

Информационный поиск
Поиск информации представляет собой процесс выявления в некотором множестве документов (текстов) всех тех, которые посвящены указанной теме (предмету), удовлетворяют заранее определенному условию поиска (запросу) или содержат необходимые (соответствующие информационной потребности) факты, сведения, данные.
Рассматривается поиск информации в документах, поиск самих документов, извлечение метаданных из документов, поиск текста, изображений, видео и звука в локальных реляционных базах данных, в гипертекстовых базах данных таких, как Интернет и локальные интранет-системы.
Запрос — это формализованный способ выражения информационных потребностей пользователем системы. Для выражения информационной потребности используется язык поисковых запросов, синтаксис варьируется от системы к системе. Кроме специального языка запросов, современные поисковые системы позволяют вводить запрос на естественном языке.
Объект запроса — это информационная сущность, которая хранится в базе информационно-поисковой системы (ИПС). Процесс занесения объектов поиска в ИПС называется индексацией. ИПС не всегда хранит точную копию объекта, нередко вместо неё хранится суррогат или индекс.
Информационный поиск
Поисковая система — программно-аппаратный комплекс с веб-интерфейсом, предоставляющий возможность поиска информации в Интернете.
Под поисковой системой обычно подразумевается сайт, на котором размещён интерфейс (фронт-энд) системы.
Поисковая машина (поисковый движок) — комплекс программ, предназначенный для поиска информации. Обычно является частью поисковой системы.
Основными критериями качества работы поисковой машины являются релевантность (степень соответствия запроса и найденного, т.е. уместность результата), полнота базы, учёт морфологии языка.
Индексация - извлечение из документов информации, важной для поиска, преобразование этой информации в формат, удобный для поисковой машины и сохранение этой информации в базу данных поисковой машины.
Поиск по базе данных проиндексированных документов включает:
•Нахождение документов, соответствующих поисковому запросу
•Ранжирование документов в соответствии с их релевантностью поисковым
запросам
•Кластеризацию (группировку) документов
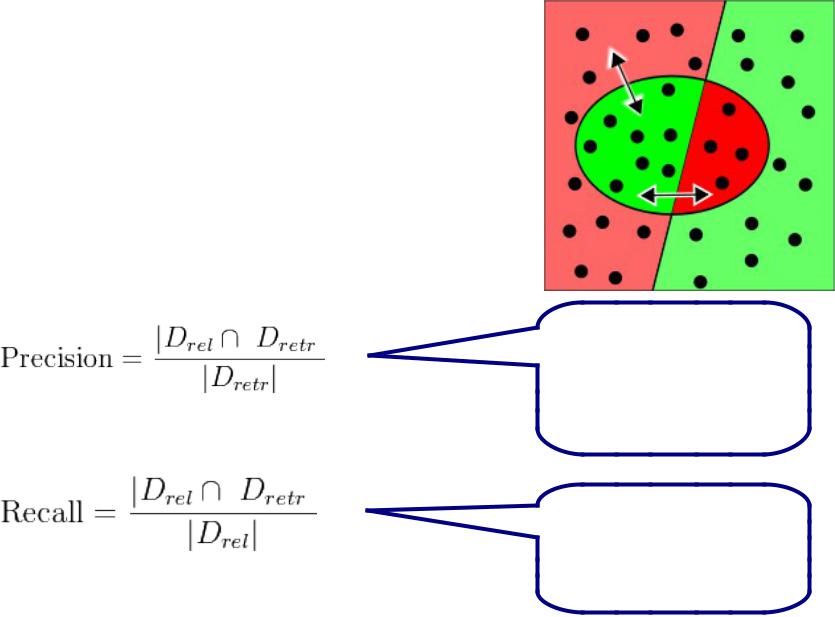
Оценка эффективности поиска
На этом рисунке релевантные точки (rel) находятся слева от прямой, а точки, найденные поисковой системой (retr), находятся в овале. Области красного цвета представляют ошибки поисковой системы. Красная область слева - это релевантные точки, не найденные системой (пропуск события), красная область справа - найденные, но нерелевантные точки (ложная тревога).
