

Контрольные вопросы
1. Назначение и правила использования в Пролог - программе секции database.
2. Что такое стандартные (встроенные) предикаты? Перечислите предикаты работы с database.
3. Какой смысл имеют эти предикаты?
4. Расскажите принцип работы этих предикатов.
5. Как организовать цикл со счетчиком, используя базу данных?
6. Какие еще стандартные (встроенные) предикаты используются в данной работе? Объясните принцип их работы.
Лабораторная работа №4
Рекурсивные структуры данных - списки
Цель работы
Изучить основные принципы работы с универсальной рекурсивной структурой в логическом программировании, правостороннюю и левостороннюю рекурсию, алгоритм унификации.
Содержание работы
1. Прочитать методические указания к данной лабораторной работе.
2. Выполнить упражнения.
3. Выполнить индивидуальное задание.
4. Оформить отчет.
Содержание отчета
1. Тексты упражнений и анализ полученных результатов.
2. Текст индивидуального задания.
3. Текст программы с комментариями, определяющими декларативный смысл предложений.
4. Описание задач, решаемых данной программой.
5. Дерево поиска решений для одной из решаемых задач и показать на этом дереве механизм унификации термов.
Методические указания
Структуры данных в логическом программировании записываются как функторы:
f(x1,x2,…,xn),
где f - имя функтора, xi - элементы данных для i от 1 до n.
Список - это бинарная рекурсивная структура данных. Первый компонент структуры - это элемент, второй - остаток списка, таким образом, необходим функтор арности 2. В логическом программировании принято функтор для списков обозначать точкой " · ". При построении списков необходимo наличие константного символа, чтобы рекурсия не была бесконечной. Таким символом является "пустой список", который в Прологе обозначается [].
Правильная формальная запись списка:
· (a, []) - список из одного элемента;
· (а, · (с, · (в, []))) - список из трех элементов;
· (а, Х) - список, в котором выделен первый элемент;
· (а, · (b, Х)) - список с двумя выделенными первыми элементами.
Чтобы не перегружать программу обращением к символу " · ", используется специальная запись: терм · (Х,У) обозначается как [X|Y]. Компоненты терма имеют специальные названия: X - голова списка, Y - хвост списка.
Общепринятая запись вышеперечисленных списков:
[a| [ ] ] – или [ а ];
[ а | [ b | [ c | [ ] ] ] ] – или [a, b, c];
[ а | X ];
[ а | [ b | X] ] – или [ а , b | X ].
Описание списков в Турбо-Прологе
В Турбо-Прологе списки должны быть обязательно объявлены в разделе DOMAINS. Для этого необходимо ввести имя нового домена и определить домен, который описывает тип элементов, объединяемых в список (в качестве такого домена можно использовать стандартные домены).
Например:
domains
list_integer = integer* % вводится домен списка целых чисел %
list_s = symbol* % вводится домен списка символов %
list_list = list_s* % элементами этого списка должны быть списки
% символов
Списки не обязательно должны быть построены из однородных элементов, можно объединить элементы разных типов. Для этого необходимо ввести домен с альтернативными типами. Это делается так:
domains
mixtype = I(integer);
R(real);
S(symbol)
list_mix= mixtype* % это означает, что в список могут объединяться целые,
% вещественные, символьные элементы
Таким образом, общая схема описания списков:
domains
домен_список = домен_элементов*
Операции над списками
Основные предикаты обработки списков, которые могут использоваться при написании более сложных программ:
- принадлежность списку;
- объединение двух списков;
- выделение элемента из списка;
- удаление всех вхождении элемента из списка;
- сортировка элементов списка;
- определение длины списка и др.
Тексты этих процедур смотрите в книгах [1], [2].
Упражнение: проанализируйте работу одного из основных предикатов обработки списков, выполнив его в режиме трассировки. Какие задачи можно решать, используя данный предикат? Придумайте цели для решения каждой задачи и начертите деревья поиска решений.
При формировании списка из данных, содержащихся в виде фактов в базе данных или непосредственно в программе, полезным оказывается предикат findall. Он собирает значения, получаемые в процессе бектрекинга, в список. Формат предиката:
findall(Переменная, Предикат, Список),
где первый аргумент определяет параметр, который необходимо собрать в список, второй аргумент определяет предикат, из которого формируется список значений, третий аргумент - формируемый список.
Например, пусть имеется программа:
domains
list = symbol*
name = symbol
age = integer
predicates
men(name, age)
clauses
men(brain, 17).
men(maikl, 18).
men(bill, 18).
men(stiv, 16).
men(bob, 18).
