

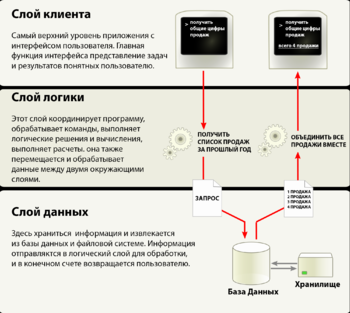
Архитектура Баз данных. Назначение и основные компоненты систем баз данных.
Трёху́ровневая архитекту́ра, (англ. three-tier или англ. Multitier architecture) — архитектурная модель программного комплекса, предполагающая наличие в нём трёх компонентов: клиентского приложения (обычно называемого «тонким клиентом» или терминалом), сервера приложений, к которому подключено клиентское приложение, и сервера базы данных, с которым работает сервер приложений.
Обзор архитектуры
Клиент — это интерфейсный (обычно графический) компонент, который представляет первый уровень, собственно приложение для конечного пользователя. Первый уровень не должен иметь прямых связей с базой данных (по требованиям безопасности), быть нагруженным основной бизнес-логикой (по требованиям масштабируемости) и хранить состояние приложения (по требованиям надежности). На первый уровень может быть вынесена и обычно выносится простейшая бизнес-логика: интерфейс авторизации, алгоритмы шифрования, проверка вводимых значений на допустимость и соответствие формату, несложные операции (сортировка, группировка, подсчет значений) с данными, уже загруженными на терминал.
Сервер приложений располагается на втором уровне. На втором уровне сосредоточена бо́льшая часть бизнес-логики. Вне его остаются фрагменты, экспортируемые на терминалы (см.выше), а также погруженные в третий уровень хранимые процедуры и триггеры.
Сервер базы данных обеспечивает хранение данных и выносится на третий уровень. Обычно это стандартная реляционная или объектно-ориентированная СУБД. Если третий уровень представляет собой базу данных вместе с хранимыми процедурами, триггерами и схемой, описывающей приложение в терминах реляционной модели, то второй уровень строится как программный интерфейс, связывающий клиентские компоненты с прикладной логикой базы данных.
В простейшей конфигурации физически сервер приложений может быть совмещён с сервером базы данных на одном компьютере, к которому по сети подключается один или несколько терминалов.
В «правильной» (с точки зрения безопасности, надёжности, масштабирования) конфигурации сервер базы данных находится на выделенном компьютере (или кластере), к которому по сети подключены один или несколько серверов приложений, к которым, в свою очередь, по сети подключаются терминалы.
Уровни представления баз данных. Понятие схемы и подсистемы.
В процессе научных исследований, посвященных тому, как именно должна быть устроена СУБД, предлагались различные способы реализации. Самым жизнеспособным из них оказалась предложенная американским комитетом по стандартизации ANSI (American National Standards Institute) трехуровневая система организации БД, изображенная на рис.
