

Bileti_po_AvIS / Avis_bilet_07_v2
.docБилет № 7
-
Проблемы поиска неисправностей модели FCAPS.
-
Дайте инструкцию по организации НСД в системе.
-
Проблемы поиска неисправностей модели FCAPS.
Под fault понимают следующие 12 задач обнаружения ошибок (управления):
-
Определение ошибки;
-
Коррекция ошибки;
-
Изоляция ошибки;
-
Восстановление после ошибки;
-
Поддержка тревог (alarms);
-
Фильтрация тревог;
-
Генерация тревог;
-
Проблема объяснения ошибки (корреляция);
-
Проведение диагностических тестов;
-
Ведение журнала ошибок;
-
Сбор статистики ошибок;
-
Сопровождение ошибок.
Устранение ошибок может быть автоматическим, так и полуавтоматическим, а может быть и ручным. Для того чтобы искать ошибки в системе, контролировать, собирать статистику, необходимо некие продукты. Такие программные продукты называются Network Managerment System (NMS) или есть просто управляющие продукты.
В автоматическом режиме такие продукты управляют оборудованием, программным комплексами и сами устраняют отказавшие элементы при помощи резервных каналов или средств СУБД (активизировать методы доступа).
В полуавтоматическом режиме основные решения действия устранения ошибок выполняет админ. NMS только помогают, например, оформлять наряды квитанций на выполнение работы или отслеживают поэтапное выполнение этих работ.
NMS – это специализированных программный продукт, ведет журнал ошибок, собирает статистику, фиксирует конфигурацию устройств, опознает тревожные ситуации.
Основу всего сопровождения составляет NMS – Network Management System. Этих систем много, например, IBM Tivoly, Open View, Activity. Но это soft, и он спасает только от проблем soft-а, поэтому его недостаточно для всех задач fault.
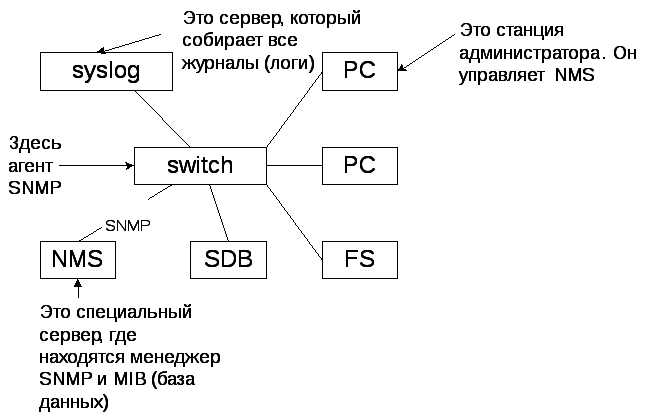
Soft помогает вести журнал, собирать статистику и т.д., но и самому думать надо.
Есть базовые правила поиска ошибок (предложенные разработчиками ОС):
-
Убедиться в том, что ошибки действительно есть (не смотрим никаких журналов и т.д.);
-
Провести инвентаризацию (при этом NMS может помочь, а может и не помочь, она дает план системы). У администратора должен быть worksheet - там карта сети и все параметры. Нужно убедиться, что все на месте и согласно плану;
-
Остановить все и сделать backup. Причем не пользуемся утилитой backup-ирования, а копируем «том в том» или «диск в диск»;
-
Делаем restart. Есть холодный restart (c отключением питания) и горячий (без отключения питания). При холодном старте заново загружаются все драйверы, все части ОС, заново делается инициализация. Нужно делать холодный старт, однако если проблема с оборудованием, то оно после этого может вообще не включиться. Перед restart нужно завершить все процессы (транзакции ОС и СУБД);
-
Если система загрузилась, нужно проверить права и привилегии, версии ПО (никогда не работаем на последней версии), нужно убедиться в том, что никто из пользователей не поставил себе никаких обновлений (хотя и непонятно, как у него это могло получиться);
-
Смотрим журналы (логи);
-
Строим гипотезы, т.е. по каким причинам может не работать (частые ошибки кабельные, ошибки системного софта, прикладного софта и аппаратные).(внешние шумы, возросли объемы информации);
-
Ранжирование гипотез по вероятности (кабельные, прикладные софты, системные ошибки);
-
Проверяем по очереди гипотезы (одну в единицу времени). Гипотезы проверяются в одной последовательности: или в восходящей (от станции к коммутационной аппаратуре (софт сервера)), или в нисходящей (от коммутационной аппаратуры к станции). Проверяют сначала те гипотезы, которые быстрее проверить и отсечь (проверка портов, кабелей).
Определение ошибки
Есть две стратегии выявления ошибок: активная и пассивная.
Пассивная. После того, как что-нибудь уже случилось, посылаем сообщения по SNMP NMS (проактивная).
