

6 Опытная эксплуатация


Модификация
Требования1 Идентификация
2 Концептуализация
5 Тестирование
Модификация



Усовершенствование4 Выполнение
Переформулирование


Переконструирование(???)
Понятия
Структура знаний3 Формализация
Математическая модель МакКаллока - Питтса.
Гипотеза математического нейрона (статья впервые опубликована в 43-м году).
Математический нейрон имеет несколько входов и 1 выход. Через входы, число которых обозначим J, математический нейрон принимает входные сигналы xj, которые суммируют, по схеме умножения на определенный коэффициент.
∑
x1 J





xj … S
S
Причем, S
– суммарная функция, а сам выход ![]() , где θ –
порог чувствительности нейрона.
, где θ –
порог чувствительности нейрона.
y

1


S θ

Весовые коэффициенты имитируют электропроводность нервных волокон, силу, так называемых синоптических связей.
Чем выше коэффициент, тем больше вероятность перехода нейронов в возбужденное состояние.
Функция y называется активационной функцией нейрона. В общем случае она может иметь и другие виды.







S S S S






Следует отметить, что некоторые входы могут быть отрицательными, а некоторые – положительными. Если входы отрицательные, то сумма уменьшается, т. е. они оказывают тормозящее действие, если положительные – возбуждающее. (?)
Каждый математический нейрон имеет собственное значение порога θ.
Обычно математический нейрон обозначается так:

θ = 0
Возбуждающие входы:


Тормозящие входы:
Множества нейронов объединяются в цепь:

Приведем примеры частных случаев математических нейронов.
Нейрон для реализации математических функций И и ИЛИ.
И
![]()
Если, θ = 2 → функция И, если θ = 1 → функция ИЛИ.
S = x1*1 + x2*1 = x1+ x2
|
x1+ x2 |
x1 |
x2 |
yθ=2 |
yθ=1 |
|
0 |
0 |
0 |
0 |
0 |
|
1 |
0 |
1 |
0 |
1 |
|
1 |
1 |
0 |
0 |
1 |
|
2 |
1 |
1 |
1 |
1 |
Персептрон Розенблата. Правила Хебба.
Персептрон может использоваться для построения логических и цифровых вычислений.
В 57 г. предположена МакКаллоком и Питтсом. Модель была подтверждена Френком Розенблатом. Затем было создано электронное устройство, моделирующее человеческий глаз. Розенблат назвал это устройство персептроном. Оно позволяло распознавать буквы латинского алфавита. Простейший вариант реализации персептрона для классификации цифр на четные и нечетные.
Модель материального нейрона: 12 фотоэлементов
x1
= 0
x2
= 1
x12
= 0
На эту матрицу накладывается карточка
с изображением цифры 4. Если на фотоэлемент
попадает какой-либо фрагмент цифры.


w1
w2
wj
.
.
.
.
.


|
|
|
|
|
|
|
xj
= 0 |
|
|
|
. . . . . |
|
|
|
x11
= 1 |














w11
w12
y

Алгоритм, обеспечивающий обучение персептрона:
Шаг1.
Случайным образом всем весовым
коэффициентам ωij
и пороговым значениям нейрона ![]() i
присваиваются некоторые малые значения.
i
присваиваются некоторые малые значения.
Шаг2. Персептрону предъявляется какая – либо цифра. Система фотоэлементов (их 12) вырабатывается входной вектор xj (j = 1,…,12).
Шаг3.
Каждый нейрон выполняет взвешенное
суммирование входных сигналов
 и вырабатывает сигнал yi
= 1, если Si
≥
и вырабатывает сигнал yi
= 1, если Si
≥
![]() i,
либо yi
= 0, если
Si
<
i,
либо yi
= 0, если
Si
< ![]() i.
i.
Шаг4. Для каждого нейрона вычисляется ошибка ξ = (di - yi).
di – вектор правильных ответов персептрона. Например, для «А» d1 = 1, d2 = 0, … , d33 = 0, для «В» d1 = 0, d2 = 1, d3 = 0, … , d33 = 0.
Шаг5. Производится корректировка весовых коэффициентов персептрона и пороговых значений нейрона.
![]() ij(t+1)
=
ij(t+1)
= ![]() ij(t)
+ ∆
ij(t)
+ ∆![]() ij
; ∆
ij
; ∆![]() ij
= η*
ξ i*xj
;
ij
= η*
ξ i*xj
;
i(t+1) = θi(t) + ∆θi ; ∆θi = - η* ξ i ;
t – номер итерации (эпохи) обучения.
Шаг6. Повторить шаги 2-5 необходимое число раз.
Адалайн, Мадалайн и обобщенное δ – правило
Использование персептрона не ограничивается только этой областью. Всё зависит от фантазии и умения использовать входной и выходной вектор разработчиками таких нейронных моделей. Например, при прогнозировании, медицине и т. д.
Факторы ![]() – симптомы болезни,
– симптомы болезни, ![]() – назначение лечащего врача.
– назначение лечащего врача.
|
x1 - кашель |
0 |
y1 - кашель |
1 |
|
x2 – высокая температура |
1 |
y2 - кашель |
1 |
|
x3 - насморк |
1 |
y3 - эритромицин |
0 |
|
… |
… |
… |
… |
|
xn |
1 |
yn |
0 |
2N – возможных сочетаний симптомов.
|
|
|
|
|
|
|
|
|
|
|
|
|
… |
… |
|
|
|
|
|
|
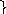


Для обучения персептрона
Тестовая таблица для нахождения ошибки
(ξ) обученности персептрона
Такие векторы, которых не было ранее
Дальнейшее усовершенствование модели персептрона связано с:
Изменением функции активации
Усовершенствованием (уточнением)
Усовершенствованием алгоритмов обучения
В частности, например, зачастую в качестве функции активации используют сигмоидную (логистическую) функцию.