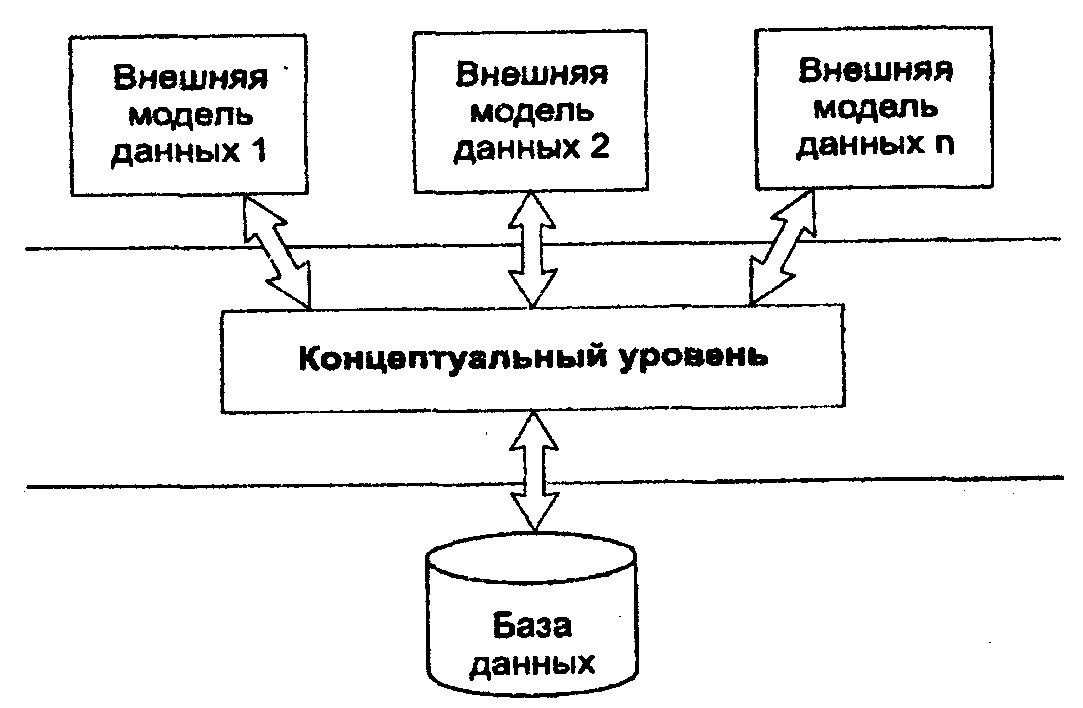
1. Уровень внешних моделей - самый верхний уровень, где каждая модель имеет свое «видение» данных. Этот уровень определяет точку зрения на БД отдельных приложений. Каждое приложение видит и обрабатывает только те данные, которые необходимы именно этому приложению.
2. Концептуальный уровень - центральное управляющее звене здесь база данных представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями, работающими с данной базой данных. Фактически концептуальный уровень отражает обобщенную модель предметной области (объектов реального мира), для которой создавалась база данных. Как любая модели концептуальная модель отражает только существенные, с точки зрения обработки, особенности объектов реального мира.
3. Физический уровень - собственно данные, расположенные в файлах или в страничных структурах, расположенных на внешних носителях информации.
Эта архитектура позволяет обеспечить логическую (между уровнями 1 и 2) и физическую (между уровнями 2 и 3) независимости при работе с данными. Логическая независимость предполагает возможность изменения одного приложения без корректировки других приложений, работающих с этой же базой данных. Физическая независимость предполагает возможность переноса хранимой информации с одних носителей на другие при сохранении работоспособности всех приложений, работающих с базой данных. Это именно то, чего не хватало при использовании файловых систем.
Если бы назначением базы данных (БД) было только хранение данных, то ее структура была бы простой. Причина ее сложности в том, что она должна обеспечивать связи.
Прежде всего следует обсудить способ, с помощью которого пользователи БД представляют эти связи.
Структуру данных необходимо описывать формализованным образом. Описания логической и физической структур БД используется программными средствами управления БД при обработке требований пользователей на получение той информации, которую содержит БД. Описание логической структуры БД называется схемой. Схема представляет собой таблицу типов используемых данных. Она содержит имена объектов и их атрибуты и указывает на существующую между ними связь. Если схема содержит значения элементов данных, как на рис. 7. Ее называют экземпляром схемы.
На рис. 10 приведен пример схемы:
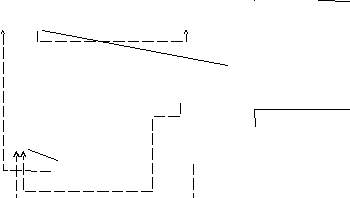
Рис.10
Сплошные линии, соединяющие блоки, отображают связи. Запись Заказ_на_закупку связана с записями Статья_закупки, в которых содержится заказ на закупку. Запись Поставщик связана с записями Расценка, описывающими поставляемые товары и расценки. Связи на схеме могут обеспечивать передачу такой информации, которая не представлена конкретными элементами данных, показанными на схеме.
