

1. Основные направления исследований в области искусственного интеллекта
Интеллектуальные информационные системы проникают во все сферы нашей жизни, поэтому трудно провести строгую классификацию направлений, по которым ведутся активные и многочисленные исследования в области ИИ. Рассмотрим кратко некоторые из них.
Разработка интеллектуальных информационных систем или систем, основанных на знаниях. Это одно из главных направлений ИИ. Основной целью построения таких систем являются выявление, исследование и применение знаний высококвалифицированных экспертов для решения сложных задач, возникающих на практике. При построении систем, основанных на знаниях (СОЗ), используются знания, накопленные экспертами в виде конкретных правил решения тех или иных задач. Это направление преследует цель имитации человеческого искусства анализа неструктурированных и слабоструктурированных проблем. В данной области исследований осуществляется разработка моделей представления, извлечения и структурирования знаний, а также изучаются проблемы создания баз знаний (БЗ), образующих ядро СОЗ. Частным случаем СОЗ являются экспертные системы (ЭС).
Разработка естественно-языковых интерфейсов и машинный перевод. Проблемы компьютерной лингвистики и машинного перевода разрабатываются в ИИ с 1950-х гг. Системы машинного перевода с одного естественного языка на другой обеспечивают быстроту и систематичность доступа к информации, оперативность и единообразие перевода больших потоков, как правило, научно-технических текстов [1]. Системы машинного перевода строятся как интеллектуальные системы, поскольку в их основе лежат БЗ в определенной предметной области и сложные модели, обеспечивающие дополнительную трансляцию «исходный язык оригинала — язык смысла — язык перевода». Они базируются на структурно-логическом подходе, включающем последовательный анализ и синтез естественно-языковых сообщений. Кроме того, в них осуществляется ассоциативный поиск аналогичных фрагментов текста и их переводов в специальных базах данных (БД). Данное направление охватывает также исследования методов и разработку систем, обеспечивающих реализацию процесса общения человека с компьютером на естественном языке (так называемые системы ЕЯ-общения) [1].
Генерация и распознавание речи. Системы речевого общения создаются в целях повышения скорости ввода информации в ЭВМ, разгрузки зрения и рук, а также для реализации речевого общения на значительном расстоянии. В таких системах под текстом понимают фонемный текст (как слышится).
Обработка визуальной информации. В этом научном направлении решаются задачи обработки, анализа и синтеза изображений [1]. Задача обработки изображений связана с трансформированием графических образов, результатом которого являются новые изображения. В задаче анализа исходные изображения преобразуются в данные другого типа, например в текстовые описания. При синтезе изображений на вход системы поступает алгоритм построения изображения, а выходными данными являются графические объекты (системы машинной графики).
Обучение и самообучение. Эта актуальная область ИИ включает модели, методы и алгоритмы, ориентированные на автоматическое накопление и формирование знаний с использованием процедур анализа и обобщения данных [4]. К данному направлению относятся не так давно появившиеся системы добычи данных (Data-mining) и системы поиска закономерностей в компьютерных базах данных (KnowledgeDiscovery).
Распознавание образов. Это одно из самых ранних направлений ИИ, в котором распознавание объектов осуществляется на основании применения специального математического аппарата, обеспечивающего отнесение объектов к классам [2], а классы описываются совокупностями определенных значений признаков.
Игры и машинное творчество. Машинное творчество охватывает сочинение компьютерной музыки, стихов, интеллектуальные системы для изобретения новых объектов. Создание интеллектуальных компьютерных игр является одним из самых развитых коммерческих направлений в сфере разработки программного обеспечения. Кроме того, компьютерные игры предоставляют мощный арсенал разнообразных средств, используемых для обучения.
Многие ранние исследования в области поиска в пространстве состояний совершались на основе таких игр, как шашки, шахматы и пятнашки.
Большинство игр ведутся с использованием определенного набора правил: это позволяет легко строить пространство поиска. Игры могут порождать необычайно большие пространства состояний. Для поиска в них требуются мощные методики, определяющие, какие альтернативы следует рассматривать. Такие методики называются эвристиками и составляют значительную область исследований ИИ. Эвристика — это стратегия полезная, но потенциально способная упустить правильное решение.
Программы ведения игр ставят новые вопросы, включая вариант, при котором ходы противника невозможно предугадать. Наличие противника усложняет структуру программы, добавляя элемент непредсказуемости.
Автаматические рассуждения и доказательства теорем — это одна из старейших частей ИИ. Благодаря исследованиям в этой области были формализованы алгоритмы поиска и разработаны языки формальных представлений, такие как исчисления предикатов и логический язык программирования PROLOG.