Активная. NMS будет опрашивать не с помощью SNMP, а сама будет посылать опрос на регулируемой основе аппаратуры (up/down monitoring). NMS посылает команды по сети и смотрим, что МОЖЕТ случиться. Протокол UDP или ICMP.
Предполагается, что мы используем обе стратегии.
Нужно решить, сколько часов в сутки система должна работать. Это определяется SLA (Service Level Agreement) соглашение между бизнесом и техническими услугами (службами администрат. систем).
Например, из 20 из 24 часов. Если это требование выполняется, считается, что ошибок нет.
При настройке NMS, создаются специальные триггеры (что пропускать, а что считать ошибкой). В некоторых ситуациях надо подавлять сообщения об ошибках (например, сообщение о том, что производительность упала на 0.5 % и т.п.)
Можно настроить reset так, чтобы система сама перезагружалась в определенных случаях.
Изоляция ошибки
Чтобы изолировать проблему, нужно отключить все лишнее. Для этого нужно сделать cross log – перекрестный поиск ошибок.
Коррекция ошибки
Начинается с холодного старта.
Последний этап – это документирование ошибки.
Чтобы определить, что такое безошибочная работа вообще, нужны критерии – метрики.
Существуют следующие метрики:
-
MTTR - Mean Time To Repair (ожидаемое время восстановления системы). Например, не более 3 часов. Это критическая метрика для планирования процедуры восстановления.
-
Uptime. Базовая метрика, которая говорит о том, сколько времени проходит между подъемами системы. Это совокупность времени для поиска ошибок и диагностики + время на восстановление. Это итоговая метрика.
-
MTBF - Mean Time Between Failures (ожидаемое время между отказами). Это наработка на отказ. Дается производителем.
Эти метрики зависят от стоимости системы.
Резервирование стоит денег. Оно бывает холодное (на складе лежит запас) и горячее (оборудование в готовности, работает в тандеме).
При использовании горячего резервирования восстановление очень быстрое.
Средства сбора и поиска ошибок
-
NMS
-
Есть так же Средства в ОС:
– управляющие виртуальные продукты (эмуляторы). В составе любой ОС должны быть эмулирующие продукты. Весь софт переписать нельзя, поэтому есть стандарты на протоколы эмуляции. OSI придумали виртуальные терминалы. Также есть telnet (его ввели разработчики Internet), hyperterminal, SSH (telnet только защищенный);
– утилита «Монитор». Она частично выполняет функции NMS: собирает статистику, загружает ее при загрузке ОС или при запуске приложения (сессии), опрос устройства. Т.е это не выделенный сервер мониторинга.
-
Дополнительные продукты:
– для активного поиска ошибок используются эмуляторы трафика (когда нужно нагрузить систему), симуляторы атак, симуляторы ошибок (большого количества коллизий);
– специализированные утилиты ping, track root и др.;
– браузеры базы данных MIB.
Но это все помогает только от ошибок софта. Есть специальные средства hardware – протокольные анализаторы, кабельные анализаторы, пробы, специализированные сетевые адаптеры, которые позволяют прослушивать всё, что происходит в сетях вообще. Это все позволяет обнаружить hardware ошибки.
Ранжирование ошибок:
– Каналы связи – 1 (80 % всех ошибок);
– Hardware – 4;
– Системный софт – 3;
– Прикладной софт – 2.
Тираж hardware больше, чем тираж software (например, сколько выпускается сетевых адаптеров Intel), поэтому hardware ошибок будет меньше, чем software.
Аналогично тираж системного софта больше, чем тираж прикладного, поэтому в первом меньше ошибок, чем в последнем.
-
Дайте инструкцию по организации НСД в системе.
Инструкция:
-
Установка паролей.
-
Защищать сетевые устройства (коммутаторы) паролями в зашифрованном виде средствами ОС.
-
Защита методами доступа (организационные, аппаратные, программные (не давать доступ в Интернет с любого компьютера)).
-
По привилегиям защита консоля.
-
Защита на уровне эмулирующих (виртуальных) программ.
Задачи администратора по организации защиты:
1.кабельные системы в коробах, спец трубах, местах, где нет доступа. Сделать отсутствие доступа к кабельным системам.
Есть специальная аппаратура для снятия информации, проходящей по меди. Для медных кабелей должны быть экранированные трубы, короба.
2. Защита помещений. Все помещения должны быть запираемые. Разные сотрудники имеют разные права доступа в помещения. Должны быть кодовые замки. Вести журнал доступа к оборудованию системы с подписями тех, кто входил/выходил. Внутренняя система и внешняя система. Внутренняя система не имеет выхода во внешнюю систему (кабеля нет).
3. Защищать доступ к электрическим сетям. Доступ к ГРЩ и РЩ запрещается, ставятся фильтры, которые не позволяют получать доступ к полю электрических сетей.
4.Обязательно структурируем систему. Система модульная. Отсечка системы делается патч-панелями, не только для коммутации, но и легкой пожаробезопасности (вертикаль(оптика) и горизонталь(витая пара) здания).