Штриховые линии отображают перекрестные ссылки. Они не обеспечивают передачу дополнительной информации и если их убрать, то потери информации не произойдет.
Термин схема используется для определения полной таблицы всех типов элементов данных и типов записей, хранимых в БД. Термином подсхема определяют описание данных, которое использует ПП – лист. На основе одной схемы можно составить много различных подсхем. Например, на рис. 11 приведены подсхемы двух ПП – листов. Программисты имеют различные представления о данных, но обе подсхемы получены из схемы, приведенной на рис. 11.
Подсхема программиста А

Подсхема программиста В
Ни схемы, ни подсхемы не отражают способов физического запоминания данных. Существует 4 различных вида описания данных:
подсхема – таблица, описывающая ту часть данных, которая ориентирована на нужды одной или нескольких прикладных программ.
глобальное описание логической структуры БД или схема – таблица, логически описывающая всю БД. Она отражает представление о данных администратора БД.
описание физической организации БД – таблица физического расположения данных на носителях информации. Это представление о данных нужно системному программисту, который занимается вопросами эффективности работы системы, расположения или поиска, а также вопросами использования методов сжатия данных.
описание данных, которое система передает пользователю терминала БД как можно более близким к тому описанию данных, которое он использует в своей работе.
3 Логические модели представления данных в бд. Способы отображения взаимосвязей элементов данных.
Хранимые в базе данные имеют определенную логическую структуру, иными словами, описываются некоторой моделью представления данных (моделью данных), поддерживаемой СУБД. К числу классических относятся следующие модели данных:
• иерархическая;
• сетевая;
• реляционная.
Кроме того, в последние годы появились и стали более активно внедряться на практике следующие модели данных:
• постреляционная;
• многомерная;
• объектно-ориентированная.
В иерархической модели связи между данными можно описать с помощью упорядоченного графа (или дерева), т. е. поддерживается связь типа 1:М. Упрощенно представление связей между данными в иерархической модели показано на рис.
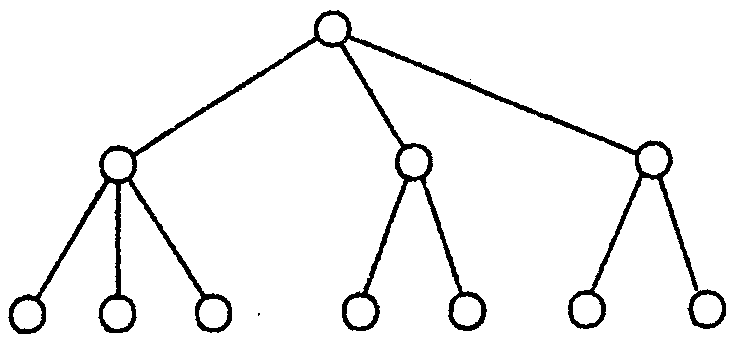
Для описания структуры (схемы) иерархической БД на некотором языке программирования используется тип данных «дерево».
Тип «дерево» является составным. Он включает в себя подтипы ("поддеревья"), каждый из которых, в свою очередь, является типом «дерево». Каждый из типов «дерево» состоит из одного «корневого» типа и упорядоченного набора (возможно пустого) подчиненных типов.
К достоинствам иерархической модели данных относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения основных операций над данными. Иерархическая модель данных удобна для работы с иерархически упорядоченной информацией.
Недостатками иерархической модели являются ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя.
Сетевая модель данных позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа, обобщая тем самым иерархическую модель данных Реализуются связи 1:М и М:М.
Для описания схемы сетевой БД используются две группы типов: «запись» и «связь». Тип «связь» определяется для двух типов «запись»: предка и потомка. Переменные типа «связь» являются экземплярами связей.
