

1.4.4.Нормализация отношений
Одни и те же данные могут группироваться в таблицы (сущности, отношения) различными способами. Группировка атрибутов в таблицах должна быть рациональной, т.е. минимизирующей дублирование данных и упрощающей процедуры их обработки
Нормализация отношений –формальный аппарат ограничений на формирование отношений (таблиц), который позволяет устранить дублирование, обеспечивает непротиворечивость хранимых в базе данных, уменьшает трудозатраты на ведение (ввод, корректировку) базы данных.
Выделяют пять нормальных форм отношений. Эти формы предназначены для уменьшения избыточности информации от первой до пятой нормальных форм. Поэтому каждая последующая нормальная форма должна удовлетворять требованиям предыдущей формы и некоторым дополнительным условиям. При практическом проектировании баз данных четвертая и пятая формы, как правило, не используются.
Процедуру нормализации рассмотрим на примере проектирования многотабличной БД Заказы, содержащей следующую информацию:
· Сведения о покупателях
· Дату заказа и количество заказанного товара, данные о менеджере, обслуживающем заказ
· Характеристику проданного товара (наименование, стоимость, и т.д.)
 Рисунок
7 - Ненормализованная БД
Рисунок
7 - Ненормализованная БД
· Приходится тратить значительное время на ввод повторяющихся данных. Например, для всех заказов, сделанных одним заказчиком, придется каждый раз вводить одни и те же данные о заказчике.
· При изменении адреса или телефона заказчика необходимо корректировать все записи, содержащие сведения о заказах этого заказчика.
· Наличие повторяющейся информации приведет к неоправданному увеличению размера БД. В результате снизится скорость выполнения запросов. Кроме того, повторяющиеся данные нерационально используют дисковое пространство компьютера.
· Любые нештатные ситуации потребуют значительного времени для получения требуемой информации.
Первая нормальная форма
Таблица, структура которой приведена на рисунке 7, является ненормализованной. Таблица в первой нормальной форме (1НФ) должна удовлетворять следующим требованиям:
· Таблица не должна иметь повторяющихся записей.
· В таблице должны отсутствовать повторяющиеся группы полей.
· Строки должны быть не упорядочены
· Столбцы должны быть не упорядочены.
Для удовлетворения условия 1 значение хотя бы одного поля таблицы для каждой строки таблицы должно быть уникально, т.е. быть ключом. Таблица Заказы не содержит такого ключа, что допускает наличие в таблице повторяющихся записей.
В таблицах большинства СУБД записи упорядочены, поэтому требование 3 не может быть удовлетворено.
Так как каждый покупатель может сделать несколько заказов, в каждом из которых в свою очередь может заказать несколько товаров, то для выполнения требования 2, необходимо разбить таблицу на три таблицы:
· сведения о заказчиках
· номер и дату заказ клиента, данные о менеджере, обслуживающем заказ.
· код, наименование, количество заказанного товара.
Поэтому разобьем таблицу Заказы на три отдельные таблицы (Заказчик, Заказ и Заказано) и определим ИНН фирмы в качестве совпадающего поля для связывания таблицы Заказчик с таблицей Заказ и № заказа – для связывания таблиц Заказ и Заказано (рисунок 8)
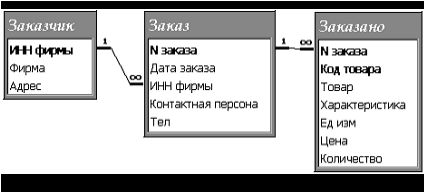
Отметим, что отношение между связываемыми таблицами “один-ко-многим”
Таблица Заказ содержит данные о клиентах. Определим ключевое поле ИНН фирмы. Аналогично для таблицы Заказ – ключевое поле Номер Заказа. Таким образом, для таблиц Клиенты и Заказы решена проблема повторяющихся групп.
Таблица Заказано содержит сведения о товарах, включенных в заданный заказ. Для исключения повторяющихся записей можно воспользоваться одним из способов:
· Добавить в таблицу новое уникальное ключевое поле Счетчик, что позволит однозначно идентифицировать каждую запись. Это не лучший способ, т.е. в дальнейшем при построении схемы данных не позволит установить связь между таблицами.
· В качестве ключа использовать составной ключ, состоящий из 2 полей Номер Заказа и Код товара
После разделения повторяющихся строк и определения ключей в каждой таблице можно считать, что таблицы Заказчик, Заказ и Заказано находятся в первой нормальной форме.