
)2 |
|
|
|
тирован- |
n 1 |
Y |
|
|
|
|||
ный на |
|
i 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
среднее |
|
|
|
|
|
|
|
|
Y |
|
|
|
|
|
|
|
|
Более общая форма таблицы дисперсионного анализа получается при добавлении в таблицу корректирующего фактора для среднего Y -в, который называется SS(b0 ) .Это
название будет пояснено позже
Таблица 9.2 Таблица дисперсионного анализа (ANOVA), включающая
SS(b0 )
Источник |
Число |
Суммы квадратов SS |
Средние |
|||||
вариа- |
степе |
|
|
|
|
|
|
квадраты |
ции |
ней |
|
|
|
|
|
|
MS |
|
свобо- |
|
|
|
|
|
|
|
|
ды |
|
|
|
|
|
|
|
Обуслов- |
1 |
SS(b1/b0 )= |
|
|
|
|
|
|
ленный |
|
n |
|
|
|
|
|
MS |
b0 b1 |
|
= (Yi |
Y )2 |
|
||||
|
i 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
||
|
|
(Yi |
|
|
||||
Остаток |
n-2 |
Yi )2 |
s 2 |
|||||
|
|
i 1 |
|
|
|
|
|
|
105

Общий, |
n 1 |
n |
|
|
|
|
|
|
(Yi |
|
|
|
|
|
|
||
Y )2 |
|
|
||||||
скоррек- |
|
|
||||||
тирован- |
|
i 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ный |
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
||
Коррек- |
1 |
|
( Yi )2 |
|
|
|||
тиру- |
|
SS(b ) = |
|
i 1 |
|
|
||
|
|
|
|
|
||||
ющий |
|
0 |
|
|
n |
|
|
|
|
|
|
|
|
|
|||
фактор, |
|
|
|
|
|
|
|
|
обуслов- |
|
|
|
|
|
|
|
|
ленный |
|
|
|
|
|
|
|
|
b0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
|
|
Общий |
n |
Yi |
2 |
|
|
|
||
|
|
i 1 |
|
|
|
|
|
|
Сумма SS редко подсчитывается так, как показано в таблице, а обычно получается делением SS(b1  b0 ) на общую
b0 ) на общую
скорректированную SS . Сумму квадратов, обусловленную регрессией, можно вычислять множеством способов (суммирование везде идет по i 1,2,...n ):
|
|
|
|
|
|
|
= b1[ (X i |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
SS(b1 b0 ) (Yi |
Y )2 |
X )(Yi Y )] =b1SXY. |
(9.23) |
||||||||||||||||||||||||||
|
|
|
|
|
|
[ ( X i |
|
)(Yi |
|
|
|
)]2 |
|
|
|
||||||||||||||
|
|
|
S XY2 |
X |
Y |
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
= |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
|
|
|
|
( X i |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
S XX |
|
|
|
|
X )2 |
|
|
|
||||||||||||||||||
|
S XY2 |
|
[ X iYi X i |
Yi |
n]2 |
|
|
|
|||||||||||||||||||||
|
|
= |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
|
|
(9.24) |
||||
|
|
|
|
|
X i2 ( X i )2 |
|
|
|
|
||||||||||||||||||||
|
S XX |
|
|
|
|
n |
|
|
|
||||||||||||||||||||
|
|
|
|
|
|
S XY2 |
|
|
[ ( X i |
|
|
)Yi ]2 |
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
X |
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
= |
|
|
|
|
|
. |
|
|
|
||||||||||||
|
|
|
|
|
|
S XX |
|
|
( X i |
|
|
|
|
)2 |
|
|
|
||||||||||||
|
|
|
|
|
|
|
X |
|
|
|
|||||||||||||||||||
Уравнение (9.23) проще всего использовать, поскольку оба сомножителя уже получены при подборе уравнения прямой. Округление может внести неточности, лучше использовать формулу (9.24), где деление производится в
106