![]()

![]()
-1
![]() ;
;![]() ;
;
![]()
Персептрон с сигмоидными активационными функциями (АФ), с одним выходом назвали Адалайн (от англ. ADAptive LInear NEuron), если же входов несколько, тогда MAny LInear NEuron, соответственно Мадалайн.
Замечание: помимо сигмоидных АФ, также используют линейные (без ограничений, например y = α*S, α – для наклона).
Например, 

-1
В последнее время используются радикально – базисные АФ:

![]()


Зачастую в качестве ошибки используют среднеквадратичную ошибку и ставят целью работы персептрона минимизацию среднеквадратичной ошибки.
В этом случае, рассмотренное нами ранее δ – правило, сводится к обобщенному δ – правилу, которое заключается в следующем: мы изменяем на последующем шаге по следующей формуле:
∆
![]() i
= η*δi*xi ξi
=
i
= η*δi*xi ξi
= ![]()
δi
= ![]()
Аналогично изменяется и пороговое значение нейрона.
Ограниченные возможности однослойного персептрона.
Существуют случаи, когда синоптические веса ωi невозможно подобрать никоим образом, т. е. однослойный персептрон не способен решить определенный круг задач. Такие задачи получили название линейно неразделимых.
Началось все с простейшей задачи – реализации на однослойном персептроне функции исключающее ИЛИ.
Исключающее ИЛИ – булева функция двух аргументов, которая принимает «истина», когда только аргумент имеет значение «истина».
|
|
|
|
Точки на плоскости |
|
0 |
0 |
0 |
A1 |
|
0 |
1 |
1 |
B2 |
|
1 |
0 |
1 |
B1 |
|
1 |
1 |
0 |
A2 |
![]()
О
X1 бозначим
на плоскости,
бозначим
на плоскости, ![]() ,
,
![]() и все точки, сочетающие наши входные
параметры.
и все точки, сочетающие наши входные
параметры.
Функция S для этого нейрона:
![]()
![]()
Уравнение пороговой прямой:
![]()
Для трех переменных существует уравнение пороговой плоскости, для четырех переменных – гиперплоскости.
Итак, если вместо
S
подставить ![]() ,
то это уравнение будет давать нам прямую
на плоскости, выше которой принимаются
значения, а ниже значения АФ не вычисляются.
,
то это уравнение будет давать нам прямую
на плоскости, выше которой принимаются
значения, а ниже значения АФ не вычисляются.
На приведенной плоскости надо подобрать такую прямую, которая разделила бы точки Ai, и точки Bi на две части.
С графической интерпретации видно, что такую прямую подобрать невозможно, а значит задача неразрешима. Невозможно подобрать такие коэффициенты, чтобы прямая разделила бы плоскость в указанном смысле (А и В).
Графическая интерпретация работы персептрона достаточно часто позволяет решить задачи.
Решение линейно неразделимых длилось около 20 лет и связано с разработкой персептрона.
Многослойный персептрон
![]()

ω = - 0,5
ω = - 0,5
![]()
Рассмотрим нейрон N1:
![]()
![]()
Рассмотрим нейрон N2:
![]()
![]()
Рассмотрим нейрон N3:
![]()
![]()
Пример:
Возьмем θ = 0,5
|
|
|
|
|
|
|
|
|
|
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
0 |
1 |
- 0,5 |
0,5 |
0 |
1 |
1 |
1 |
1 |
|
1 |
0 |
0,5 |
- 0,5 |
1 |
0 |
1 |
1 |
1 |
|
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
Задача, похожая на эту была обобщена и решена без обучения построить нейронную сеть, моделирующую любые булевы функции(Мкртчан).
Для многослойных персептронов алгоритмы обучения на основе δ – правил не подходят, потому что фактически эти алгоритмы корректируют синоптические веса только выходного слоя, а внутренних слоев не осуществляется.
В 70-80х гг. – велись исследования в области обучения многослойных персептронов. Наиболее эффективным алгоритмом в этой области стал алгоритм обратного распространения ошибки (back propagation). (86 г. – Румильхарт, Хилтон, Вильямс).
Алгоритм обратного распространения ошибки
Рассмотрим идею:
Пусть имеется двухслойный персептрон с N – входами и I – выходами и J – нейронов скрытого (внутреннего) слоя.
О
k
= 0 k
= 1 k
= 2 k
= K
. . .
![]()
![]()
![]() = 0
= 0
. . . . . . . . . . . . . . .![]()



![]()
![]()




























![]()

![]()


Алгоритм корректировки синоптических весов нейронов выходного слоя оставим таким же, как и для однослойного персептрона, т. е.:

![]()
![]()
![]()
Идея авторов алгоритма обратного распределения ошибок заключается в том, что в качестве ошибки использовалось суммирование ошибки с выходного слоя помноженные на силы соответствующих синоптических связей.