Теперь, если необходимо сформировать список мужчин призывного возраста, то необходимо указать цель:
goal
findall(N, men(N, 18), L)
В результате получим список L=[maikl, brain, bob ].
Задания
1. Напишите программу, определяющую основные отношения на множествах:
а) ОБЪЕДИНЕНИЕ;
б) ПЕРЕСЕЧЕНИЕ;
в) ВЫЧИТАНИЕ;
г) ДЕКАРТОВО ПРОИЗВЕДЕНИЕ.
2. Написать программу, которая вставляет:
а) в список L новый элемент X перед всеми вхождениями элемента Y, если Y входит в L;
б) в непустой список L пару новых элементов X1 и Х2 перед его последним элементом;
в) в непустой список L, элементы которого упорядочены по возрастанию, новый элемент X так, чтобы сохранилась упорядоченность,
3. Написать программу, которая удаляет:
а) из списка L за каждым вхождением элемента X один элемент, если такой есть и он отличен от X;
б) из списка L один элемент, предшествующий элементу X, если такой есть и он отличен от X.
4. По кругу расположено N человек. Начиная с некоторой позиции, мы считаем по кругу и каждый М человек выбывает из круга, при этом круг смыкается. Напишите программу, которая определяет порядок, в котором люди выбывают из круга.
5. a) Определите отношение
ПЕРЕВОД (Список1, Список2)
для перевода списка чисел от 0 до 9 и список соответствующих слов. Например,
ПЕРЕВОД ([3, 5, 2, 3], [три, пять, два, три ] ).
Используйте следующее отношения:
ОЗНАЧАЕТ (0, нуль).
ОЗНАЧАЕТ (1, один).
ОЗНАЧАЕТ (2, два).
…
б) Напишите программу для отношения ДВОЙНОЙ_СПИСОК (Список1, Список2), в котором каждый элемент Списка1 удваивается и записывается в Список2, например, ДВОЙНОЙ_СПИСОК ( [1, 2, 3 ], [1 ,1 ,2 ,2 ,3 ,3 ] ).
6. a) Напишите программу для предиката
ПОДСТАНОВКА (X,Y, Список1, Список2),
где Список2 - результат подстановки Y вместо всех вхождений X в Список1. Например, отношение ПОДСТАНОВКА (а , х , [а, b, а, с], [х, b, х, с]) - истинно, а отношение ПОДСТАНОВКА (а, х, [а, в, а, с], [ а, в, х, с]) - ложно.
б) Напишите программу для отношения
Без_Повторений (Список1, Список2),
где Список2 - результат удаления всех повторных вхождений элементов в Список1, например, Без_Повторений ([а, в, с, в],[а, в, с]) - истинно.
7. Написать программу, которая:
а) переносит в конец непустого списка L его первый элемент;
б) переносит в начало непустого списка L его последний элемент;
в) проверяет, есть ли в списке L хотя бы два одинаковых элемента;
г) вставляет в список L за первым вхождением элемента X все элементы списка L1, если X входит в L;
д) в списке L из каждой группы подряд идущих равных элементов оставляет только один;
ж) подсчитывает число вхождений каждого элемента списка L и формирует новый список L1, в котором каждый элемент - это список, состоящий из элемента и числа его вхождений в список L.
Например, если L=[f, d, f, g, a, f, d ], то L1=[[f, 3], [d, 2], [g, 1], [a, 1] ].
8. а) Напишите программу для отношений
ЧЕТНАЯ_ПЕРЕСТАНОВКА(Список1,Список2)
и НЕЧЕТНАЯ_ПЕРЕСТАНОВКА (Список1, Список2),
где Список2 - это переставленный Список1 за четное или за нечетное число шагов. Например,
ЧЕТНАЯ_ПЕРЕСТАНОВКА ([1,2,3],[2,3,1])
НЕЧЕТНАЯ_ПЕРЕСТАНОВКА ([1,2,3],[2,1,3])
б) Определите два предиката
ЧЕТНАЯ_ДЛИНА (Список) и НЕЧЕТНАЯ_ДЛИНА (Список)
таким образом, чтобы они были истинными, если их аргументом является список четной или нечетной длины соответственно.
Контрольные вопросы
1. Дайте определения списка. Как он представляется в Прологе и в Турбо-Прологе в частности?
2. Какие абстрактные структуры данных можно моделировать с помощью списков?
3. Рекурсивные и итерационные алгоритмы обработки списков. Замена итерации рекурсией в Прологе. Преимущество итерационных алгоритмов перед рекурсивными алгоритмами.
4. Стандартные предикаты работы со списками.
5. Принцип работы алгоритма унификации. Какие основные операции обработки данных в процедурных языках включает в себя унификация?