Сетевая БД состоит из набора записей и набора соответствующих связей. На формирование связи особых ограничений не накладывается. Если в иерархических структурах запись-потомок могла иметь только одну запись-предка, то в сетевой модели данных запись-потомок может иметь произвольное число записей-предков (сводных родителей).
Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. В сравнении с иерархической моделью сетевая модель предоставляет большие возможности в смысле допустимости образования произвольных связей.
Недостатками сетевой модели данных являются высокая сложность и жесткость схемы БД, построенной на ее основе, а также сложность для понимания и выполнения обработки информации в БД обычным пользователем. Кроме того, в сетевой модели данных, ослаблен контроль целостности связей вследствие допустимости усыновления произвольных связей между записями.
Реляционная модель данных предложена Э. Коддом и основывается на понятии «отношение» (relation).
Отношение представляет собой множество элементов, называемых кортежами. Наглядной формой представления отношения является привычная для человеческого восприятия двумерная таблица.
Таблица имеет строки (записи) и столбцы (колонки). Каждая строка таблицы имеет одинаковую структуру и состоит из полей. Строкам таблицы соответствуют кортежи, а столбцам - атрибуты отношения.
С помощью одной таблицы удобно описывать простейший вид связей между данными, а именно деление одного объекта (явления, сущности, системы и прочее), информация о котором хранится в таблице, на множество подобъектов, каждому из которых соответствует строка или запись таблицы. При этом каждый из подобъектов имеет одинаковую структуру или свойства, описываемые соответствующими значениями полей записей.
Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого использования. Проблемы же эффективности обработки Данных этого типа оказались технически вполне разрешимыми.
Основными недостатками реляционной модели являются следующие: отсутствие стандартных средств идентификации отдельны; записей и сложность описания иерархических и сетевых связей.
Постреляционная модель данных представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных, хранящихся в записях таблиц. Постреляционная модель данных допускает многозначные поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу.
Помимо обеспечения вложенности полей постреляционная модель поддерживает ассоциированные многозначные поля (множественные группы). Совокупность ассоциированных полей называется ассоциацией. При этом в строке первое значение одного столбца ассоциации соответствует первым значениям всех других столбцов ассоциации. Аналогичным образом связаны все вторые значения столбцов и т. д.
Достоинством постреляционной модели является возможности представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Это обеспечивает высокую наглядность представления информации и повышение эффективности ее обработки.
Недостатком постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных.
Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации. Основные понятия, используемые в этих СУБД, - это агрегируемость, историчность и прогнозируемость данных.
Агрегируемость данных означает рассмотрение информации на различных уровнях ее обобщения.
Историчность данных предполагает обеспечение высокого уровня статичности (неизменности) собственно данных и их взаимосвязей, а также обязательность привязки данных ко времени.
Статичность данных позволяет использовать при их обработке специализированные методы загрузки, хранения, индексации и выборки.
Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам.
Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными.
Основными достоинствами многомерной модели данных являются удобство и эффективность аналитической обработки больших объемов данных, связанных со временем. При организации обработки аналогичных данных на основе реляционной модели происходит нелинейный рост трудоемкости операций в зависимости от размерности БД и существенное увеличение затрат оперативной памяти на индексацию.
Недостатком многомерной модели данных является ее громоздкость для простейших задач обычной оперативной обработки информации.
В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы. Между записями базы данных и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования.
Поиск состоит в выяснении сходства между объектом, задаваемым пользователем, и объектами, хранящимися в БД. Определяемый пользователем объект (объект-цель) в общем случае может представлять собой подмножество всей хранимой в БД иерархии объектов.
Основным достоинством объектно-ориентированной модели данных в сравнении с реляционной является возможность отображения информации в сложных взаимосвязях объектов. Объектно-ориентированная модель данных позволяет идентифицировать отдельную запись базы данных и определять функции их обработки.
Недостатками объектно-ориентированной модели являются высокая понятийная сложность, неудобство обработки данных и низкая скорость выполнения запросов.