Тогда, если мы подставим это выражение для внутреннего слоя, мы получим следующие δ – правила:
![]()
![]() (???)
(???)
Кроме того, исследования показали, что к сумме, которую вычисляет нейрон, полезно добавить некоторое число, называемое смещением. Как правило, это некоторый порог, взятый с отрицательным знаком.
![]() ,при условии, что
,при условии, что ![]()
Алгоритм обратного распространения ошибки применим не только к двухслойному персептрону, но и к многослойному.
У нас имеется k – скрытых слоев. Также обозначим, что каждый k - ый слой содержит Нk – нейронов. Это означает, что персептрон имеет N = H0 входов и N = Hk выходов.
В алгоритме будем использовать следующие обозначения:
i – порядковый номер нейрона k – го слоя.
j – порядковый номер нейрона (k-1)-го слоя.
q - порядковый номер нейрона (k+1)-го слоя.
Алгоритм:
Шаг 1. Инициализация синоптических весов и смещений.
В циклах по: ![]() ;
;
![]() ;
;
![]() ;
синоптическим весам и смещениям
;
синоптическим весам и смещениям ![]() случайным образом присваиваются малые
величины в диапазоне [-1, 1].
случайным образом присваиваются малые
величины в диапазоне [-1, 1].
Шаг 2.
Представление из обучающей выборки
очередного входного вектора ![]() и соответствующего
и соответствующего ![]() ,
где q
– номер примера в обучающей выборке.
,
где q
– номер примера в обучающей выборке.
Шаг 3. Прямой проход.
В циклах по: ![]() и
и ![]() вычисляются выходные сигналы i-го
нейрона в k-ом
слое по формуле:
вычисляются выходные сигналы i-го
нейрона в k-ом
слое по формуле:
![]() ,
где
,
где ![]() ,
,
![]() ,
,
![]()
![]() – функция активации и выходные сигналы
персептрона
– функция активации и выходные сигналы
персептрона ![]() .
(???)
.
(???)
Шаг 4. Обратный проход.
В циклах по k, по i и по j вычисляются синоптические веса на новой эпохе:
![]() ,
где правило δ:
,
где правило δ:
![]() ,
причем для выходного слоя K:
,
причем для выходного слоя K:
![]() ,
а для всех других случаев:
,
а для всех других случаев: ![]()
Шаг 5. Повторение шагов 2 – 4 необходимое число раз.
Замечание: входные
векторы обучающих примеров ![]() и
и ![]() на втором этапе алгоритма обычно
представляются последовательно от 1-го
до последнего, где Q
– общее число примеров предметной
области (q
= 1,2,…,Q).
на втором этапе алгоритма обычно
представляются последовательно от 1-го
до последнего, где Q
– общее число примеров предметной
области (q
= 1,2,…,Q).
После того, как для каждого обучающего примера будут скорректированы все весовые коэффициенты персептрона, т. е. шаги 2 – 4 будут повторены Q раз, на 5-ом шаге также необходимо вычислить среднеквадратичную ошибку, усредненную по всем обучающим примерам.

Кроме того, для анализа эффективности обучения помимо ошибки ε можно рассчитать максимальную разность между желаемым и фактическим значениями выходов персептрона:
![]() , для
, для ![]() ;
;
![]() .
.
Тогда процесс итерационного обучения может быть окончен после того, как погрешность ε, достигнет желаемой величины, либо завершить процесс можно при соответствующей точности, либо при достижении предельного количества эпох обучения.
При проектировании многослойных персептронов очень остро встает задача о том, какое количество промежуточных слоев и элементов в них должно быть.
Для определения необходимого числа нейронов в скрытых слоях персептрона используется формула, являющаяся следствием теорем Арнольда – Колмогорова – Хехт – Нильсона:
![]()
где ![]() – необходимое число синоптических
весов,
– необходимое число синоптических
весов,
![]() – размерность выходного сигнала,
– размерность выходного сигнала,
![]() – размерность входного сигнала,
– размерность входного сигнала,
Q – число элементов обучающей выборки.
Например, для двухслойного персептрона может быть вычислено количество нейронов скрытого слоя.
![]()
Нечеткая логика в системах ИИ
При моделировании человеческих рассуждений очень часто приходится сталкиваться с нечеткой информацией (например: «большая скорость», «высокий человек», «дорогая вещь» и т.д.)
Для формализации такого рода понятий используется нечеткая логика.
Основы нечеткой логики положены в начале 60-х гг. – работа Латфи Заде «Fuzzy logic».
В основу нечеткой логики положены нечеткие множества.
Пример:
E – универсальное множество;
X є E – некий элемент множества;
R – некоторое свойство.
Тогда, обычное подмножество A универсального множества E, элементы которых удовлетворяют свойству R, определяется как множество упорядоченной пары A≤E, A={μA(x)|x}, где μA(x) – характеристическая функция, принимающее значение 1, если X удовлетворяет свойству R и 0, если X не удовлетворяет свойству R:
![]()
По аналогии определяется нечеткое множество. Нечеткое отличается от обычного тем, что характеристическая функция μA(x) попадает в зависимости от X в интервал [0;1]. В этом случае функция указывает степень принадлежности элемента к множеству A (или степень близости элемента к свойству R).
Пример:
Формализовать фразу «Он еще молодой»


|
μA(0) |
1 |
|
μA(10) |
1 |
|
μA(20) |
1 |
|
μA(25) |
0.9 |
|
μA(30) |
0.8 |
|
μA(35) |
0.7 |
|
μA(40) |
0.5 |
|
μA(50) |
0.1 |
|
μA(55) |
0 |
Основные характеристики нечетких множеств
Пусть ![]() ,
а A
– нечеткое множество с элементами из
универсального множества E,
тогда величина sup
μA(x)
(sup
– верхняя граница) называется высотой
нечеткого множества A.
,
а A
– нечеткое множество с элементами из
универсального множества E,
тогда величина sup
μA(x)
(sup
– верхняя граница) называется высотой
нечеткого множества A.
Если высота множества A равна 1, то множество называется нормальным, если < 1 – субнормальным.
Нечеткое множество
является пустым,
если ![]() .
.
Непустое субнормальное множество обычно нормализуют. При этом производится пересчет функции принадлежности:
![]()
Нечеткое множество
является унимодальным,
если ![]() лишь для одного
лишь для одного ![]() .
.
Носителем нечеткого
множества A
является обычное подмножество со
свойством ![]() .
.
![]()
Элементы X,
для которых ![]() называются точками
перехода
множества A.
называются точками
перехода
множества A.
Примеры задания нечетких множеств и их некоторые характеристики:
![]()
![]()
«Несколько» = 0,5|3 + 0,8|4 + 1|5 + 1|6 + 0,8|7 + 0,5|8.