Лабораторная работа №5
Рекурсивные структуры данных – деревья и графы
Цель работы
Изучение логических программ, задающих отношения над объектами рекурсивных типов и приобретение навыков самостоятельной разработки таких программ.
Содержание работы
1. Изучить теоретический материал [1, с.54-61], [2, с.112-118, с.278-305];
2. Исследовать работу одной из логических программ, задающих отношения над объектами рекурсивных типов, по указанию преподавателя (см. задания для исследования):
а) записать предложенную программу на Турбо-Прологе;
б) выполнить программу в пошаговом режиме и построить дерево вывода при ее работе;
в) модифицировать программу, вставляя в предложения программы предикат отсечения (!);
г) выполнить модифицированную программу в пошаговом режиме и построить дерево вывода;
д) сравнить деревья вывода в том и другом случаях и определить "цвет" отсечения;
3. Разработать и отладить программу решения индивидуального задания;
4. Продемонстрировать преподавателю работу составленных программ;
5. Оформить отчет по выполненной работе;
6. Защитить работу.
Содержание отчета
1. Результаты исследования: текст исследуемой программы, декларативный смысл этой программы, дерево вывода для одного из тестов, текст модифицированной программы, дерево вывода модифицированной программы, анализ использования предиката отсечения.
2. Текст индивидуального задания.
3. Текст программы и ее декларативный смысл.
4. Тесты и результаты тестирования.
Методические указания
1. ДЕРЕВЬЯ
Несмотря на то, что с помощью списков можно представить любую структуру данных, использование их не всегда эффективно. В некоторых случаях при разработке эффективных программ более подходящим типом данных являются различные древовидные структуры. В данной работе мы рассматриваем двоичные деревья.
Двоичное дерево либо пусто, либо состоит из корня, левого поддерева, правого поддерева. Корень может быть чем угодно, а поддеревья сами должны быть двоичными деревьями. На рис.1 показано представление арифметического выражения a+bc двоичным деревом.

рис.1.
Существует много способов представления двоичных деревьев на Прологе. Одна из простых возможностей - описывать каждую вершину дерева как соответствующий функтор, аргументами которого являются поддеревья. Тогда дерево рис.1 будет представлено так:
plus(a, mult(b, c))
В Turbo - Прологе данной структуре должно соответствовать следующее описание в области domains:
domains
exe = plus(exe, exe); mult(exe, exe); symbol
Обратите внимание, что рекурсивной структуре соответствует и рекурсивное описание. Данное описание позволяет построить дерево любой сложности (выражение любой сложности), которое включает только операции умножения и сложения. Для того чтобы задать традиционное выражение, необходимо изменить описание домена - ехе, введя в это описание новые функторы, соответствующие расширенному множеству операций.Такое представление среди прочих своих недостатков имеет то слабое место, что для каждой вершины дерева нужен свой функтор. Такое представление невозможно, если вершины сами являются структурными объектами.
Более универсальный способ представления двоичных деревьев состоит в том, чтобы определить функтор с тремя аргументами (корня и двух поддеревьев) и ввести символ для обозначения пустого дерева. Если пустое дерево представим атомом nil, а в качестве функтора примем tree (L, X, R), где X – корень древа, L – левое поддерево, R - правое поддерево, то дерево рис. 1 будет выглядеть следующим образом:
tree (+, tree ( a, nil, nil ), tree ( *, tree( b, nil, nil ), tree( c, nil, nil ) ) ).
Данной структуре будет соответствовать следующее описание:
domains
exe = tree (symbol, exe, exe); nil
Структура логической программы, обрабатывающей дерево, соответствует рекурсивной природе таких данных, как деревья, арифметические выражения и пр. Как правило, такая программа содержит предложение-факт для пустого дерева или факта свершившегося действия и одно или несколько рекурсивных предложений, обрабатывающих левое и правое поддеревья. Например, ниже приведена программа проверки принадлежности элемента бинарному дереву. Элемент является первым аргументом отношения tree_member, дерево – вторым.
tree_member(X, tree(X, Left, Right ) ). % факт, устанавливающий совпадение
% элемента с вершиной дерева
tree_member(X, tree(Y, Left, Right ) ): - tree_member(X, Left ).
tree_member(X, tree(Y, Left, Right ) ): - tree_member(X, Right ).
% рекурсивные предложения, осуществляющие проверку
% принадлежности элемента левому и правому поддеревьям
Типичные операции над деревьями :
- проверка принадлежности дереву;
- сравнение деревьев;
- обходы бинарного дерева (сверху вниз, слева направо, снизу вверх).