последний момент.
Общую скорректированную сумму квадратов можно записать и вычислить следующим образом:
SYY (Yi Y )2 = Yi 2 ( Yi )2  n = .
n = .
= Yi |
|
|
|
|
|
2 nY |
2 . |
|
|||
Обозначение SS(b1 b0 ) читается так: «сумма квадратов |
|||||
для b1 с учетом поправки |
на b0 ». |
Средний квадрат |
|||
относительно регрессии s 2 |
|
дает |
оценку дисперсии |
||
относительно регрессии, основанную на (n-2) степенях свободы. Будем обозначать эту величину YX2 . Если уравнение
регрессии будет оцениваться из большого числа наблюдений, то дисперсия относительно регрессии будет представлять ошибку измерения, с которой любое измеренное Y предсказывается для данного значения X по известному уравнению:
Исследуем уравнение регрессии. Пока не были использованы предположения о распределении вероятностей. Теперь введем основные предположения о том, что в модели
|
|
|
|
|
|
Yi 0 1 X i i , i 1,2,...n : |
|
|
|
|
||||||||
1) остаток |
i есть случайная величина со средним, |
равным |
||||||||||||||||
нулю, и неизвестной дисперсией 2 , т.е. |
|
|
|
|
|
|
|
|
||||||||||
E( i ) 0 , V ( i ) 2 – англоязычное |
|
|
|
|
|
|
|
|
|
|
||||||||
M ( i ) 0 , |
D( i ) 2 |
– русское обозначение; |
|
|
|
|
||||||||||||
2) остатки |
i |
и j |
некоррелированы |
при |
i j , так |
что |
||||||||||||
cov ( |
i |
, |
j |
) 0 . |
Поэтому |
M (Y ) |
0 |
|
1 |
X |
i |
, |
D(Y ) 2 |
и |
||||
|
|
|
|
|
|
i |
|
|
|
|
i |
|
|
|||||
значения Yi |
и Y j |
некоррелированы при i j ; |
|
|
|
|
|
|||||||||||
3) остаток |
i |
есть |
нормально распределенная |
случайная |
||||||||||||||
величина со средним нуль и дисперсией 2 , |
т.е. i |
~ N (0, 2 ) . |
||||||||||||||||
При добавлении этого предположения остатки |
i |
и |
j |
|||||||||||||||
становятся |
не |
только |
некоррелированными, |
но |
даже |
|||||||||||||
|
|
|
|
|
|
|
|
107 |
|
|
|
|
|
|
|
|
|
|

независимыми
Замечание 1.
Дисперсия 2 может быть равной или не равной YX2 – дисперсии относительно регрессии. Если постулированная модель не соответствует «истинной», то 2 YX2 . Из этого следует, что s 2 – остаточный средний квадрат, который в любом случае оценивает YX2 – служит оценкой 2 , если только модель корректна. Если 2 YX2 , то постулируемая
модель некорректна или страдает неадекватностью.
Замечание 2.
Во многих реальных ситуациях ошибки, в соответствии с центральной предельной теоремой, подчиняются нормальному распределению. Если оказывается суммой ошибок, то, независимо от того, как распределены отдельные ошибки, их сумма имеет тенденцию к нормальному распределению в соответствии с центральной предельной теоремой.
9.5. Интервальное оценивание параметров регрессии |
|
||||||||||||||||
Рассмотрим |
стандартное |
|
отклонение |
b1 |
и |
||||||||||||
доверительный интервал для 1 . |
|
|
|
|
|
|
|
|
|||||||||
Мы знаем, что |
|
|
|
|
|
|
|
|
|
||||||||
|
( X i |
|
|
|
|
|
|
|
( X i |
|
|
|
|
|
|
|
|
b |
X |
)(Yi Y |
) |
= |
X )Yi |
= |
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
1 |
|
( X i X )2 |
|
( X i |
X )2 |
|
|
|
|||||||||
|
|
|
|
|
|
||||||||||||
( X1 X )Y1 ... ( X n X )Yn .( X i X )2
Далее, дисперсия некоторой функции
F a1Y1 ...anYn
равна
D(F) a12 D(Y1 ) ... an2 D(Yn ) ,
если Yi попарно некоррелированы и ai – константы.
108

