

Задание 6. Извлечение данных в определенном порядке
Если строки, извлеченные по запросу, должны перечисляться в определенном порядке, для этого используется конструкция ORDER BY оператора SELECT. Эта особенность удобна для представления результатов запроса в удобочитабельном формате.
Конструкция ORDER BY применяется для сортировки строк в столбцах, указанных в конструкции SELECT. Например,
select name, address
from customers
order by name ;
Рис. 3.251. Сортировка результата с помощью ORDER BY в MySQL.
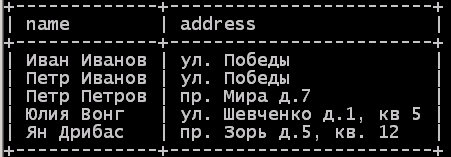
Рис. 3.252. Результат сортировки результата с помощью ORDER BY.
Такой запрос представит имена клиентов в алфавитном порядке по именам name.
Примечание. Обратите внимание, что в таком случае, поскольку имена состоят из имени и фамилии, отсортированы они будут по имени. Если вы хотите сортировки по фамилии (которая стоит второй), нужно, чтобы имя и фамилия хранились в двух разных полях.
По умолчанию порядок сортировки идет по возрастанию (от а до z или по возрастанию числовых значений). Это можно указать ключевым словом ASC (от англ, ascending):
select customerid,address, name
from customers
order by address asc;

Рис. 3.253. Результат сортировки результата с помощью ORDER BY ASC.
Изменить порядок сортировки на обратный можно с помощью другого ключевого слова — DESC (от англ, descending):
select address, name
from customers
order by address desc;
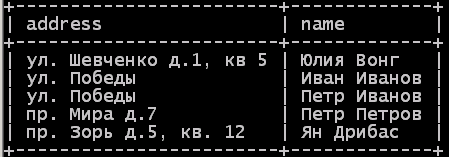
Рис. 3.254 13.27. Результат сортировки результата с помощью ORDER BY DESC.
Сортировать можно и по нескольким столбцам. Вместо названий можно использовать псевдонимы столбцов, и даже их порядковые номера (например, 3 — для третьего столбца в таблице) см. [7].
Задание 7. Группировка и агрегирование данных
Нередко необходимо подсчитать, сколько строк присутствует в определенном наборе, или каково среднее значение какого-нибудь столбца — скажем, средняя цена каждого заказа. В MySQL имеется набор функций агрегирования, которые неплохо подходят для выполнения задач подобного рода.
Эти функции агрегирования можно применять как для таблицы в целом, так и для групп данных внутри таблицы.
Наиболее часто используемые функции перечислены в таблице показанной на рис. 3.255.
|
Название |
Описание |
|
AVG (столбец) |
Средняя величина значений в определенном столбце. |
|
COUNT (элементы) |
При указании столбца выдается количество числовых ненулевых) значений в этом столбце. Если перед названием столбца вставить слово DISTINCT, выдается только количество конкретных значений в столбце. Если указать COUNT (*) — подсчет строк будет производиться независимо от нулевых значений. |
|
MIN (столбец) |
Минимальное значение в столбце. |
|
МАХ (столбец) |
Максимальное значение в столбце. |
|
STD (столбец) |
Стандартное отклонение значений в столбце. |
|
SUM (столбец) |
Сумма значений в столбце. |
Рис. 3.255. Функции агрегирования в MySQL.
Взглянем на несколько примеров, начиная с AVG. Среднюю величину всех заказов можно высчитать так:
select avg (amount)
from orders;

Рис. 3.256. Результат AVG по столбцу amount таблицы orders.
Чтобы получить более детальную информацию, можно воспользоваться конструкцией GROUP BY. Это позволит посмотреть среднюю величину заказа по группам, например, по номеру клиента, что даст информацию о том, кто из клиентов делает самые крупные заказы:
select customerid, avg (amount)
from orders
group by customerid;
При использовании конструкции GROUP BY с функцией агрегирования это фактически меняет поведение функции. Вместо того чтобы выдавать среднюю величину заказов в таблице, такой запрос даст информацию по средней величине заказа каждого клиента (а если точнее, каждого customerid)

Рис. 3.257. Результат AVG с группировкой по Клиентам.
Единственное, что стоит отметить при использовании функций группировки и агрегирования: если используется функция агрегирования или конструкция GROUP BY в ANSI SQL, в конструкции SELECT будут присутствовать только функции агрегирования и столбцы, указанные в конструкции GROUP BY. Если требуется использовать столбец в конструкции GROUP BY, он должен быть указан в конструкции SELECT.
На самом деле MySQL обеспечивает гораздо большую свободу действий, поддерживая расширенный синтаксис, который дает возможность убирать ненужные элементы из конструкции SELECT.
Вдобавок к группировке и агрегированию данных есть все шансы проверить результат агрегирования с использованием конструкции HAVING. Она следует сразу после конструкции GROUP BY и похожа на WHERE, но только применяется к группам и множествам.
Чтобы расширить предыдущий пример, скажем, получением информации, кто из клиентов произвел заказ в среднем больше чем на $50, можем воспользоваться следующим запросом:
select customerid, avg (amount)
from orders
group by customerid
having avg (amount) > 50;
Заметьте, конструкция HAVING обращается к группам. Такой запрос выдаст следующий результат:
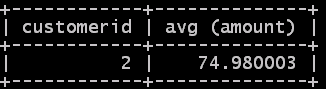
Рис. 3.258. Результат AVG с группировкой по HAVING.
Выбор количества отображаемый строк
Одна конструкция оператора SELECT, которая может оказаться особенно полезной в Web-приложениях — это конструкция LIMIT. Ее используют для указания, сколько строк результата следует отображать. Необходимы два параметра: номер строки, с которой следует начать, и количество строк.
Следующий запрос иллюстрирует применение LIMIT:
select name, address, city
from customers
limit 2, 3;
Запрос можно интерпретировать так: "Выбрать имена среди клиентов, в результате отобразить три строки, начиная со строки 2". Не забывайте, что нумерация строк начинается с нуля.
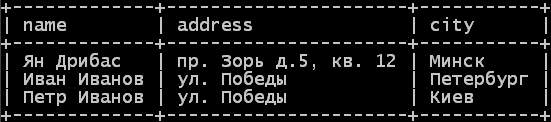
Рис. 3.259. Результат применения LIMIT.
Это очень удобная конструкция для Web-приложений. Ее принцип точно такой же, как и в случае, когда покупатель листает каталог и хочет видеть на одной странице только 10 пунктов.
Примечание. Обратите внимание, что LIMIT в стандарте ANSI SQL отсутствует, потому его использование приводит к несовместимости кода со многими реляционными СУБД.