Программное обеспечение систем ИИ. Инструментальные средства для разработки интеллектуальных систем включают специальные языки программирования, ориентированные на обработку символьной информации (LISP, SMALLTALK, РЕФАЛ), языки логического программирования (PROLOG), языки представления знаний (ОРS5,KRL,FRL), интегрированные программные среды, содержащие арсенал инструментальных средств для создания систем ИИ (КЕ,ARTS,GURU,G2), а также оболочки экспертных систем (BULD,EMYCIN,EXSYSProfessional, ЭКСПЕРТ), которые позволяют создавать прикладные ЭС, не прибегая к программированию [3].
Новые архитектуры компьютеров. Это направление связано с созданием компьютеров не фон-неймановской архитектуры, ориентированных на обработку символьной информации. Известны удачные промышленные решения параллельных и векторных компьютеров [3], однако в настоящее время они имеют весьма высокую стоимость, а также недостаточную совместимость с существующими вычислительными средствами.
Интеллектуальные роботы. Создание интеллектуальных роботов составляет конечную цель робототехники. В настоящее время в основном используются программируемые манипуляторы с жесткой схемой управления, названные роботами первого поколения. Несмотря на очевидные успехи отдельных разработок, эра интеллектуальных автономных роботов пока не наступила. Основными сдерживающими факторами в разработке автономных роботов являются нерешенные проблемы в области интерпретации знаний, машинного зрения, адекватного хранения и обработки трехмерной визуальной информации.
ЛОГИКА ПРЕДИКАТОВ
Мы выяснили, что язык очень важен для теории. Языков очень много, очень разных. И вот очень популярный язык, который используется для построения формальных теорий и называется языком ЛОГИКИ ПРЕДИКАТОВ.
Вот если мы возьмем простое предложение, то там есть подлежащие и сказуемое. Логика предикатов – это на самом деле логика сказуемых. В простом предложении есть подлежащие и сказуемое, язык почему-то выделяет сказуемое и ставит его в цент все построений. И всякими добавками, выводами и т.д. дает вам инструмент для того, что бы вы построили практически любую формальную теорию. А сказуемое, потому что вы сказуете чего-то, причем вы сказуете о том, что под этим словом лежит (вот почему подлежащие). Назвать можно что угодно, а вот сказать надо то, что к месту сейчас и то, что важно. Вот вы назвали, а потом сказали, вы могли сказать правильно, а могли и не правильно. Ложь не входит в то множество семантически правильных предложений. Если я буду проверять правильно я сказал или нет, я буду по сути дела проверят разные формулу, теоремы.
И вы сказуете обычно о том, что у чего-то есть какое-то свойство – это является вашим базовым сказанием. «Сидоров высокий» например. Более нейтральное слово, которое можно использовать вместо «свойство», это «признак».
И этот признак распознавать надо. А вот что за система распознавания, которая скажет да или нет. Факт в том заключается, что распознавать приходиться постоянно.
От распознавания в искусственном интеллекте не уйдешь. Вам понадобятся знаки, что бы распознавать и системы проверки. Система распознавания образов – это лингвистическая компетенция.
Логика сказуемых заводит свои правила на запись предложений. Простое предложение надо переписать вот как:
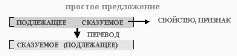
Здесь то, что сказуется стоит под знаком. И через запятую надо обязательно записать «да» или «нет». Мозг работает экономно, и может запомнить «да»или «нет». «Волга впадает в Каспийское море, Да» - «да» писать не надо, запомниться. Категория истинности, как таблица умножения работает у нас. Факт, одно язык, который мы употребляем, другое это этот язык. Значит, нужна система перевода. Когда мы записываем, мы должны все лишнее убрать, что не имеет отношение к экономному кодированию признаков или к экономному кодированию подлежащего, и вообще, что не имеет отношение. К логике предикатов не имеют отношение: может быть, вероятно, разные нормы которое определяют человеческое поведение, должен (в природе ни кто вам не должен!). Через сито перевода проходит только то, что имеет действительное отношение к регистрации факта, признак можно записать со знаком и за этим может стоять реально существующее в природе. Вообще-то простых предложений две формы:
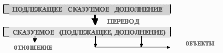
Одна форма говорит, что свойство принадлежит объекту, а вторая, что есть отношения между двумя объектами. Язык предикатов уравнивает подлежащие и дополнение с позиции реальности - две вещи. Начали сказывать с подлежащего одна версия записи появляется, а с дополнения вторая запись кода. Но в реальности – существуют две вещи и отношения между ними. Логика предикатов, переводя, избавляется от всего лишнего. Логика предикатов интересна тем, что заглядывает внутрь предложения и приписывает ему значения истинности или лжи в зависимости от того в каком отношении находятся подлежащие и сказуемое. А вот логика высказываний проще, ей все равно что там за подлежащие, что там за сказуемое, она не заглядывает внутрь предложения. Ее интересует тот факт, что такое предложение существует и вообще истинно оно или ложно. Логика высказываний очень близка к логике предикатов по своим конструкциям, очень многие формулы одинаковы или похожи.