Кроме того, если D(Y ) 2 |
, то |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
i |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
D(F) (a12 ... an2 ) 2 |
2 ai2 . |
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В выражении для b1 : |
ai |
|
|
|
( X i |
|
X |
) |
|
|
|
, |
|
|
|
|||||||||
|
( X i |
|
|
|
|
|
|
2 |
|
|
|
|
||||||||||||
|
X ) |
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
так как X i |
можно |
рассматривать как |
константы. Отсюда, |
|||||||||||||||||||||
после преобразований получаем |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
D(b1 ) |
|
|
|
|
|
|
2 |
|
|
|
|
2 |
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
||||
|
( X i |
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
X )2 |
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
S XX |
|||||||||||||||
Стандартное |
отклонение |
|
|
|
b1 |
есть |
|
квадратный корень из |
||||||||||||||||
дисперсии, т.е. |
|
|
|
|
|
|
|
|
|
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
( X i |
|
)2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
X |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
Если неизвестна и мы используем вместо нее оценку s , предполагая, что модель корректна, то оценка стандартного отклонения b1 есть
|
s |
|
. |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
( X i |
|
)2 |
||
|
X |
|
|
||
Вместо термина «оцениваемое стандартное отклонение» обычно используют термин «стандартная ошибка». Если мы предполагаем, что разброс наблюдений относительно линии
нормален, т.е. что ошибки j |
|
все принадлежат некоторому |
|||||||||
нормальному распределению |
N (0, 2 ) , то |
можно |
показать, |
||||||||
что |
100 (1 ) % |
|
доверительные интервалы |
для 1 |
|||||||
получаются, если вычислить |
|
|
|
|
|
|
|
||||
|
|
|
t(n 2,1 )s |
|
|
|
|
||||
|
b1 |
|
|
|
2 |
|
|
, |
|
(9.25) |
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
||||||
|
( X i X )2 |
|
|||||||||
|
|
|
|
|
|
|
|
||||
где |
t(n 2,1 ) – это |
100 (1 ) % точка |
t -распределения |
||||||||
|
2 |
|
|
|
2 |
|
|
|
|
||
Стьюдента с n 2 степенями свободы.
109

Сдругой стороны, мы можем проверить нуль - гипотезу
отом, что 1 10 ,
где 10 – частное значение, которое может быть нулем против
альтернативы, что 1 отлично от 10 . |
|
||||
Обычно пишут: H0 : 1 10 против H1 : 1 10 . |
|
||||
Для этого надо вычислить |
|
||||
t ( 1 10 ) |
|
|
|
|
|
( X i |
|
)2 s |
(9.26) |
||
X |
|||||
и сравнить | t | с t(n 2,1 ) из таблицы t -критерия с |
(n 2) |
||||
2 |
|
|
|
|
|
степенями свободы – числом, на котором основана оценка s 2
для |
2 . В таком виде критерий будет двусторонним с |
100 % процентным уровнем значимости. |
|
|
После того как мы получили доверительный интервал |
для |
1 , уже нет необходимости находить величину | t | для |
проверки гипотезы с помощью t -критерия. Достаточно
исследовать |
доверительный |
|
интервал |
для 1 |
и посмотреть, |
||||||||
содержит ли |
он |
значение |
10 . Если это так, то гипотезу |
||||||||||
H0 : 1 10 |
нельзя |
отвергнуть, а |
если |
|
не |
так, |
то она |
||||||
отвергается. |
Это можно |
увидеть |
из |
|
уравнений |
(9.26), |
|||||||
H0 : 1 10 |
|
отвергается |
|
|
при |
|
|
-уровне, |
если |
||||
| t | t(n 2,1 ) , откуда следует, что |
|
|
|
|
|
|
|
||||||
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
t(n 2,1 |
)s |
|
|
|
|
|||
|
|
| 1 |
10 | |
|
|
|
2 |
|
|
, |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
( X i X )2 |
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
||||
т.е. что 10 |
лежит за |
|
пределами, |
соответствующими |
|||||||||
уравнению (9.25). |
|
|
|
|
|
|
|
|
|
|
|
||
110