1







Кол-во









1
2 3 4 5 6 7 8
![]()
![]()
Определяем численное задание «малой» с помощью функции принадлежности:
«малой» = ![]() – в некотором случае функции можно
задавать в виде формулы.
– в некотором случае функции можно
задавать в виде формулы.
3) «молодой»=
4) E = {Запорожец, Жигули, ГАЗ, Fiat, Nissan, Mersedes …}
Определим переменную «стоимость» с 3-х позиций:
1) недорогие;
2) средней стоимости;
3) дорогие
1
μ
стоимость x
дорогие
недорогие
средней стоимости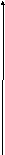




Основные методы построения функции принадлежности
1) экспертные;
2) эмпирическая (эвристическая) функция;
3) экспертный метод с помощью полярных значений;
4) косвенные определения (например, с помощью парных сравнений).
В этом случае каждая характеристика имеет 2 значения.
Пример:
Распознавание лица (полярный метод):
|
|
высота лба |
низкий |
высокий |
|
|
профиль носа |
курносый |
горбатый |
|
|
длина носа |
короткий |
длинный |
|
|
разрез глаз |
узкий |
широкий |
|
|
цвет глаз |
светлый |
темный |
|
|
форма подбородка |
острый |
квадратный |
|
|
толщина губ |
тонкие |
толстые |
|
|
цвет лица |
темный |
светлый |
|
|
овал лица |
овальное |
квадратное |
Метод парного сравнения заключается в следующем: определенные свойства выдаются в паре на предмет их сравнения по какому-то критерию («больше», «выше», «сильнее» …)
Матрица:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Операции над нечеткими множествами
Содержание.
![]() ,
если
,
если ![]()
![]()
![]() -
функция принадлежности на множестве
A.
-
функция принадлежности на множестве
A.
Иногда используют термин – доминирование. В данном случае B доминирует над A.
A




 = B || || || =
||
= B || || || =
||
(???)
Дополнение.
![]()
Пусть M
= [0, 1] A
и B(???)
![]()
Пересечение.
![]()
![]()
В результате пересечения получается наиболее нечеткое подмножество, которое содержится одновременно в A и B. При этом степень принадлежности нового элемента будет равна минимуму.
Объединение.
Наименьшее нечеткое подмножество, которое включает как A, так и B с новой функцией принадлежности.
![]()
![]()
Разность.
![]()
Соответственно:
![]()
Дизъюнктивная сумма.
![]()
![]()
Пример:
![]()
![]()
![]()
![]() (A
содержится в B
или B
доминирует над A).
(A
содержится в B
или B
доминирует над A).
![]()
![]()
![]()
![]()
![]()
![]()
Задание:
![]()
![]() =
=![]()
![]() =
=![]()
![]()
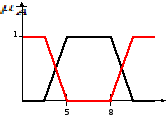
Обозначим нечеткое множество A – интервал где-то между 5 и 8, а для B – где-то около 4.


![]()
![]()

5 8


Свойства операций:
1) коммутативность
2) ассоциативность
3) идемпотентность
(A![]() A=A,
A
A=A,
A![]() A=A)
– отсутствие степеней и коэффициентов
A=A)
– отсутствие степеней и коэффициентов
4) дистрибутивность (асимметричная)
A![]() (B
(B![]() C)
= (A
C)
= (A![]() B)
B)![]() (A
(A![]() C)
C)
A![]() (B
(B![]() C)
= (A
C)
= (A![]() B)
B)![]() (A
(A![]() C)
C)
A![]() A
= A
A
= A
A![]() A
= A
A
= A
A![]() E
= E (E – универсальное
множество)
E
= E (E – универсальное
множество)
A![]() E
= E
E
= E
Законы де Моргана:
![]()
![]()
![]() - отличие нечетких множеств в отличие
от четких
- отличие нечетких множеств в отличие
от четких
CON(A) – операция концентрирования
CON(A) = A2
DIL = A0,5 – операция размывания

![]()
Нечеткие и лингвистические переменные
Нечеткая переменная характеризуется тройкой значений <α, X, A>, где α – имя переменной, X – универсальное множество (область определения α), A – нечеткое множество на X, описывающее ограничение, т.е. степень принадлежности μA(x) на значении нечеткой переменной α.
Лингвистическая переменная – это пятерка значений <β, T, X, G, M>, где
β – имя лингвистической переменной;
T – множество значений (терм множества), представляющий имена нечетких переменных, областью определения которых является множество X, множество T называется базовым терм-множеством лингвистической переменной;
G – синтаксическая процедура, позволяющая оперировать элементами терм-множества T, в частности, генерировать новые термы (значения);
G(T) – обычно обозначает множество сгенерированных термов;
T![]() G(T)
– расширенное терм-множество
лингвистической переменной;
G(T)
– расширенное терм-множество
лингвистической переменной;
M – семантическая процедура, позволяющая преобразовывать новое значение лингвистической переменной, образованное процедурой G в нечеткую переменную, т.е. сформировать соответствующее нечеткое множество.
Часть символов β используется как для названия переменной, так и для всех его значений.
Для обозначения нечеткого множества и его названия используется один символ, например,терм «молодой» является значением лингвистической переменной β = «возраст» и одновременно нечетким множеством M («молодой»).
Пример
Пусть эксперт определяет толщину некоторого изделия с помощью понятий: маленькая толщина, большая толщина, средняя толщина.
При этом точно известно, что диапазон: 10-80 мм.
Тогда формализация может быть задана с помощью лингвистической переменной <β, T, X, G, M>, где β – толщина изделия, T - множество термов T = {“AT”, “CT”, “ET”}
X = [10,80]
G – процедура формирования новых понятий с помощью логических операторов «И», «ИЛИ», а также с помощью модификаторов типа «НЕ», «ОЧЕНЬ», «СЛЕГКА» и др. Например: «очень маленькая толщина»
M
– процедура задания на множестве X
нечетких подмножеств A1 = «маленькая
толщина», A2 = «средняя толщина», A3 =
«большая толщина», а также нечетких
множеств на основе термов из G(T)
соответственно правилам трансляции
нечетких связок и модификаторов ИЛИ,
И, НЕ, ОЧЕНЬ, СЛЕГКА. И кроме того, M
определяет операции нечетких множеств
вида: ![]() ,
,
![]() ,
,![]() ,
CON
A
= A2,
DIL A =
A0,5.
,
CON
A
= A2,
DIL A =
A0,5.
Замечание:
Вместе с рассмотренными выше базовыми значениями лингвистической переменной «толщина», существует значении, зависящее от области определения X. Например, они могут быть определены, как «около 20 мм», «около 70 мм», и т.д., т.е. в виде нечетких чисел.
В качестве иллюстрации зададим степени принадлежности:


- маленькая или средняя толщина
Нечеткие высказывания. Нечеткие модели систем
Нечеткими высказываниями будем называть высказывания следующего вида:
Высказывания в виде <β есть β’ >, где β – имя лингвистической переменной, а β’ – её значение, которому соответствует нечеткое множество на универсальном множестве X.
Например, «давление большое». Предполагается, что лингвистической переменной «давление» предоставляется значение «большой» и при этом на универсальном множестве X переменной «давление» определено нечеткое множество значению «большой».
Высказывания в виде <β есть mβ’ >, где m – модификатор, которому соответствуют слова вида: «типа», «очень», «более», «около», «менее» и т. д.
Сложные высказывания, образованные из высказываний вида 1), и 2), и союзов: и, или, иначе, если, тогда и т. д.
Если значение
фиксированной лингвистической переменной
соответствует нечетким множествам
одного универсального множества X,
можно отождествлять модификаторы
«очень» и «не» («нет») с операциями
концентрирования (CON
A)
и дополнения (![]() ),
кроме того, союзы И
и ИЛИ
с операциями
),
кроме того, союзы И
и ИЛИ
с операциями
![]() над нечеткими множествами.
над нечеткими множествами.
Пример:
Высказывание «толщина изделия очень маленькая» может быть записано в виде CON(A)=A’
«толщина изделия не большая или средняя» (де Морган):
![]() .
.
«толщина изделия не маленькая и не большая»:
![]() .
.
Использование нечетких множеств в интеллектуальных системах управления
Во многих современных технических устройствах в настоящее время имеются так называемые контроллеры (модули) нечеткой логики, которые совершенствуют работу управляемого или других устройств. Функционирование таких контроллеров отличается от работы обычных контроллеров.
В обычных контроллерах, как правило, заложена математика.
В интеллектуальных контроллерах вместо математики и т. д. используются знания экспертов. Эти знания могут быть выражены с помощью лингвистических переменных, которые описаны нечеткими множествами.
Общую структуру
таких контроллеров можно представить
в следующем виде:
четкий управляющий сигнал
Блок фазификации (от анлг. fazi)- преобразует четкие величины, измеренные (полученные) в объекте управления, в нечеткие величины, которые описаны лингвистическими переменными в базе знаний.
Блок решений, как правило, используют условные правила (правила импликации if…then), которые заложены в базу знаний для преобразования нечетких входных данных в необходимые управляющие влияния, которые также носят нечеткий характер.
Блок фазификации превращает нечеткий управляющий сигнал в четкую величину, которую используют для управления объекта.
Таким образом, все системы с нечеткой логикой функционируют по следующему принципу:
1) снимаются четкие данные с измеренных приборов и датчиков объекта управления;
2) эти данные фазифицируются, т. е. преобразуются в нечеткий формат;
3) в нечетком формате на основе базы знаний и правил данные обрабатываются и получаются обработанные решения (пока в нечетком виде);
4) управляемыеие решения дефазифицируются и подаются в виде управляющих сигналов на испытательные устройства.
Пример:
Рассмотрим случай управления мобильным роботом, задачей которого является объезд препятствий.
Введем 2 лингвистические переменные: «дистанция» - расстояние от робота до препятствия и «направление» - угол между продольной осью робота и направлением к препятствию.
Рассмотрим более подробно лингвистическую переменную «дистанция». Опредилим значения этой переменной терминами: «далеко», «средне», «близко», «очень близко».
Предположим, что
«дистанция» может принимать любые
значения от 0 до ![]() .
Наша задача задать функции степени
принадлежности для каждого из этих
термов.
.
Наша задача задать функции степени
принадлежности для каждого из этих
термов.