Точность - это пропорция левой зелёной области по отношению к овалу (горизонтальная стрелка).
Полнота - это пропорция левой зелёной области к области слева от прямой (диагональная стрелка).
Определяется как
отношение числа
найденных релевантных документов к общему числу найденных
документов
Отношение числа
найденных релевантных
документов, к общему числу релевантных
документов в базе
Информационный поиск: индексы и алгоритмы
Нечеткий поиск – поиск по ключевым словам с учётом возможных произвольных ошибок в написании ключевого слова и/или целевого
запроса.
Поисковые индексы – структуры данных, используемые при поиске:
•векторные и кластерные модели;
•модели на основе ключевых слов.
Инвертированные файлы Сигнатурные файлы
Поисковые метрики - меры сходства или различия между словами: Расстояния Хемминга, Левенштейна, Дамерау-Левенштейна, Джаро, Джаро-Уинклера и др.
Методы поиска
•Последовательный поиск (полный перебор всех слов словаря);
•Метод расширения выборки (query extension);
•Метод n-грамм;
•Поиск с использованием хеширования;
•Методы, основанные на неравенстве треугольника (триангуляционные деревья).
Поиск по ключевым словам
К группе поиска по ключевым словам относится большинство современных технологий поиска, используемых в информационно-поисковых системах, в том числе – системах поиска в сети Интернет, обрабатывающих запросы на естественных языках (Google, Yandex…).
Впроцессе поиска такие системы производят выборку всех документов, содержащих хотя бы одно ключевое слово (грамматическую форму данного слова или его синоним), а затем ранжируют результаты поиска по степени соответствия (релевантности) документов поисковому запросу.
Воснове поиска по ключевым словам лежит использование специализированных индексных словарей двух основных типов: инвертированные файлы и сигнатурные файлы.
Поиск по ключевым словам
Инвертированный файл (ИФ) является аналогом предметного указателя в конце книги. ИФ – множество пар <ключевое слово, адрес вхождения ключевого слова в документ>. Детализация адреса слова может быть различной: на уровне документа, абзаца, непосредственного места слова в тексте. Основным недостатком ИФ является его большой объём. Если не применять специальные методы сжатия списков вхождений, то размер ИФ может превышать размер исходного текстового массива в 2-3 раза.
Сигнатурные файлы (СФ) содержат сигнатуры данных, представляющие собой их упрощенные профили, в которых каждый элемент кодируется одним битом (есть вхождение ключевого фрагмента или нет такого вхождения). Размер СФ составляет порядка 50% от исходных данных. Основным недостатком сигнатурных файлов является то, что множество сигнатур однозначно определяет множество документов, но не каждый документ конкретно. Поэтому после предварительной выборки данных по сигнатурам необходима их дополнительная обработка с целью уточненной проверки на соответствие запросу.
В настоящее время разработаны методы построения сжатых ИФ, вследствие чего область применения СФ несколько сузилась. Сжатые ИФ существенно превосходят СФ по производительности для коротких запросов, но проигрывают им на длинных и очень длинных запросах. В среднем короткие запросы встречаются гораздо чаще, поэтому в большинстве систем на сегодняшний день преимущество отдается ИФ.
Алгоритмы нечеткого поиска
Последовательный поиск предполагает последовательный перебор слов из словаря и сравнение каждого из них с запросом в соответствии с принятой метрикой. Основным достоинством последовательного поиска являются простота реализации и достаточно высокая скорость работы, связанная с тем, что при последовательном считывании данных с диска компьютера в виде больших файлов достигается пиковая скорость чтения. Время поиска в данном случае пропорционально размеру словаря. Кроме того, этот метод позволяет без ограничений реализовать многофункциональный поиск, например, по подстроке или по регулярным выражениям.