На слайде: существуют два типа категорических высказываний:
Все S есть P. (Все люди млекопитающие)
Некоторые S есть P.
Для логики предикатов слова «все» и «некоторые» важны. И в логике предикатов есть специальные знаки для изображения различных конструкций – это так называемые кванторы (за ним ALL стоит) и существует (EXIST).
S(x) и P(x) , кванторы - All , - Exist
SaP : x (S(x) P(x)). Это запись Все S есть P. Т.е. для каждого х, который является объектом, он имеет эти свойства.
«Нет столь великой
вещи, которую не превзошла бы величиной
ещё большая. Нет вещи столь малой, в
которую не поместилась бы меньшая»
Козьма Прутков
Если есть один язык и нам надо перевести на другой, надо действовать.
Пример изречения приведен на слайде:
Надо начинать перевод со сказуемых, за сказуемым лежит то, что вы сказуете, а сказуете вы то, что у вещи есть такой то признак. Надо искать свойства и отношения. «Великая» это сравнительное свойство – отношение (признак), так есть вещи которые сравниваются. Употребляются сравнительный призанак т.е. надо искать предложение типа «Некоторые S есть P».
Два отношения там названы: «больше» и «меньше». А «большая» и «меньшая» это названы вещи. «Нет столь великой вещи» - назван целый класс, придется использовать кванторы.
Полученная формула: { - v w больше (w,v)} &{ y x меньше(x,y)}
(для любой v найдется w, для которого справедливо «большая», а для любого y найдется такой х, что будет справедливо «меньшая»).
Следующий пример:
Сидоров и Петров друзья.
Они всегда вместе.
Сидоров в институте.
Где Петров?
Если правильно записать этот текст на «прологе» (язык такой), запустить интерпретатор, то он ответит, что Петров в институте (для этого необходимо перевести на язык предикатов первого порядка.).
С какого предложения вы начнете перевод? С третьего «Сидоров в институте» - подходит под формулу сказуемое(одна единица, вторая), т.е. в(Сидоров, институт) и дает нам ключ к переводу следующего. Какое было предложение такое и останется, только форма маленько изменяется. Будем считать его базовым, т.е. базовый предикат находиться_в(персона, место), в(персона, место). Абстрагируемся от Сидорова от института – появилось место, персона. находиться_в(персона, место) – это объект, а в(Сидоров, институт) – экземпляр. Далее думаем, можем мы еще какие экземпляры составить, используя данный предикат. Следующее по простоте перевода является 4 предложение, записать его можно, используя объект.
x в(Петров, x)
Записываем: существует такое место, где находится Петров, но я его не знаю. Далее проще будет записать первое предложение: x {в(Cидоров, x) в(Петров, x) }. Знак «И»
На том основании, что «Сидоров и Петров друзья», если бы у них были другие отношения, тогда бы был другое знак возможно.
Этим примером я хотел, показать что при переводе возникают такие же проблемы, что и при переводе на любой естественный язык (с русского на иностранный). Приходится догадываться, что он там закодировал, а не верить словам. Слова верить нельзя, всегда надо пытаться раскодировать то, что за этим словами скрыто.
Этот перевод упрощает нам решение задачи. Доказано в логике предикатов, что если у вас есть какой-то текст, записанный на этом языке, любой вопрос я могу так пропустить на обработку через весь текст, что извлеку отдута ответ. Чем и пользуются в автоматических программах решениях задач. Программа найдет х, потому что истинна, что Сидоров в институте.
Возникает такой вопрос, что же если любую программу, любой текст записать на языке предикатов первого порядка, а потом толкнуть в любую программу, она мне и ответ даст. Получается, что любую задачу можно решить, если ее текст записать на языке логики предикатов. Но сможете или вы записать текст, удастся или нет записать вам этот текст, зависит от ваших переводческих способностей.