Переменная «направление» от 0 до 360 градусов – диапазон, а термы: «левый», «прямой», «правый». Задаем управляющую лингвистическую переменную: «рулевой угол». И определяем следующие термы: «резко вправо», «влево», «прямо», «вправо», «резко вправо».
Следующий шаг: задаем правила вида: если Д = Зн и Напр = Зн, то РУ = Зн.
Когда имеется 2 входа, обычно задают таблицу:
|
Направление |
Дистанция |
||||
|
|
очень близко |
близко |
средне |
далеко |
|
|
правый |
резко влево |
резко влево |
влево |
прямо |
|
|
прямой |
резко влево |
влево |
влево |
прямо |
|
|
левый |
резко вправо |
резко вправо |
вправо |
прямо |
|
Турбо-Пролог - это осуществленная компанией Borland International реализация языка программирования высокого уровня Пролог компиляторного типа. Ее отличает большая скорость компиляции и счета. Турбо-Пролог предназначен для выдачи ответов, которые он логически выводит при посредстве своих мощных внутренних процедур.
Турбо-Пролог - это декларативный язык, программы на котором содержат объявления логических взаимосвязей, необходимых для решения задачи.В Турбо_Прологе рассматриваются отношения между утверждениями и объектами, характерные для логики предикатов. В программах на Прологе существует три типа предложений (clauses): факт, правило вывода, цель.Каждое предложение должно заканчиваться точкой. Факт - утверждение, истинность которого безусловна.Например, likes(mary,apples). /* Мэри любит яблоки */ или male(bob) /* Боб - мужчина */ parent(bob,ann). /* Боб - родитель Энн */ Правило - утверждение, зависящее от условий.Например, child(ann,bob) :- parent(bob,ann). /* Энн - дитя Боба, если Боб - родитель Энн */ или father(X,Y) :-parent(X,Y),male(X )./* Для всех X и Y X является отцом Y,если X является родителем Y и X - мужчина */ Цель - вопрос пользователя к системе о том, какие утверждения являются истинными. Для указанных выше примеров на вопрос child(ann,bob) /* является ли Энн ребенком Боба ?*/ будет выдан ответ true /* истина */, а на вопрос father(X,ann) /* кто является отцом Энн ? */ будет выдан ответ X = Bob /* отцом Энн является Боб */. На все поставленные вопросы Пролог пытается ответить с помощью фактов и правил вывода. Он решает задачу, просматривая программу сверху вниз и слева направо. Сначала анализируется цель и ведется поиск такого факта или правила вывода, с помощью которого она может быть достигнута. При нахождении такого факта после соответствующей подстановки переменных Пролог переходит к анализу следующей цели при условии, что предыдущая достигнута (доказана). Если некоторая цель последняя, доказательство заканчивается. При отсутствии нужных фактов, но наличии правила вывода, которое могло быть применено, цель заменяется условием этого правила с соответствующей подстановкой переменных. Теперь условием выполнения цели становится доказательство условия (правой части) правила вывода. Процесс нахождения соответствия между целью и фактом или правилом называется у н и ф и к а ц и е й. В ходе унификации Пролог ищет все альтернативные решения. Программа Турбо-Пролога включает определенные разделы, не все из которых являются обязательными: domains /*(домены) - раздел объявлений*/; database /* описания предикатов динамической базы данных */ predicates /* описания предикатов */ goal /* целевое утверждение */ clauses /* утверждения - факты и правила */ В программе по крайней мере должны быть разделы predicates и clauses. Раздел domains напоминает объявление данных в традиционных (императивных) языках, например таких, как Паскаль и Си. Существуют следующие типы доменов: char (символьный), integer (целый), real (вещественный), string (строковый), symbol (для цепочки из букв, цифр и символов подчеркивания с первой строчной буквой либо цепочки знаков в двойных кавычках), file (файловый). По отношению к именам объектов ( идентификаторам ) в Прологе используются следующие правила : 1) имя может включать латинские буквы, цифры и символ подчеркивания, причем первым символом не должна быть цифра; 2) имена символических констант должны начинаться со строчной буквы; 3) в имени можно использовать одновременно и строчные и прописные буквы. Рассмотрим примеры программ на языке Турбо-Пролог. Пример 1. Родственные отношения domains s=symbol /* объект s имеет тип symbol */ predicates parent(s,s) female(s) male(s) mother(s,s) father(s,s) ancestor(s,s) child(s,s) clauses parent(pam,bob). /* Пам - родитель Боба */ parent(tom,bob). parent(tom,liz). parent(bob,ann). parent(bob,pat). parent(pat,jim). female(pam). /* Пам - женщина */ female(liz). female(ann). female(pat). male(tom). /* Том - мужчина */ male(bob). male(jim). child(Y,X):- /* Y - отпрыск X, если X - родитель Y */ parent(X,Y). mother(X,Y):- /* X - мать Y, если */ parent(X,Y),female(X). /* X - родитель Y и X - женщина */ father(X,Y):- /* X - отец Y, если */ parent(X,Y),male(X). /* X - родитель Y и X - мужчина */ ancestor(X,Z):- /* X - предок Z, если */ parent(X,Z). /* X - родитель Z */ ancestor(X,Z):- /* X - предок Z, если */ parent(X,Y),ancestor(Y,Z). /* X - родитель Y и Y - предок Z */