Метод расширения выборки. Суть данного метода заключается в построении множества всевозможных «ошибочных» слов, например, получающихся из исходного в результате одной операции редактирования Левенштейна, после чего построенные поисковые запросы ищутся в словаре на точное совпадение.
Метод n-грамм. Идея метода заключается в построении инвертированного файла, в котором роль документов играют слова, а роль слов – подстроки длины n, называемые n-граммами. Основной недостаток метода – большой размер вспомогательного индексного файла (в 10-20 раз больше размера
Алгоритмы нечеткого поиска
Поиск с использованием хеширования. Идея, лежащая в основе методов хеширования, состоит в подборе отображения (хеш- функции) слова, например, во множество чисел или строк, сохраняющего основные характеристики исходного слова и устойчивого к наиболее распространённым ошибкам. Такая функция позволяет разбить слова словаря на группы и производить последовательный поиск внутри группы, вычисляемой по поисковому шаблону. Например, для разбиения на группы иногда используют хеширование по некоторому количеству первых символов слова (метод trie-деревьев). Другим известным примером является хеш-функция Soundex, встроенная в коммерческие СУБД Sybase, MS SQL Server, Oracle.
Триангуляционные деревья позволяют индексировать множества произвольной структуры, при условии, что на них задана метрика. В основу построения триангуляционных деревьев положена идея
расположения близких в смысле заданной метрики объектов в одинаковых поддеревьях. Метод эффективен в ситуации, когда операция сравнения достаточно дорогостоящая (например, при поиске в базах изображений или больших документов), и позволяет существенно сократить количество сравнений.
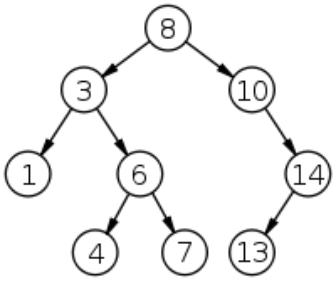
Дерево поиска
Двоичное дерево поиска (binary search tree, BST) — это двоичное дерево,
для которого выполняются следующие дополнительные условия (свойства дерева поиска):
•Оба поддерева — левое и правое, являются двоичными деревьями поиска.
•У всех узлов левого поддерева произвольного узла X значения ключей данных меньше, нежели значение ключа данных узла X.
•У всех узлов правого поддерева произвольного узла X значения ключей данных больше, нежели значение ключа данных узла X.
Основным преимуществом двоичного дерева поиска перед другими структурами данных является возможная высокая эффективность реализации основанных на нём алгоритмов поиска и сортировки.
Пример двоичного дерева поиска
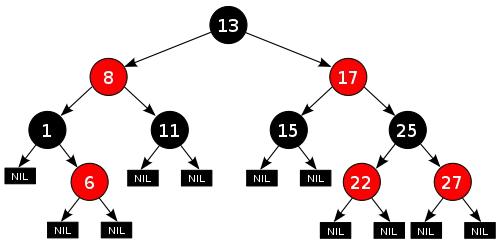
Красно-черное дерево поиска
Красно-чёрное дерево — двоичное дерево поиска, в котором каждый узел имеет атрибут цвет, принимающий значения красный или черный.
К красно-чёрным деревьям дополнительно применяются следующие требования:
1.Узел либо красный, либо чёрный.
2.Корень — чёрный.
3.Все листья — черные.
4.Оба потомка каждого красного узла — черные.
5.Всякий простой путь от данного узла до любого листового узла, являющегося его потомком, содержит одинаковое число черных узлов.
Эти ограничения реализуют критическое свойство красно-черных деревьев: путь от корня до самого дальнего листа не более чем в два раза длиннее пути от корня до ближайшего листа. Так как операции вставки, удаления и поиска значений требуют в худшем случае
времени, пропорционального длине дерева, эта верхняя граница высоты
позволяет красно-чёрным деревьям быть более эффективными в худшем
случае, чем обычные двоичные Пример красно-чёрного дерева
деревья поиска.