

1.2.2.Сетевая модель данных
Отличается большей гибкостью, так как в ней существует возможность устанавливать и горизонтальные связи, т.е. в сетевой структуре каждый элемент может быть связан с любым другим элементом:
Пример сетевой структуры представлен на рисунке 2. База данных, содержащая сведения о студентах, участвующих в научно-исследовательских работах (НИРС). Возможно участие одного студента в нескольких НИРС, а также участие нескольких студентов в разработке одной НИРС:
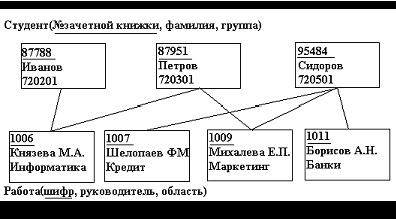
1.2.3.Реляционная модель данных
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц (см. табл. 1). Каждая реляционная таблица (отношение) представляет собой двумерный массив и обладает следующими свойствами:
· каждый элемент таблицы - один элемент данных;
· все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину;
· каждый столбец имеет уникальное имя;
· одинаковые строки в таблице отсутствуют;
· порядок следования строк и столбцов может быть произвольным.
Таблица 1- Информация о студентах, обучающихся в вузе
|
№ зачетной книжки |
Фамилия |
Имя |
Отчество |
Дата рождения |
Группа |
|
155125 |
Сергеев |
Петр |
Михайлович |
01.01.80 |
720581 |
|
154652 |
Петрова |
Анна |
Владимировна |
15.03.81 |
720591 |
|
178535 |
Анохин |
Андрей |
Борисович |
14.04.80 |
720682 |
Поле, каждое значение которого однозначно определяет соответствующую запись, называется простым ключом(ключевым полем). Если записи однозначно определяются значениями нескольких полей, то такая таблица базы данных имеетсоставной ключ.
Все информационные объекты предметной области (таблицы) связаны между собой. Различаются связи нескольких типов (мощностей):
· один к одному (1:1) - каждому экземпляру одного ИО соответствует только один экземпляр другого ИО
· один ко многим (1:N) - каждому экземпляру одного ИО может соответствовать несколько экземпляров другого ИО
· многие ко многим (N:M) - - каждому экземпляру одного ИО может соответствовать несколько экземпляров другого ИО и наоборот
Чтобы связать две реляционные таблицы, необходимо ключ первой таблицы ввести в состав ключа второй таблицы (возможно совпадение ключей); в противном случае нужно ввести в структуру первой таблицы внешний ключ- ключ второй таблицы.
В таблице 2 представлены сведения, какие модели использованы в каких СУБД.
Таблица 2 -Сведения о моделях данных в некоторых СУБД
|
Название СУБД |
Тип БД |
|
MS Access |
Реляционная |
|
FoxPro |
Сетевая |
|
Oracle |
Реляционная |
|
Paradox |
Реляционная |
1.3.Классификация баз данных
По технологии обработкиданных базы данных подразделяются на централизованные и распределенные (см. рисунок 3).
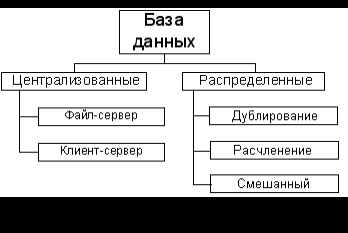
Централизованная база данных хранится в памяти одной вычислительной системы. Если эта вычислительная система является компонентом сети ЭВМ, возможен распределенный доступ к такой базе. Такой способ использования баз данных часто применяется в локальных сетях ПК.
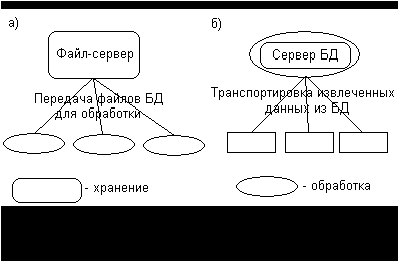
Системы централизованных баз данных с сетевым доступом (системы распределенной обработки данных) предполагают различные архитектуры подобных систем: файл-сервер и клиент-сервер.
При файл-серверной архитектуре систем БД с сетевым доступом предполагается выделение одной из машин сети в качестве центральной (сервер файлов). На такой машине хранится совместно используемая централизованная БД. Все другие машины сети выполняют функции рабочих станций, с помощью которых поддерживается доступ пользователей системы к централизованной базе данных. Файла базы данных в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится обработка. При большой интенсивности доступа к одним и тем же данным производительность информационной системы падает.
Концепция клиент-сервер подразумевает, что помимо хранения централизованной базы данных центральная машина (сервер баз данных) должна обеспечивать выполнение основного объема обработки данных. Запрос на данные, выдаваемые клиентом (рабочей станцией), порождает поиск и извлечение данных на сервере. Извлеченные данные (но не файлы) транспортируются по сети от сервера к клиенту. Спецификой архитектуры клиент-сервер является использование языка запросов SQL.
Распределенная база данных состоит из нескольких, возможно пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети. Работа с такой базой осуществляется с помощью системы управления распределенной базы данных (СУРБД).
При распределении данных на основе расчленения база данных размещается на нескольких серверах. Существование копий отдельных частей недопустимо. Достоинства: увеличивается объем базы данных; большинство запросов удовлетворяемся локальными базами, что сокращает время ответа; увеличивается доступность и надежность; стоимость запросов на выборку и обновление снижается по сравнению с централизованным распределением, если выйдет из строя один сервер, система останется частично работоспособной. Недостатки:
часть удаленных запросов или транзакций могут потребовать доступ ко всем серверам, что увеличивает время ожидания и цену;
необходимо иметь сведения о размещении данных в БД.
Однако доступность и надежность увеличатся.
При дублированиив каждом сервере сети ЭВМ размещается полная база данных. Этот метод дает наиболее надежный способ хранения данных. Недостатки:
повышенные требования к объему внешней памяти;
усложняется корректировка баз, т.к. требуется синхронизация с целью согласования копий.
Достоинства: все запросы выполняются локально, что обеспечивает быстрый доступ. Этот метод используется, когда фактор надежности является критическим, база небольшая, интенсивность обновления невелика.
В методе смешанного распределенияобъединены два способа распределения данных: дублирование и расчленение.
При этом приобретены как преимущества, так и недостатки обоих способов. Появилась необходимость хранить информацию о том, где находятся данные в сети. Главное преимущество - гибкость этой системы, так как можно установить компромисс между объемом памяти под базу в целом и под базу в каждом сервере, чтобы обеспечить надежность и эффективность работы. В этой стратегии легко реализуется параллельная обработка. Недостатки: остается проблема взаимозависимости факторов, влияющих на производительность системы, ее надежность, повышаются требования к памяти. Смешанную стратегию используют при наличии сетевой СУБД.