3. ВВОД И ВЫВОД В ТУРБО-ПРОЛОГЕ 3.1. Взаимодействие с файлами Ввод и вывод в Прологе организуется с помощью специальных предикатов чтения и записи, которые могут рассматриваться как аналоги соответствующих подпрограмм в языках Паскаль и Си. В общем случае пролог- программа взаимодействует с несколькими файлами ( в том числе с "псевдофайлом" keyboard (клавиатура) и "псевдофайлом" screen (экран)). Она считывает данные из нескольких входных файлов, называемых входными потоками, и выводит данные в несколько выходных файлов, называемых выходными потоками. В каждый момент выполнения программы лишь два файла являются "активными": один для ввода, другой для вывода. В начальный момент эти два потока соответствуют терминалу. Текущий входной поток может быть заменен на другой файл name_of_file посредством цели readdevice(name_of_file). Такая цель всегда успешна (если только с файлом name_of_file все в порядке), а в качестве побочного эффекта происходит переключение ввода с предыдущего входного потока на файл name_of_file. Пример 1. Использование предиката readdevice. Приведенная ниже последовательность целей считывает информацию из файла myfile, а затем переключает ввод обратно на терминал. ... openread(myfile,"myfile.txt"), /* файл myfile открывается для чтения */ readdevice(myfile), /* стандартный входной поток связывается с файлом myfile */ filepos(myfile,X,0), /* текущий указатель устанавливается на позицию X, которая отсчитывается от начала файла myfile */ readchar(Y), /* из позиции X читается символ и назначается переменной Y */ readdevice(keyboard), /* стандартный входной поток связывается с клавиатурой */ ... Текущий выходной поток может быть изменен при помощи цели вида writedevice(name_of_file). Следующая последовательность целей выводит значение переменной X в файл outfile.txt и после этого перенаправляет последующий вывод обратно на терминал. Пример 2. ... openwrite(outfile,"outfile.txt"), /* файл outfile открывается для записи */ writedevice(outfile), /* стандартный выходной поток связывается с файлом outfile */ write(X), closefile(outfile), /* закрытие файла outfile */ writedevice(screen), /* стандартный выходной поток связывается с экраном дисплея */ ... Кроме вышеупомянутых используются следующие стандартные предикаты работы с файлами: 1) openappend( логическое имя файла, физическое имя файла) - подобен openread, но файл открывается для дополнения; 2) openmodify( логическое имя файла, физическое имя файла) - подобен openread, но файл открывается для модификации (чтения и записи); 3) filepos( логическое имя файла,позиция,режим) - устанавливает текущий указатель на заданную позицию в указанном файле. Объект, указывающий на позицию, должен быть вещественного типа (real), а режим - целого типа ( integer ). Если режим равен 0, то позиция отсчитывается от начала файла; если 1, то - от текущего значения указателя; если 2, то - от конца файла. Этот предикат используется для прямого доступа к файлу. 4) readchar(Var) - считывает символ с входного потока ( по умолчанию с клавиатуры) и присваивает его переменной Var; 5) readint(Var) - считывает целое число и присваивает его переменной Var; 6) readln(Var) - считывает символы с входного потока до нажатия клавиши Enter. Введенные символы присваиваются переменной Var, которая должна быть строковой (string) или символьной (symbol). 7) readreal(Var) - считывает вещественное число; 8) write( Arg1, Arg2, ... ) - выводит значения аргументов на текущее устройство (по умолчанию, на экран дисплея). Аргументы Arg1, Arg2, ... могут быть константами или переменными, которым заранее присвоены требуемые значения. 9) nl - вызывает перевод каретки в начало следующей строки. В предикате write можно использовать символы, начинающиеся со знака \. Они имеют специальные значения: \k - символы, имеющие ASCII код числа k; \n - возврат каретки и перевод строки; \t - табуляция. Файлы могут обрабатываться только последовательно. Каждый запрос на чтение из входного файла приводит к чтению в текущей позиции текущего входного потока. После этого текущая позиция будет перемещена на следующий, еще не прочитанный элемент данных. Следующий запрос на чтение приведет к считыванию, начиная с этой новой текущей позиции. Запись производится точно так же: каждый запрос на вывод информации приведет к тому, что она будет присоединена к концу текущего выходного потока. Пример 3. Запись символов в файл myfile.f, который создается на текущем диске. domains file=myfile /* объявляется логическое имя файла myfile */ predicates read_in_loop goal openwrite(myfile,"myfile.f"), writedevice(myfile), not(read_in_loop), closefile(myfile), writedevice(screen), write("\n запись в файл myfile.f произведена \n "). clauses read_in_loop:- readchar(X), X<>'#',!, write(X), read_in_loop. Пример 4. Чтение символа из файла и вывод его на экран дисплея. domains file=infile predicates position goal write(" С каким файлом Вы хотите работать ? \n "), readln(Fname), openread(infile,Fname), position. clauses position:- readdevice(keyboard), nl,write("Введите номер позиции: "), readreal(X), readdevice(infile), filepos(infile,X,0), readchar(Y), write(" Здесь записан символ:",Y), position. 3.2. Форматный вывод writef writef(Format,Arg1,...,Argn) - подобен write, но осуществляет форматированный вывод в соответствии с параметром Format, который представляется в виде %p Возможные значения p : d - нормальное десятичное число ( символы и целые числа); u - беззнаковое целое; s - строка (атомы или строки); c - символ (символы и целые); g - вещественное в самом коротком формате; e - вещественное в экспоненциальном представлении; f - вещественное в десятичном представлении ( задается по умолчанию); x - шестнадцатиричное число (символы и целые числа). 3.3. Ввод и вывод чисел и символов Пример 5.Вычисление куба числа, вводимого с терминала. domains i=integer predicates process(i) cube clauses cube:- write("Next number,please:"), readint(X), process(X). process(N):- C=N*N*N, write("Cube",N,"is equal",C,"\n"), cube. goal cube. Пример 6. Считывание целых чисел с терминала и занесение их в список domains list=integer* predicates readlist(list) goal readlist(TheList),write("\n The list is: ", TheList). clauses readlist([H|T]):-readint(H),!,readlist(T). readlist([]). После набора каждого целого числа нужно нажать ENTER. Завершение программы происходит по любому символу, который не является целым числом, плюс ENTER. Пример 7. Вывод списков domains i_list=integer* n_list=symbol* predicates writelist(i_list) writelist(n_list) clauses writelist([]). writelist([H|T]):- write(H," "),writelist(T). 