2.ГРАФЫ
Графы используются во многих приложениях, например, для представления отношений, ситуаций или структур задач. Граф определяется, как множество вершин вместе с множеством ребер. Если ребра направлены, то их также называют дугами. Дуги задаются упорядоченными парами. Такие графы называются направленными. Ребрам можно приписывать веса, имена или метки произвольного вида, в зависимости от конкретного приложения.
На рис.2 изображены два графа:
b
t
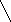
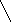

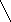
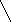


a
c
s
v
u
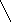
d
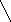
Рис.2: a – граф, б - направленный граф. Каждой дуге приписан ее вес.
В Прологе графы можно представить различными способами. Один из них – каждое ребро записывать в виде предложения. Например, графы, показанные на рис.2, можно представить в виде следующего фактов:
|
1inc(a,b). linc(b,c). linc(c,d). linc(b,d).
|
edge(s,t,3). edge(t,v,1). edge(t,u,5). edge(u,t,2). edge(v,u,2). |
Другой способ - весь граф представить как один объект. Для этого используем функтор ГРАФ, элементами которого являются два множества: множество вершин и множество ребер, тогда ненаправленный граф примет вид:
G1=ГРАФ1([а, b, с, d], [linc(а, b), linc(b, d), linc(b, с), linc(с, d ) ) ).
Направленный граф представляется в виде:
G2= ГРАФ2([s, t, u, v], [edge(s, t, 3), edge(t, v, 1), edge(t, u, 5), edge(u, t, 2), edge(v, u, 2) ] )
Еще один способ представления графа - связать с каждой вершиной список смежных с ней вершин:
G1=[sv(a, [b]), sv (b, [a, c, d]), sv (c, [b, d]), sv (d, [b, c] )]
G2=[sv (s, [p (t, 3)] ), sv (t, [p(u, 5), p(v, 1)] ), sv (u, [p( t, 2)] ), sv (v,[p( u, 2)] )]
Какой из способов представления окажется более удобным – зависит от конкретного приложения, а также от того, какие операции необходимо выполнять на графе.
Типичные операции на графах:
1) найти путь между двумя заданными вершинами;
2) найти подграф, обладающий некоторыми заданными свойствами.
В Прологе имеется единственный системный предикат - отсечение, влияющий на процедурное поведение программы. В тексте этот предикат обозначается символом - "!". Основное назначение этого предиката состоит в ограничении пространства поиска при вычислениях за счет динамического сокращения дерева поиска.
Смысл отсечения можно рассмотреть на предложении общего вида:
Y : - D1 , D2 ,…, Dk , ! , Dk+2 , …, Dm .
Будем считать, что предложение активизировалось, когда некоторая цель G сопоставилась с Y и цели D1,…, Dk выполнились. Выполнение отсечения приведет к следующему результату:
1. Текущее решение D1,…, Dk фиксируется, и все возможные оставшиеся альтернативы больше не рассматриваются.
2. Если некоторое Di при i>k не выполняется, то возврат происходит не далее чем к моменту отсечения.
3. Отсечение не влияет на цели, расположенные правее его.
4. Если процесс возврата фактически привел к предикату отсечения, то отсечение становится невыполненным и процесс поиска возвращается к последнему выбору, сделанному перед сопоставлением цели G предложения Y.
Отсечение считается "зеленым", если оно не влияет на значение программы, то есть множество решений, получаемых в программе без отсечений, совпадает с множеством решений, получаемых в этой программе с добавлением предиката -"!". Зеленые отсечения лишь отбрасывают те пути вычисления, которые не приводят к новым решениям.
Отсечения, не являющиеся зелеными, называются красными.
Существуют ограничения в применении отсечения: его применение может нарушить соответствие между декларативным и процедурным смыслами программы. Поэтому хороший стиль программирования предполагает осторожное применение отсечений и отказ от их применения без достаточных оснований.
ЗАМЕЧАНИЕ. Выполнив экспериментальную часть лабораторной работы, вы более четко будете представлять механизм действия предиката отсечение.
Задания для исследования
1. Проверка принадлежности дереву [1, программа 3.24, с.55);
2. Сравнение деревьев с точностью до изоморфизма [1, программа 3.25, с.56];
3. Подстановка терма в дерево [1, программа 3.26, с.56];
4. Обход бинарного дерева [1, программа 3.27, с.57];
- сверху вниз;
- слева направо;
- снизу вверх.
5. Распознавание многочленов [1, программа 3.28, с.58];
6. Правила дифференцирования [1, программа 3.29, с.58];
7. Выполнимость булевых формул [1, программа 3.31, с.61];
8. Поиск элемента в двоичном справочнике [2, программа 9.7. с.283];
9. Поиск в графе ациклического пути из одной вершины в другую [2, программа 9.20, с.298].