Ваша задача как программиста, это перевести, занести в программу и ждать ответ, который выдаст вам программа. Если ответ вас не устраивает, то надо смотреть исходный код и искать в нем ошибку. Языки, которые занимаются данными задачами – называют, декларативные языки. В разных странах свои любимые языки.
Мы привели примеры и показали, что есть такой подход, есть такая возможность. А если говорить о том, что писать, проверят, читать и слушать надо строже язык определить. А если мы определяем язык строже, значит надо снять все точки «над и». Встает вопрос, как записывать различные экземпляры объектов (предметных единиц)? Предметные константы – имя собственные объектов. Причем 34 яблока и 34 груши это совершенно разные вещи. Переменная – это имена классов (персона, место, вещь). Предикатные константы – это отношения и свойства (для чисел – больше, меньше, равно). Есть алгебра предикатов и исчисление предикатов первого порядка. Алгебра всегда настроена на операциях (знаки и латинские буквы). В языке должны быть логические константы и знаки. Правильные предложения – это отношения, а в скобках названные предметные единицы (константы и переменные). Беру и записываю больше(х,5), я не знаю какой х. Я говорю х=10, надо говорить нет, потому что любое предложение не явно содержит «Да» или «Нет». А если я пишу больше(3,5). Мы не договорились на каком месте большее стоит, но если я сказал «х=10» и «нет», значит я указал на каком месте большее стоит, только неявно.
Когда я пишу просто предложение на языке предикатов первого порядка его принято называть на формальном языке литералом. В программирование литералом называют константу, которая пишется на мете адреса (в ассемблере). Но здесь литералом называют или сам предикат, или его отрицание. Переходим к предложениям. Самое простое предложение есть атом (литерал). Если два атома соединены любым логическим знаком, то это правильное предложение (формула). Если к любой формуле логическим знаком присоединить атом, то это тоже правильное предложение записанное. Таким образом, мы строим более сложные конструкции.
Мы этот язык используем для построения теорий, т.е. для решения каких-то задач. Мы сейчас с вами говорим о числах и об отношениях между числами. Вот я хочу построить теорию отношения между числами. Значит, в первую очередь я должен аксиомы ввести. Первая аксиома: вот если я возьму два числа, то они либо равны, либо больше, либо меньше.
Если два числа в отношении больше, то они не могут быть меньше. Это тоже аксиома.
P1 | P2 | P3 , P1 P2 , P1 P3 , P2 P3 – между числами «или», если Р1 следует не Р2 , если Р1 следует не Р3 , если Р2 следует не Р3 . Нельзя меньше, нет смысла больше. Нет больше аксиом, потому что нет смысла больше.
РАСПОЗНОВАНИЕ ОБРАЗОВ.
Распознавание образов – это одна из предметных областей, которая очень активно исследуется в рамках искусственного интеллекта. В ходе исследований было получено очень много интересных результатов. Тематика эта встала как отдельная раньше, чем искусственный интеллект. Распознавать образы пробовали давно и с разными целями. Распознавание образов – это специфическое направление связанное с радиосигналами, с передачей кодов по радиосвязи. Но это задача связи, и как-то к искусственному интеллекту мало относится. Но опыт там громадный, причем опыт вероятностного оценивания, различного вероятностного описания, прогнозирования и всего остального.
Распознавание образов – это специфический вид задач и принятия решений, там от реальности никак не удается уйти и первый слой, откуда поступает информация – это слой первичных датчиков. В разных задачах свои датчики (сенсорные датчики). Т.е. все начинается с контакта с окружающей средой, контакт с окружающей средой всегда в конкретной области, в конкретных точках или плоскостях.
Интеррогативная логика
- раздел современной символической логики, исследующий логико-семантические свойства вопросительных предложений. Существуют два подхода к построению формальной теории вопросов, которые условно называются "лингвистическим" и "компьютерным". Согласно первому подходу, материалом для построения формальных описаний вопросов служат реально существующие вопросы естественного языка с произвольной, неспециализированной семантикой. В рамках этого подхода строится перевод вопроса на формальный язык, в котором исследуется соответствующее вопросу формальное представление. Согласно второму подходу, исходным материалом для формализации вопроса является формальный язык, используемый в информационной системе, ориентированной на решение некоторой совокупности информационно-поисковых задач. Формализация вопросов в информационном языке осуществляется на базе проблемно ориентированной семантики, а именно: каждому типу вопросов соответствует специальное вопросно-ответное отношение, характер которого зависит от семантики. Таким образом, в рамках этого подхода вопрос понимается как запрос - требование информации определенного типа, адресованное к информационной системе.