3.4. Обработка строк Стандартные предикаты обработки строк в Турбо-Прологе: 1. concat(Str1,Str2,Str1_2) - утверждает, что Str1_2 - это объединение строк Str1 и Str2; при этом по крайней мере два параметра должны быть определены заранее. 2. frontchar(Str1_2,Char,Str2) - работает в соответствии с уравнением: Str1_2 = Char U Str2 3. frontstr(Length,InpString,StartString,RestString) - назначает первые Length символов строки InpString в строку StartString, остальные - в строку RestString. 4. fronttoken(String,Token,RestString) String - входная строка; Token - первый атом строки (последовательность символов до пробела); RestString - остаток строки. 5. str_len(String,Length) - определяет длину строки. Пример 8. Преобразование строки в список символов. domains charlist=char* predicates name(string,charlist) clauses name(" ",[]). name(S,[H|T]):-frontchar(S,H,S1), name(S1,T). Пример 9. Преобразование строки в список атомов. domains namelist=name* name=symbol predicates string_namelist(string,namelist) clauses string_namelist(S,[H|T]):-fronttoken(S,H,S1),!,string_namelist(S1,T). string_namelist(_,[]). 3.5. Встроенный предикат findall Встроенный предикат findall(X,P,L) порождает список L всех объектов X, удовлетворяющих цели P. Пример 10. Вычисление среднего возраста domains name, address = string age = integer list = age* predicates person(name, address, age) sumlist(list, age, integer) goal findall(Age, person(_, _, Age), L), sumlist(L, Sum, N), Ave = Sum/N, write("Average =", Ave), nl. clauses sumlist([], 0, 0). sumlist([H|T], Sum, N) :- sumlist(T, S1, N1), Sum=H+S1, N=1+N1. person("Sherlock Holmes", "22B Baker Street", 42). person("Pete Spiers", "Apt. 22, 21st Street", 36). person("Mary Darrow", "Suite 2, Omega Home", 51).
2.1. Представление списков Список - последовательность из произвольного числа элементов. Список является основной структурой данных в Прологе. Элементы списка разделяются запятыми и заключаются в квадратные скобки. Любой список представляет собой: - либо пустой список (атом []); - либо непустой список - структуру, состоящую из двух частей: - первый элемент - голова (Head) списка; - второй элемент - хвост (Tail) списка. В общем случае голова списка может быть любым объектом языка Пролог, а хвост - обязательно должен быть списком. Поскольку хвост - список, то он либо пуст, либо имеет свои собственные голову и хвост. Для повышения наглядности программ в Прологе предусматриваются специальные средства для списковой нотации, позволяющие представлять списки в виде [ Элемент1, Элемент2,...] или [ Голова | Хвост ] или [ Элемент1, Элемент2,... | Остальные]. Здесь знак | используется для отделения начала списка от конца. 2.2. Операции над списками 2.2.1.Принадлежность к списку (member) Отношение принадлежности записывается в виде двух предложений: member(X,[X|Tail]). member(X,[_|Tail]) :- member(X,Tail). Оно основано на следующих соображениях: либо X - голова списка, либо X принадлежит хвосту этого списка. 2.2.2.Сцепление (конкатенация) списков (conc) Обозначается через conc(L1,L2,L3). Здесь L1 и L2 - два списка, L3 - список, получаемый при их сцеплении. Определение отношения conc содержит два случая: - если первый аргумент - пуст, то второй и третий аргументы представляют собой один и тот же список: conc([],L,L). - если первый аргумент отношения conc не пуст, то он имеет голову и хвост - [X|L1]. Результат сцепления - список [X|L3], где L3 - получен после сцепления списков L1 и L2: conc([X|L1],L2,[X|L3]) :- conc(L1,L2,L3). Примеры сцепления заданных списков. Goal: conc([a,b,c],[x,y,z],L). L = [a,b,c,x,y,z] Goal: conc([a,[b,c],d],[a,[],b],L). L = [a,[b,c],d,a,[],b] Программу для conc можно применить "в обратном направлении" - для разбиения списка на две части. Например: Goal: conc(L1,L2,[a,b,c]). L1=[] L2=[a,b,c] L1=[a] L2=[b,c] L1=[a,b] L2=[c] L1=[a,b,c] L2=[] Используя conc можно определить отношение принадлежности следующим эквивалентным способом: member(X,L) :- conc(_,[X|_],L). Здесь символом "_" обозначены анонимные переменные (переменные, встречающиеся в предложении только по одному разу). 2.2.3. Добавление элемента (append) Наиболее простой способ добавления элемента в список - вставить его в начало так, чтобы он стал его новой головой. Процедура добавления определяется в форме факта append(X,L,[X|L]). 2.2.4. Удаление элемента (remove) Имеем два случая: - если X - голова списка, то результат удаления - хвост списка; - если X - в хвосте списка, то его нужно удалить оттуда. В результате отношение remove определяется так: remove(X,[X|Tail],Tail). remove(X,[Y|Tail],[Y|Tail1]) :- remove(X,Tail,Tail1). Если в списке встречается несколько вхождений элемента X, то remove сможет исключить их все при помощи возвратов.
2.3. Арифметические действия Турбо-Пролог располагает двумя числовыми типами доменов: целыми и действительными числами. Четыре основные арифметические операции - это сложение, вычитание, умножение и деление. Для их реализации в Турбо-Прологе используются предикаты. Пример 1. Поиск нужного элемента в списке domains i=integer s=symbol i_list=i* /* определение типа "список целых чисел" */ s_list=s* /* определение типа "список атомов" */ predicates /* предикат member определяется над списками двух типов */ member(i,i_list) member(s,s_list) clauses member(Head,[Head|_]). member(Head,[_|Tail]):-member(Head,Tail). Пример 2. Определение суммы элементов списка domains i=integer i_list=i* predicates sum_list(i_list,i) clauses /* Если список пуст, то сумма его элементов равна нулю */ sum_list([],0). /* Иначе найти сумму элементов хвоста списка и прибавить к ним голову */ sum_list([H|T],Sum,Number):- sum_list(T,Sum1,Number1), Sum=H+Sum1. Пример 3. Реализация арифметики domains i=integer r=real predicates add(i,i,i) sub(i,i,i) mul(i,i,i) div(i,i,i) fadd(r,r,r) fsub(r,r,r) fmul(r,r,r) fdiv(r,r,r) clauses add(X,Y,Z) :- Z=X+Y. sub(X,Y,Z):- Z=X-Y. mul(X,Y,Z):- Z=X*Y. div(X,Y,Z):- Z=X/Y. fadd(X,Y,Z) :-Z=X+Y. fsub(X,Y,Z):- Z=X-Y. fmul(X,Y,Z):-Z=X*Y. fdiv(X,Y,Z):-Z=X/Y.