

18 Сжатие и распаковка информации по методу Хаффмана.
Метод Хаффмана предусматривает генерацию бинарных последовательностей на основе дерева алфавита, которое составляют попарные объединения виртуальных символов, образующие узлы дерева. Причем две ветви, образующие узел, обозначаются соответственно 1 и 0. Созданный узел образует виртуальный символ алфавита с вероятностью появления, равной сумме вероятностей, образующих узел, в дальнейшем этот узел может участвовать в создании нового. Объединение символов начинается с двух символов с наименьшими вероятностями. Структурно дерево имеет вид иерархию. Последний узел называется корнем. Стремиться нужно к тому, чтобы на каждой ветви узлы создавали символы с примерно одинаковыми вероятностями. Бинарный код каждого символа исходного алфавита создают обозначения ветвей дерева при их обходе от корня дерева к данному символу.
Прямое преобразование заключается в замене каждого символа соответствующим бинарным кодом.
Обратное преобразование наоборот, т.е. компрессор и декомпрессор должны пользоваться одинаковой таблицей код-символ и наоборот. Т. е. процедура сжатия и распаковки такая же, как и у метода Шеннона-Фано
|
|
Сортировка |
|
|
|
|
|
=0,3 =0,54 |
|
|
|
|
|
=0,2 корень дерева дерева 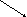 |
|
|
|
|
|
=0,14 =0,46 |
|
|
|
|
|
=0,26 |
|
|
узел (а10,а8) – виртуальный символ виртуальный символ =0,12 |
|
|
=0,07  |

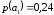
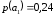

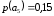

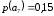
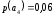
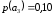

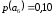

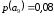
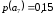
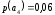
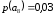
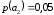
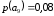
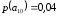

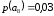
Формально можно выделить 4 уровня иерархии.
|
|
|
|
|
|
|
|
|
|
|
|
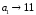
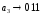
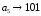
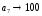
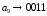
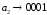
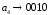

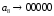
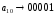
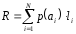 Сформированные
бинарные коды должны отвечать следующим
условиям:
1) все коды должны быть уникальными; 2)
должно выполняться свойство префикса:
ни один код меньшей длины не может быть
началом кода большей длины. Могут сущ-ть
разл. варианты объед. символов в пары.
Наилучший вариант – когда ему соответствует
минимальное значение интегрального
коэффициента R:
[bit],
li
– длина бинарного кода для i-того
символа.
Сформированные
бинарные коды должны отвечать следующим
условиям:
1) все коды должны быть уникальными; 2)
должно выполняться свойство префикса:
ни один код меньшей длины не может быть
началом кода большей длины. Могут сущ-ть
разл. варианты объед. символов в пары.
Наилучший вариант – когда ему соответствует
минимальное значение интегрального
коэффициента R:
[bit],
li
– длина бинарного кода для i-того
символа.
19 Сущность символ-ориентированных методов сжатия
Сущность состоит в последовательном анализе сжим. информации с целью поиска повторяющихся или проаналированных ранее в данном документе послед-тей и замене таких послед-тей на более короткие. Методы, основанные на данном подходе, не рассматривают статистические модели, они также не используют коды переменной длины. Вместо этого они выбирают некоторые последовательности символов, сохраняют их в словаре, а все последовательности кодируются в виде меток, используя словарь. Словарь может быть:
– статический– является постоянным. Иногда в него добавляют новые последовательности, но никогда не удаляют.
– динамический (адаптивный) содержит последовательности, ранее поступившие из входного файла, при этом разрешается и добавление, и удаление данных из словаря по мере чтения входного файла.
Таблицу кодов ASCII (американский кодовый стандарт для обмена информацией), в кототой 1 символ исходного алфавита всегда представляется 1 байтом двоичных символов, можно рассматривать как 1 из методов сжатия. Здесь таблица может выступать как своеобразный словарь. Он является полным и исчерпывающим. Но на практике в словарь помещается наиболее часто встречающиеся слова и выражения. В общем случае словарь может содержать произвольное число комбинаций произвольной длины. Основной вопрос - размер словаря.
При построении словаря исходят из следующих комментариев: 1) требуемая скорость кодирования комбинаций (сжатия) и скорость обратного преобразования: чем больше словарь, тем ниже скорость; 2) размеры требуемой памяти: чем больше словарь, тем больше размер требуемой памяти для хранения словаря; 3) эффективность сжатия в первом приближения можно оценить параметром С (интегральный коэффициень). Наилучшим является подход, при котором словарь строится под тип данных.
Важнейшая проблема при проектировании словарной схемы — выбор размерного кодового словаря. В связи с этим часто ограничение накладываются на размер фраз, помещённых в словарь. Относительно размера фраз составление словаря может быть статистическим, полуадаптивнм и адаптивным. Способ разбиения текста на фразы для их дальнейшего кодирования называется разбором текста. Статистический (неизменный) словарь строится предварительно для разнообразных типов документов и практически не изменяется. Полуадаптивный алгоритм предполагает создание словаря под конкретный тип документа. Адаптивный алгоритм строит словарь под каждый документ. Важнейшая особенность адаптивного (и в определённой степени - полуадаптивного) словаря - необходимость его передачи вместе со сжатой информацией.